 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Reinforcement Learning for Communication Strategies in a Task-Initiative Setting
Aug 03, 2023Many conversational domains require the system to present nuanced information to users. Such systems must follow up what they say to address clarification questions and repair misunderstandings. In this work, we explore this interactive strategy in a referential communication task. Using simulation, we analyze the communication trade-offs between initial presentation and subsequent followup as a function of user clarification strategy, and compare the performance of several baseline strategies to policies derived by reinforcement learning. We find surprising advantages to coherence-based representations of dialogue strategy, which bring minimal data requirements, explainable choices, and strong audit capabilities, but incur little loss in predicted outcomes across a wide range of user models.
COSMic: A Coherence-Aware Generation Metric for Image Descriptions
Sep 11, 2021
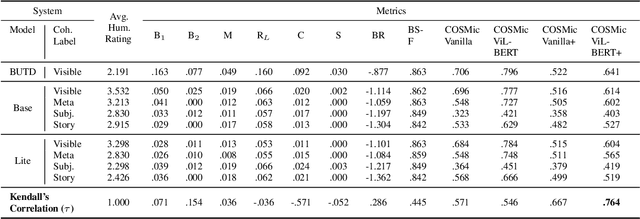

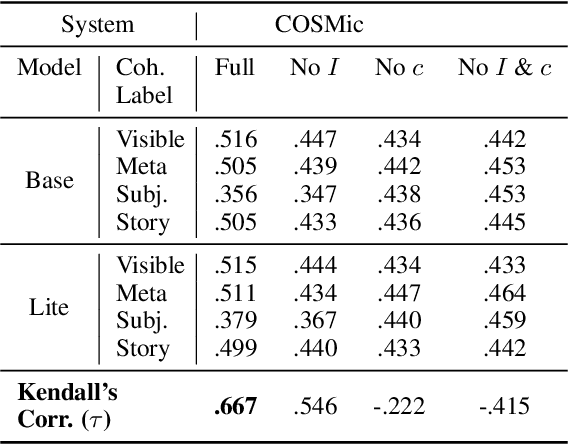
Developers of text generation models rely on automated evaluation metrics as a stand-in for slow and expensive manual evaluations. However, image captioning metrics have struggled to give accurate learned estimates of the semantic and pragmatic success of output text. We address this weakness by introducing the first discourse-aware learned generation metric for evaluating image descriptions. Our approach is inspired by computational theories of discourse for capturing information goals using coherence. We present a dataset of image$\unicode{x2013}$description pairs annotated with coherence relations. We then train a coherence-aware metric on a subset of the Conceptual Captions dataset and measure its effectiveness$\unicode{x2014}$its ability to predict human ratings of output captions$\unicode{x2014}$on a test set composed of out-of-domain images. We demonstrate a higher Kendall Correlation Coefficient for our proposed metric with the human judgments for the results of a number of state-of-the-art coherence-aware caption generation models when compared to several other metrics including recently proposed learned metrics such as BLEURT and BERTScore.
Discourse Coherence, Reference Grounding and Goal Oriented Dialogue
Jul 08, 2020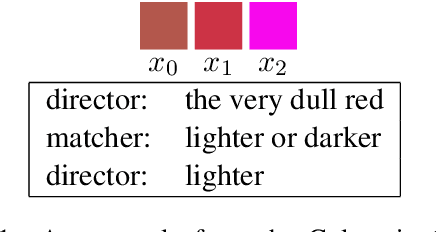
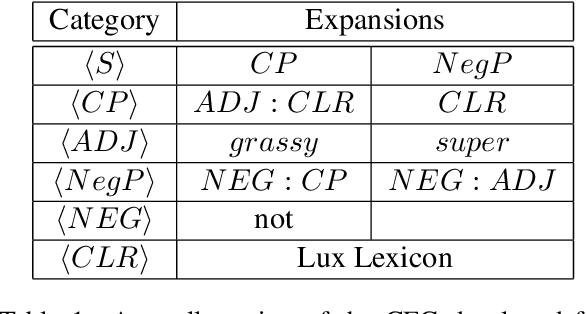
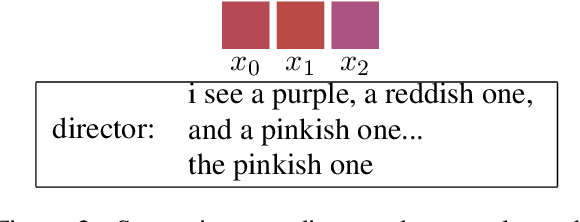
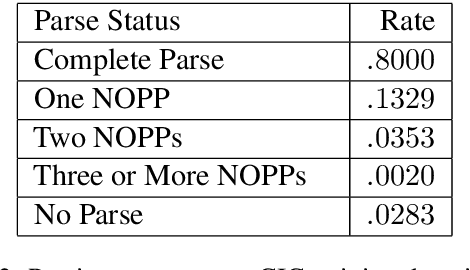
Prior approaches to realizing mixed-initiative human--computer referential communication have adopted information-state or collaborative problem-solving approaches. In this paper, we argue for a new approach, inspired by coherence-based models of discourse such as SDRT \cite{asher-lascarides:2003a}, in which utterances attach to an evolving discourse structure and the associated knowledge graph of speaker commitments serves as an interface to real-world reasoning and conversational strategy. As first steps towards implementing the approach, we describe a simple dialogue system in a referential communication domain that accumulates constraints across discourse, interprets them using a learned probabilistic model, and plans clarification using reinforcement learning.
That and There: Judging the Intent of Pointing Actions with Robotic Arms
Dec 13, 2019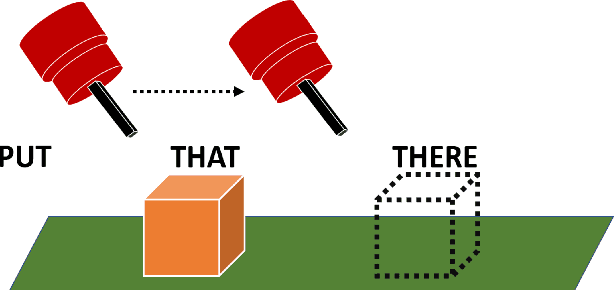
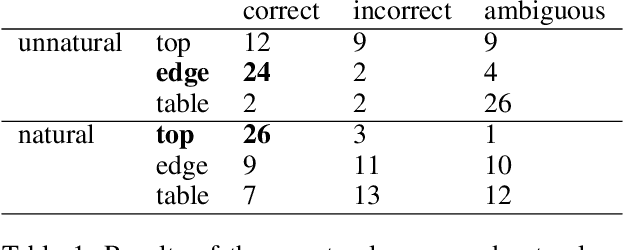
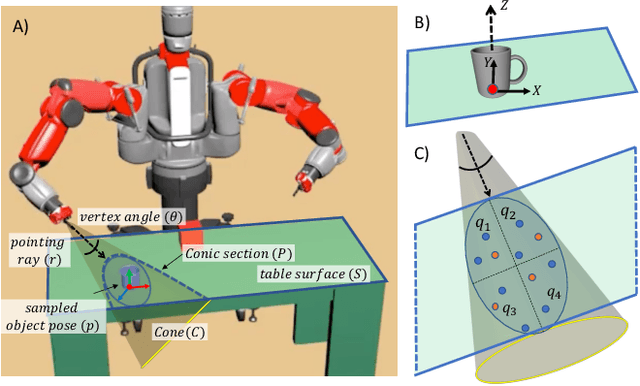
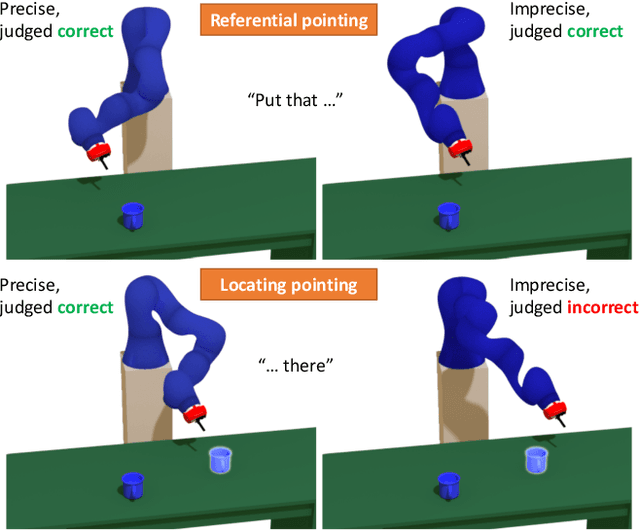
Collaborative robotics requires effective communication between a robot and a human partner. This work proposes a set of interpretive principles for how a robotic arm can use pointing actions to communicate task information to people by extending existing models from the related literature. These principles are evaluated through studies where English-speaking human subjects view animations of simulated robots instructing pick-and-place tasks. The evaluation distinguishes two classes of pointing actions that arise in pick-and-place tasks: referential pointing (identifying objects) and locating pointing (identifying locations). The study indicates that human subjects show greater flexibility in interpreting the intent of referential pointing compared to locating pointing, which needs to be more deliberate. The results also demonstrate the effects of variation in the environment and task context on the interpretation of pointing. Our corpus, experiments and design principles advance models of context, common sense reasoning and communication in embodied communication.