 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Content Selection for Improved Image Captioning
Paper and Code
Sep 10, 2020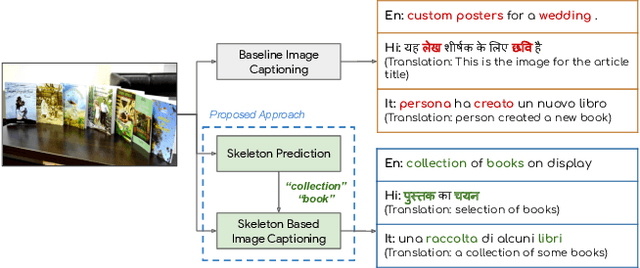
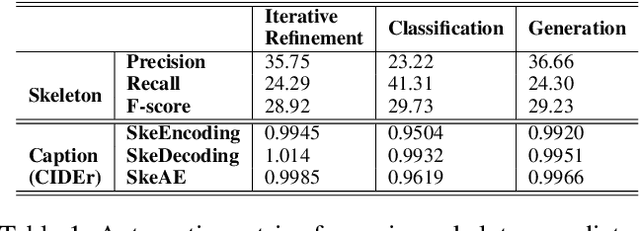
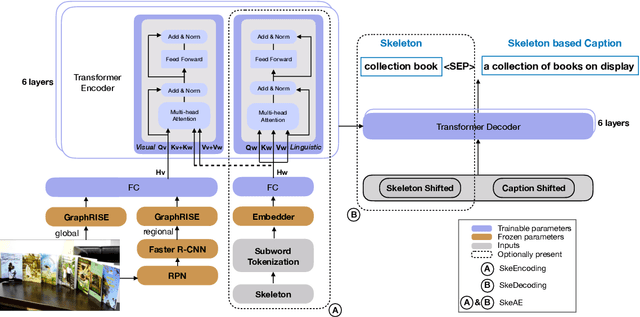
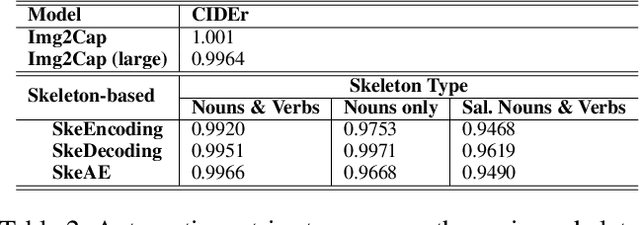
Image captioning involves identifying semantic concepts in the scene and describing them in fluent natural language. Recent approaches do not explicitly model the semantic concepts and train the model only for the end goal of caption generation. Such models lack interpretability and controllability, primarily due to sub-optimal content selection. We address this problem by breaking down the captioning task into two simpler, manageable and more controllable tasks -- skeleton prediction and skeleton-based caption generation. We approach the former as a weakly supervised task, using a simple off-the-shelf language syntax parser and avoiding the need for additional human annotations; the latter uses a supervised-learning approach. We investigate three methods of conditioning the caption on skeleton in the encoder, decoder and both. Our compositional model generates significantly better quality captions on out of domain test images, as judged by human annotators. Additionally, we demonstrate the cross-language effectiveness of the English skeleton to other languages including French, Italian, German, Spanish and Hindi. This compositional nature of captioning exhibits the potential of unpaired image captioning, thereby reducing the dependence on expensive image-caption pairs. Furthermore, we investigate the use of skeletons as a knob to control certain properties of the generated image caption, such as length, content, and gender expression.