 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Estimation for Image Captions Based on Large-scale Human Evaluations
Paper and Code

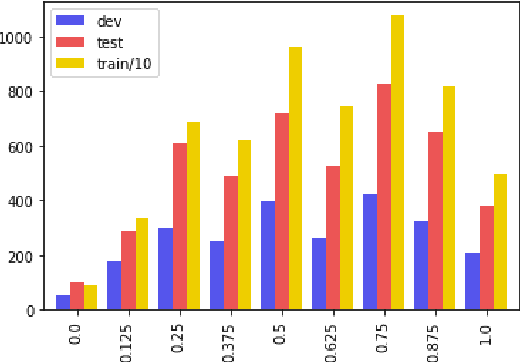

Automatic image captioning has improved significantly in the last few years, but the problem is far from being solved. Furthermore, while the standard automatic metrics, such as CIDEr and SPICE~\cite{cider,spice}, can be used for model selection, they cannot be used at inference-time given a previously unseen image since they require ground-truth references. In this paper, we focus on the related problem called Quality Estimation (QE) of image-captions. In contrast to automatic metrics, QE attempts to model caption quality without relying on ground-truth references. It can thus be applied as a second-pass model (after caption generation) to estimate the quality of captions even for previously unseen images. We conduct a large-scale human evaluation experiment, in which we collect a new dataset of more than 600k ratings of image-caption pairs. Using this dataset, we design and experiment with several QE modeling approaches and provide an analysis of their performance. Our results show that QE is feasible for image captioning.