 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDICTDIS: Dictionary Constrained Disambiguation for Improved NMT
Oct 13, 2022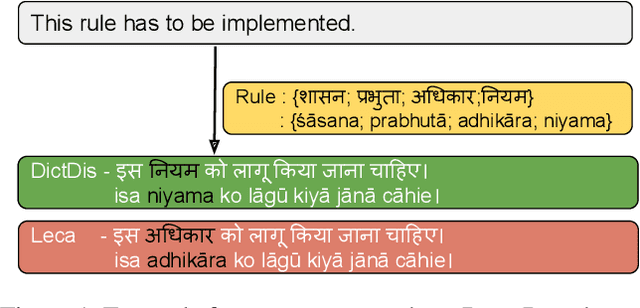
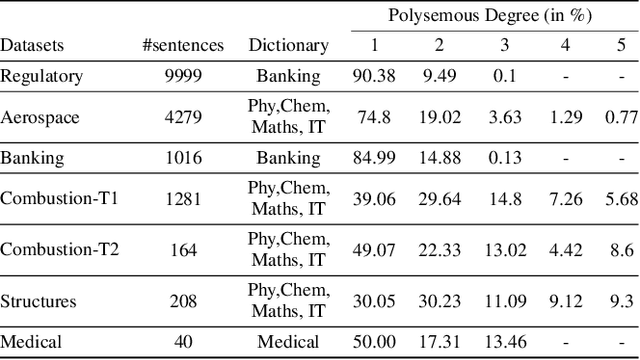
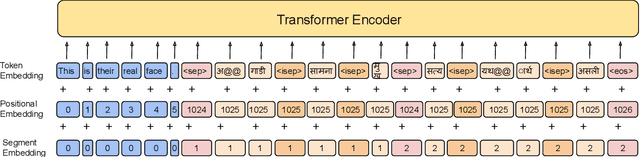

Domain-specific neural machine translation (NMT) systems (e.g., in educational applications) are socially significant with the potential to help make information accessible to a diverse set of users in multilingual societies. It is desirable that such NMT systems be lexically constrained and draw from domain-specific dictionaries. Dictionaries could present multiple candidate translations for a source words/phrases on account of the polysemous nature of words. The onus is then on the NMT model to choose the contextually most appropriate candidate. Prior work has largely ignored this problem and focused on the single candidate setting where the target word or phrase is replaced by a single constraint. In this work we present DICTDIS, a lexically constrained NMT system that disambiguates between multiple candidate translations derived from dictionaries. We achieve this by augmenting training data with multiple dictionary candidates to actively encourage disambiguation during training. We demonstrate the utility of DICTDIS via extensive experiments on English-Hindi sentences in a variety of domains including news, finance, medicine and engineering. We obtain superior disambiguation performance on all domains with improved fluency in some domains of up to 4 BLEU points, when compared with existing approaches for lexically constrained and unconstrained NMT.
COSMic: A Coherence-Aware Generation Metric for Image Descriptions
Sep 11, 2021
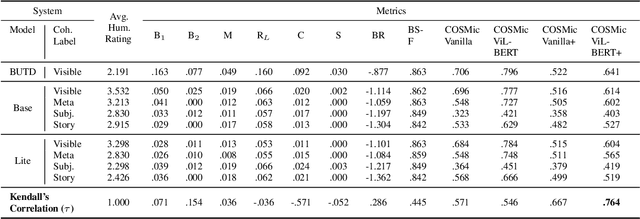

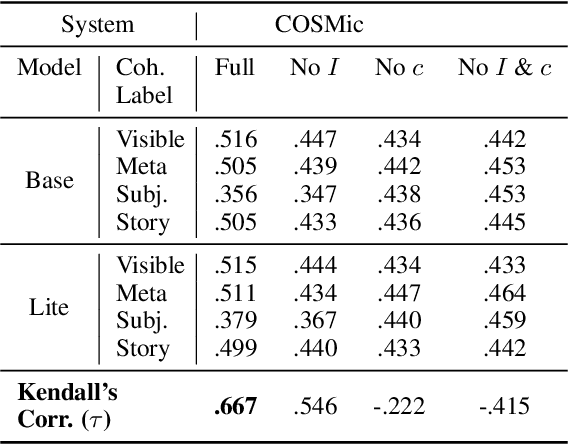
Developers of text generation models rely on automated evaluation metrics as a stand-in for slow and expensive manual evaluations. However, image captioning metrics have struggled to give accurate learned estimates of the semantic and pragmatic success of output text. We address this weakness by introducing the first discourse-aware learned generation metric for evaluating image descriptions. Our approach is inspired by computational theories of discourse for capturing information goals using coherence. We present a dataset of image$\unicode{x2013}$description pairs annotated with coherence relations. We then train a coherence-aware metric on a subset of the Conceptual Captions dataset and measure its effectiveness$\unicode{x2014}$its ability to predict human ratings of output captions$\unicode{x2014}$on a test set composed of out-of-domain images. We demonstrate a higher Kendall Correlation Coefficient for our proposed metric with the human judgments for the results of a number of state-of-the-art coherence-aware caption generation models when compared to several other metrics including recently proposed learned metrics such as BLEURT and BERTScore.
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
Feb 17, 2021
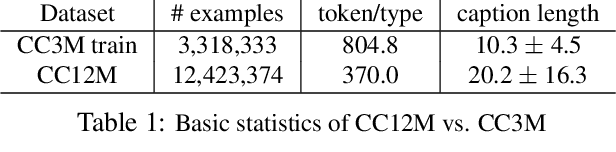

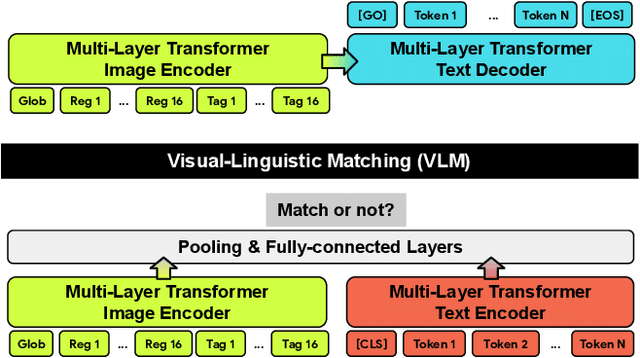
The availability of large-scale image captioning and visual question answering datasets has contributed significantly to recent successes in vision-and-language pre-training. However, these datasets are often collected with overrestrictive requirements, inherited from their original target tasks (e.g., image caption generation), which limit the resulting dataset scale and diversity. We take a step further in pushing the limits of vision-and-language pre-training data by relaxing the data collection pipeline used in Conceptual Captions 3M (CC3M) [Sharma et al. 2018] and introduce the Conceptual 12M (CC12M), a dataset with 12 million image-text pairs specifically meant to be used for vision-and-language pre-training. We perform an analysis of this dataset, as well as benchmark its effectiveness against CC3M on multiple downstream tasks with an emphasis on long-tail visual recognition. The quantitative and qualitative results clearly illustrate the benefit of scaling up pre-training data for vision-and-language tasks, as indicated by the new state-of-the-art results on both the nocaps and Conceptual Captions benchmarks.
Understanding Guided Image Captioning Performance across Domains
Dec 04, 2020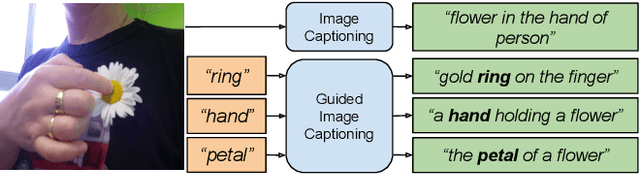

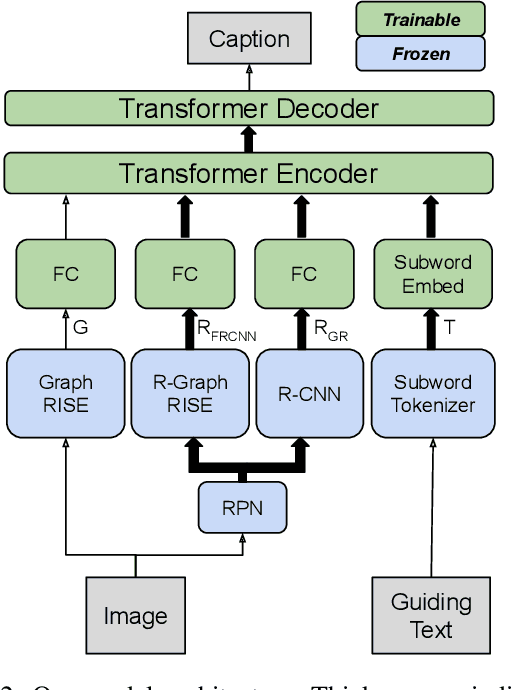
Image captioning models generally lack the capability to take into account user interest, and usually default to global descriptions that try to balance readability, informativeness, and information overload. On the other hand, VQA models generally lack the ability to provide long descriptive answers, while expecting the textual question to be quite precise. We present a method to control the concepts that an image caption should focus on, using an additional input called the guiding text that refers to either groundable or ungroundable concepts in the image. Our model consists of a Transformer-based multimodal encoder that uses the guiding text together with global and object-level image features to derive early-fusion representations used to generate the guided caption. While models trained on Visual Genome data have an in-domain advantage of fitting well when guided with automatic object labels, we find that guided captioning models trained on Conceptual Captions generalize better on out-of-domain images and guiding texts. Our human-evaluation results indicate that attempting in-the-wild guided image captioning requires access to large, unrestricted-domain training datasets, and that increased style diversity (even without increasing vocabulary size) is a key factor for improved performance.
Weakly Supervised Content Selection for Improved Image Captioning
Sep 10, 2020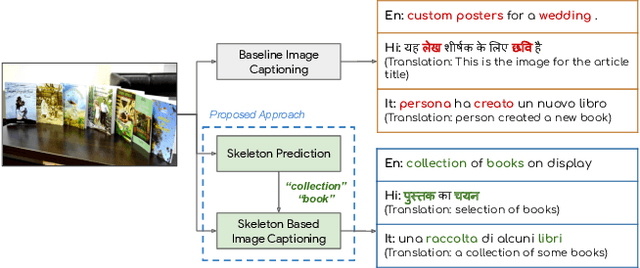
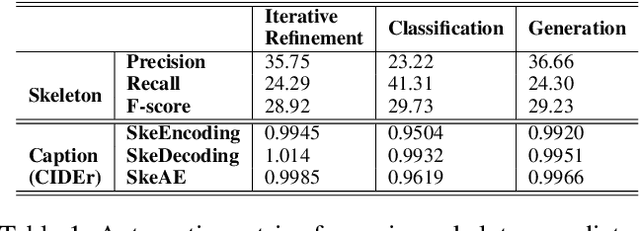
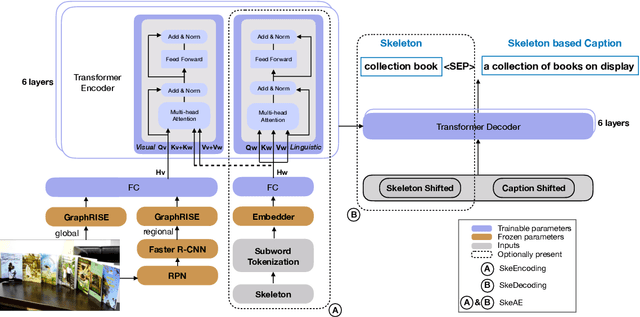
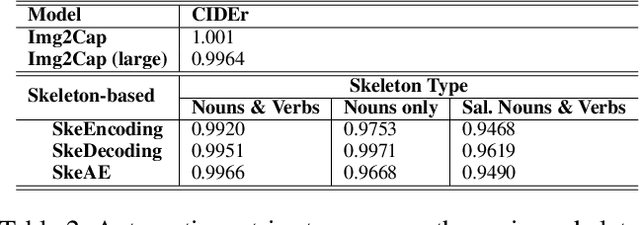
Image captioning involves identifying semantic concepts in the scene and describing them in fluent natural language. Recent approaches do not explicitly model the semantic concepts and train the model only for the end goal of caption generation. Such models lack interpretability and controllability, primarily due to sub-optimal content selection. We address this problem by breaking down the captioning task into two simpler, manageable and more controllable tasks -- skeleton prediction and skeleton-based caption generation. We approach the former as a weakly supervised task, using a simple off-the-shelf language syntax parser and avoiding the need for additional human annotations; the latter uses a supervised-learning approach. We investigate three methods of conditioning the caption on skeleton in the encoder, decoder and both. Our compositional model generates significantly better quality captions on out of domain test images, as judged by human annotators. Additionally, we demonstrate the cross-language effectiveness of the English skeleton to other languages including French, Italian, German, Spanish and Hindi. This compositional nature of captioning exhibits the potential of unpaired image captioning, thereby reducing the dependence on expensive image-caption pairs. Furthermore, we investigate the use of skeletons as a knob to control certain properties of the generated image caption, such as length, content, and gender expression.
Clue: Cross-modal Coherence Modeling for Caption Generation
May 02, 2020


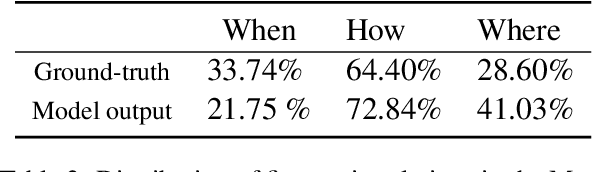
We use coherence relations inspired by computational models of discourse to study the information needs and goals of image captioning. Using an annotation protocol specifically devised for capturing image--caption coherence relations, we annotate 10,000 instances from publicly-available image--caption pairs. We introduce a new task for learning inferences in imagery and text, coherence relation prediction, and show that these coherence annotations can be exploited to learn relation classifiers as an intermediary step, and also train coherence-aware, controllable image captioning models. The results show a dramatic improvement in the consistency and quality of the generated captions with respect to information needs specified via coherence relations.
Reinforcing an Image Caption Generator Using Off-Line Human Feedback
Nov 21, 2019

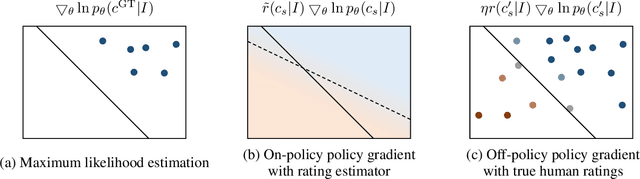
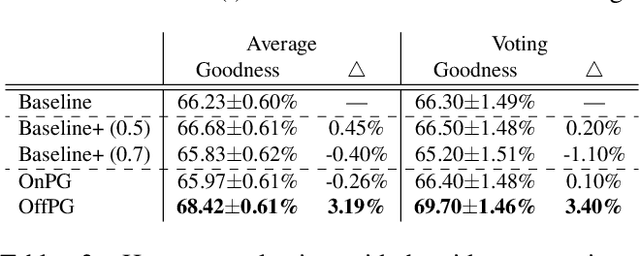
Human ratings are currently the most accurate way to assess the quality of an image captioning model, yet most often the only used outcome of an expensive human rating evaluation is a few overall statistics over the evaluation dataset. In this paper, we show that the signal from instance-level human caption ratings can be leveraged to improve captioning models, even when the amount of caption ratings is several orders of magnitude less than the caption training data. We employ a policy gradient method to maximize the human ratings as rewards in an off-policy reinforcement learning setting, where policy gradients are estimated by samples from a distribution that focuses on the captions in a caption ratings dataset. Our empirical evidence indicates that the proposed method learns to generalize the human raters' judgments to a previously unseen set of images, as judged by a different set of human judges, and additionally on a different, multi-dimensional side-by-side human evaluation procedure.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Oct 30, 2019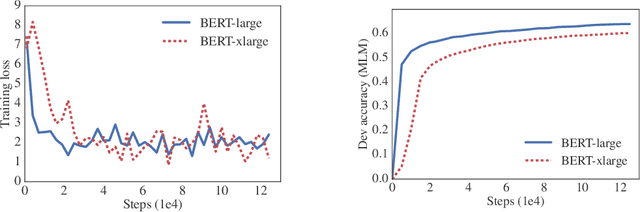

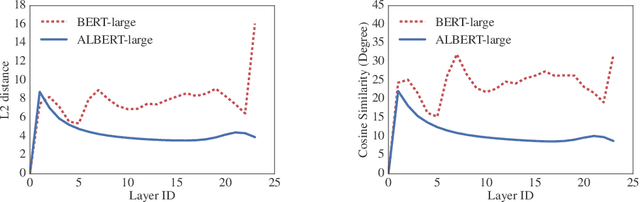

Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations, longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows that our proposed methods lead to models that scale much better compared to the original BERT. We also use a self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and SQuAD benchmarks while having fewer parameters compared to BERT-large.The code and the pretrained models are available at https://github.com/google-research/google-research/tree/master/albert.
Neural Naturalist: Generating Fine-Grained Image Comparisons
Sep 20, 2019
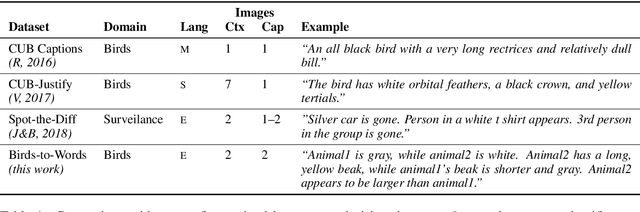
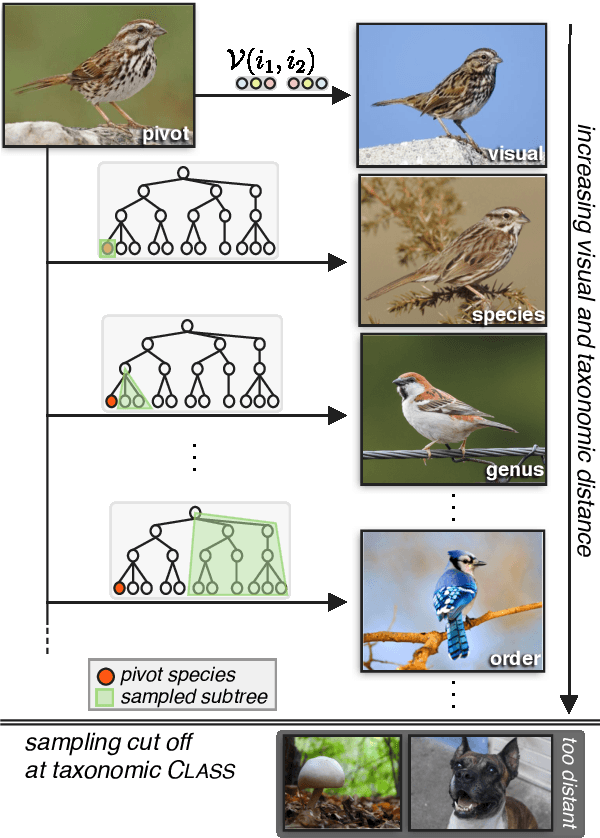
We introduce the new Birds-to-Words dataset of 41k sentences describing fine-grained differences between photographs of birds. The language collected is highly detailed, while remaining understandable to the everyday observer (e.g., "heart-shaped face," "squat body"). Paragraph-length descriptions naturally adapt to varying levels of taxonomic and visual distance---drawn from a novel stratified sampling approach---with the appropriate level of detail. We propose a new model called Neural Naturalist that uses a joint image encoding and comparative module to generate comparative language, and evaluate the results with humans who must use the descriptions to distinguish real images. Our results indicate promising potential for neural models to explain differences in visual embedding space using natural language, as well as a concrete path for machine learning to aid citizen scientists in their effort to preserve biodiversity.
Quality Estimation for Image Captions Based on Large-scale Human Evaluations
Sep 08, 2019
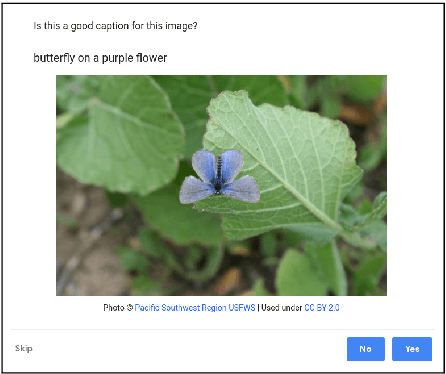
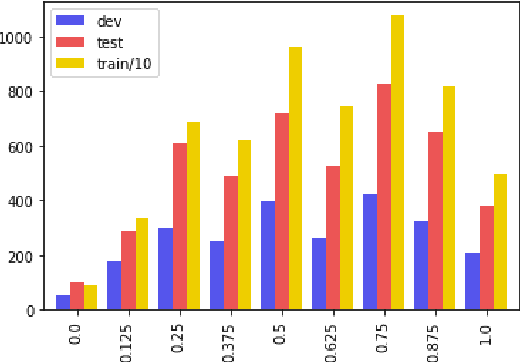

Automatic image captioning has improved significantly in the last few years, but the problem is far from being solved. Furthermore, while the standard automatic metrics, such as CIDEr and SPICE~\cite{cider,spice}, can be used for model selection, they cannot be used at inference-time given a previously unseen image since they require ground-truth references. In this paper, we focus on the related problem called Quality Estimation (QE) of image-captions. In contrast to automatic metrics, QE attempts to model caption quality without relying on ground-truth references. It can thus be applied as a second-pass model (after caption generation) to estimate the quality of captions even for previously unseen images. We conduct a large-scale human evaluation experiment, in which we collect a new dataset of more than 600k ratings of image-caption pairs. Using this dataset, we design and experiment with several QE modeling approaches and provide an analysis of their performance. Our results show that QE is feasible for image captioning.