 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022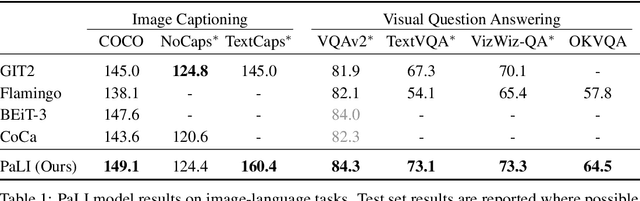

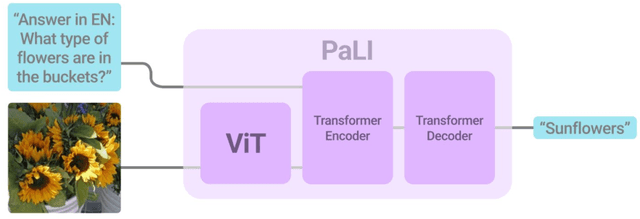

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
End-to-end Dense Video Captioning as Sequence Generation
Apr 18, 2022

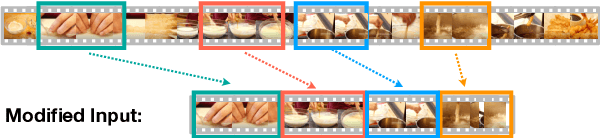
Dense video captioning aims to identify the events of interest in an input video, and generate descriptive captions for each event. Previous approaches usually follow a two-stage generative process, which first proposes a segment for each event, then renders a caption for each identified segment. Recent advances in large-scale sequence generation pretraining have seen great success in unifying task formulation for a great variety of tasks, but so far, more complex tasks such as dense video captioning are not able to fully utilize this powerful paradigm. In this work, we show how to model the two subtasks of dense video captioning jointly as one sequence generation task, and simultaneously predict the events and the corresponding descriptions. Experiments on YouCook2 and ViTT show encouraging results and indicate the feasibility of training complex tasks such as end-to-end dense video captioning integrated into large-scale pre-trained models.
Weakly Supervised Content Selection for Improved Image Captioning
Sep 10, 2020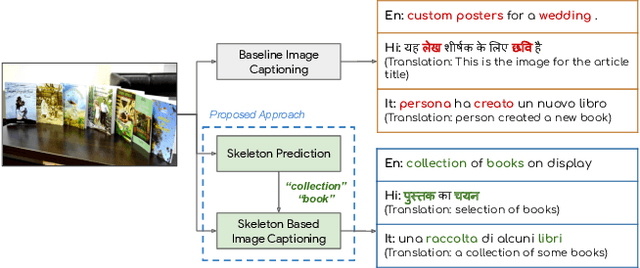
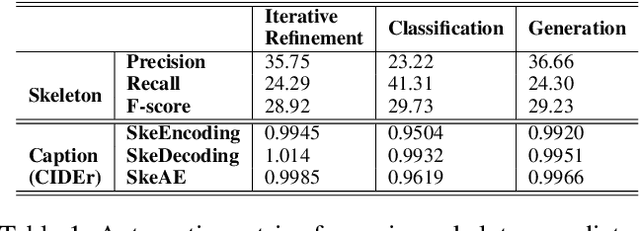
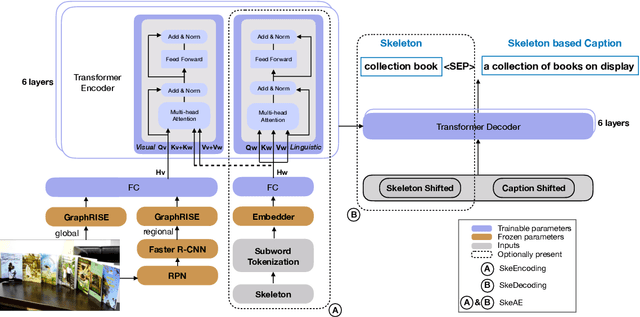
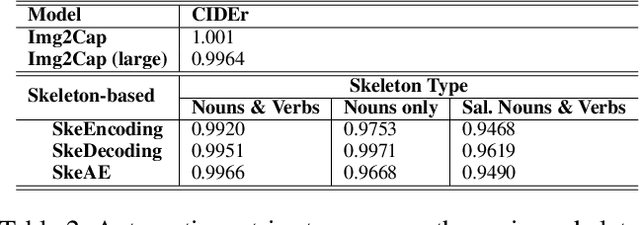
Image captioning involves identifying semantic concepts in the scene and describing them in fluent natural language. Recent approaches do not explicitly model the semantic concepts and train the model only for the end goal of caption generation. Such models lack interpretability and controllability, primarily due to sub-optimal content selection. We address this problem by breaking down the captioning task into two simpler, manageable and more controllable tasks -- skeleton prediction and skeleton-based caption generation. We approach the former as a weakly supervised task, using a simple off-the-shelf language syntax parser and avoiding the need for additional human annotations; the latter uses a supervised-learning approach. We investigate three methods of conditioning the caption on skeleton in the encoder, decoder and both. Our compositional model generates significantly better quality captions on out of domain test images, as judged by human annotators. Additionally, we demonstrate the cross-language effectiveness of the English skeleton to other languages including French, Italian, German, Spanish and Hindi. This compositional nature of captioning exhibits the potential of unpaired image captioning, thereby reducing the dependence on expensive image-caption pairs. Furthermore, we investigate the use of skeletons as a knob to control certain properties of the generated image caption, such as length, content, and gender expression.
Quality Estimation for Image Captions Based on Large-scale Human Evaluations
Sep 08, 2019
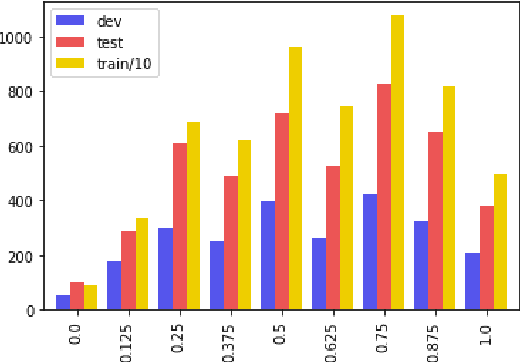

Automatic image captioning has improved significantly in the last few years, but the problem is far from being solved. Furthermore, while the standard automatic metrics, such as CIDEr and SPICE~\cite{cider,spice}, can be used for model selection, they cannot be used at inference-time given a previously unseen image since they require ground-truth references. In this paper, we focus on the related problem called Quality Estimation (QE) of image-captions. In contrast to automatic metrics, QE attempts to model caption quality without relying on ground-truth references. It can thus be applied as a second-pass model (after caption generation) to estimate the quality of captions even for previously unseen images. We conduct a large-scale human evaluation experiment, in which we collect a new dataset of more than 600k ratings of image-caption pairs. Using this dataset, we design and experiment with several QE modeling approaches and provide an analysis of their performance. Our results show that QE is feasible for image captioning.