 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Self-Supervised Pre-Training of Point Cloud Segmentation Networks With Image Data
Jan 18, 2023



Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is particularly important for semantic segmentation tasks involving 3D datasets, which are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on unlabelled data is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point clouds exclusively. While useful, this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene and can be applied to cases where localization information is unavailable. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
Self-Supervised Pre-training of 3D Point Cloud Networks with Image Data
Dec 13, 2022


Reducing the quantity of annotations required for supervised training is vital when labels are scarce and costly. This reduction is especially important for semantic segmentation tasks involving 3D datasets that are often significantly smaller and more challenging to annotate than their image-based counterparts. Self-supervised pre-training on large unlabelled datasets is one way to reduce the amount of manual annotations needed. Previous work has focused on pre-training with point cloud data exclusively; this approach often requires two or more registered views. In the present work, we combine image and point cloud modalities, by first learning self-supervised image features and then using these features to train a 3D model. By incorporating image data, which is often included in many 3D datasets, our pre-training method only requires a single scan of a scene. We demonstrate that our pre-training approach, despite using single scans, achieves comparable performance to other multi-scan, point cloud-only methods.
Pushing the Limits of Non-Autoregressive Speech Recognition
Apr 12, 2021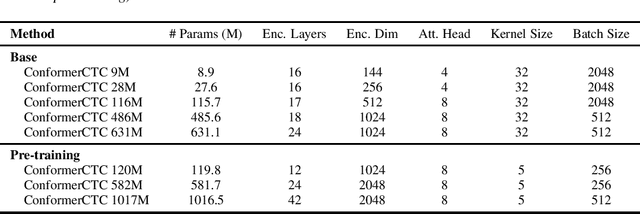
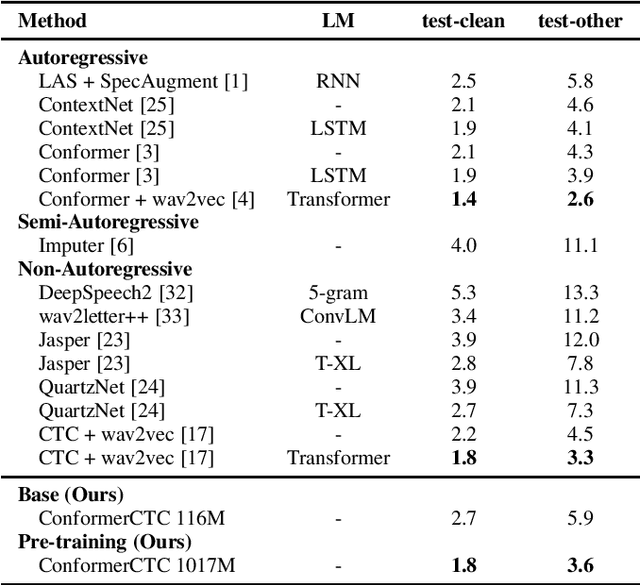
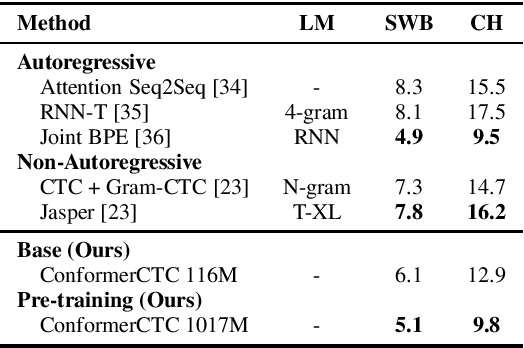
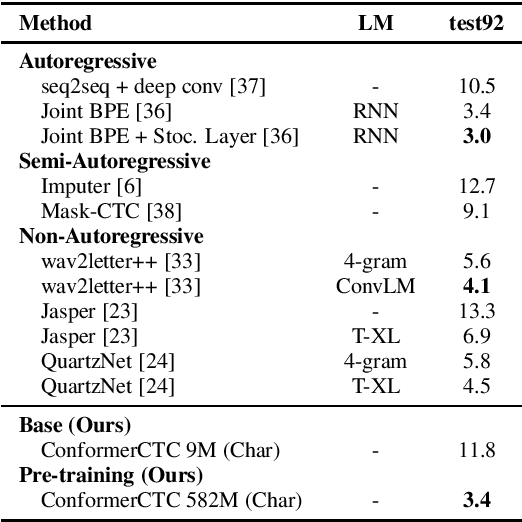
We combine recent advancements in end-to-end speech recognition to non-autoregressive automatic speech recognition. We push the limits of non-autoregressive state-of-the-art results for multiple datasets: LibriSpeech, Fisher+Switchboard and Wall Street Journal. Key to our recipe, we leverage CTC on giant Conformer neural network architectures with SpecAugment and wav2vec2 pre-training. We achieve 1.8%/3.6% WER on LibriSpeech test/test-other sets, 5.1%/9.8% WER on Switchboard, and 3.4% on the Wall Street Journal, all without a language model.
Understanding Guided Image Captioning Performance across Domains
Dec 04, 2020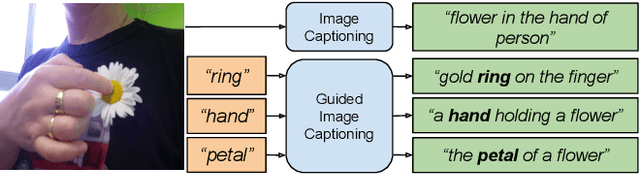

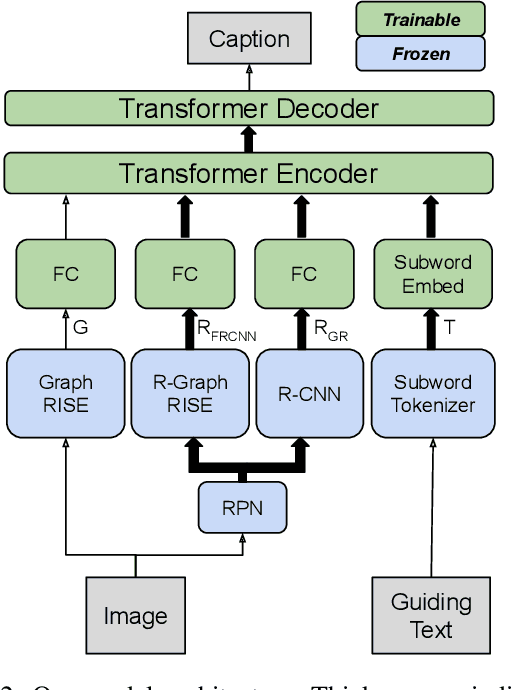
Image captioning models generally lack the capability to take into account user interest, and usually default to global descriptions that try to balance readability, informativeness, and information overload. On the other hand, VQA models generally lack the ability to provide long descriptive answers, while expecting the textual question to be quite precise. We present a method to control the concepts that an image caption should focus on, using an additional input called the guiding text that refers to either groundable or ungroundable concepts in the image. Our model consists of a Transformer-based multimodal encoder that uses the guiding text together with global and object-level image features to derive early-fusion representations used to generate the guided caption. While models trained on Visual Genome data have an in-domain advantage of fitting well when guided with automatic object labels, we find that guided captioning models trained on Conceptual Captions generalize better on out-of-domain images and guiding texts. Our human-evaluation results indicate that attempting in-the-wild guided image captioning requires access to large, unrestricted-domain training datasets, and that increased style diversity (even without increasing vocabulary size) is a key factor for improved performance.