 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sequential Latent Variable Models from Multimodal Time Series Data
Paper and Code
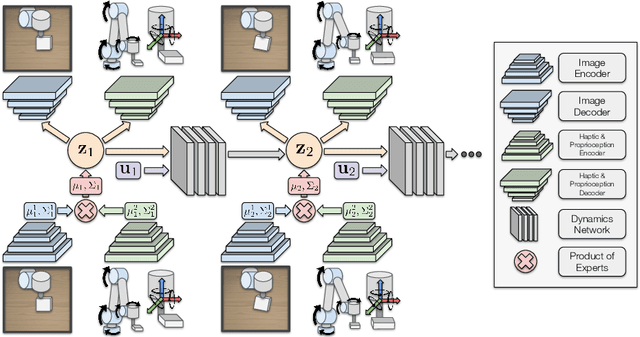

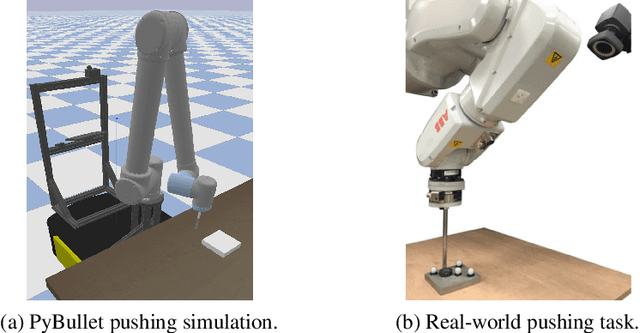

Sequential modelling of high-dimensional data is an important problem that appears in many domains including model-based reinforcement learning and dynamics identification for control. Latent variable models applied to sequential data (i.e., latent dynamics models) have been shown to be a particularly effective probabilistic approach to solve this problem, especially when dealing with images. However, in many application areas (e.g., robotics), information from multiple sensing modalities is available -- existing latent dynamics methods have not yet been extended to effectively make use of such multimodal sequential data. Multimodal sensor streams can be correlated in a useful manner and often contain complementary information across modalities. In this work, we present a self-supervised generative modelling framework to jointly learn a probabilistic latent state representation of multimodal data and the respective dynamics. Using synthetic and real-world datasets from a multimodal robotic planar pushing task, we demonstrate that our approach leads to significant improvements in prediction and representation quality. Furthermore, we compare to the common learning baseline of concatenating each modality in the latent space and show that our principled probabilistic formulation performs better. Finally, despite being fully self-supervised, we demonstrate that our method is nearly as effective as an existing supervised approach that relies on ground truth labels.