Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Non-Autoregressive Speech Recognition
Paper and Code
Apr 12, 2021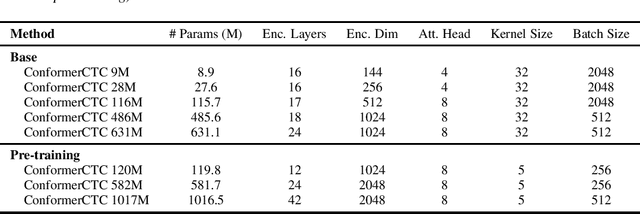
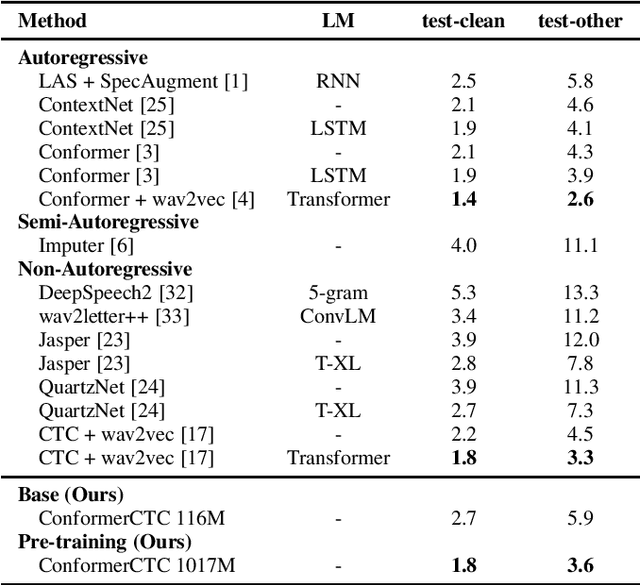
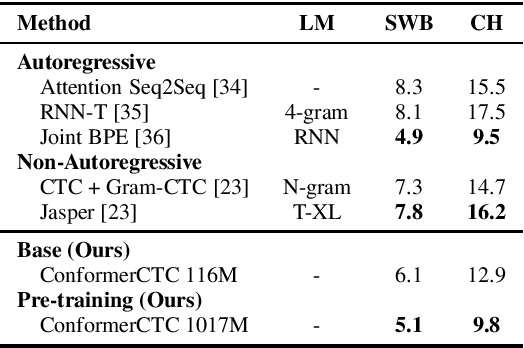
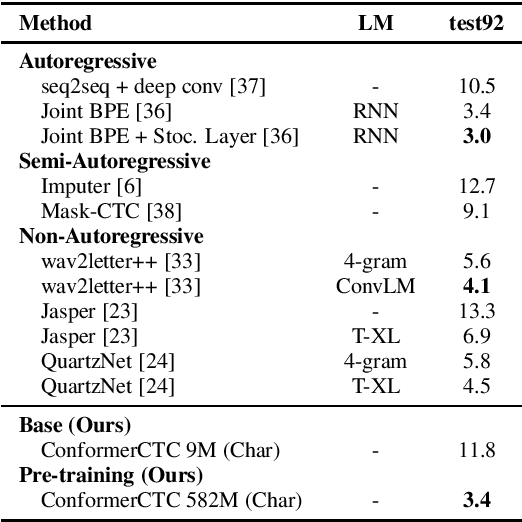
We combine recent advancements in end-to-end speech recognition to non-autoregressive automatic speech recognition. We push the limits of non-autoregressive state-of-the-art results for multiple datasets: LibriSpeech, Fisher+Switchboard and Wall Street Journal. Key to our recipe, we leverage CTC on giant Conformer neural network architectures with SpecAugment and wav2vec2 pre-training. We achieve 1.8%/3.6% WER on LibriSpeech test/test-other sets, 5.1%/9.8% WER on Switchboard, and 3.4% on the Wall Street Journal, all without a language model.
* Submitted to Interspeech 2021
View paper on