 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelphi: Towards Machine Ethics and Norms
Oct 14, 2021
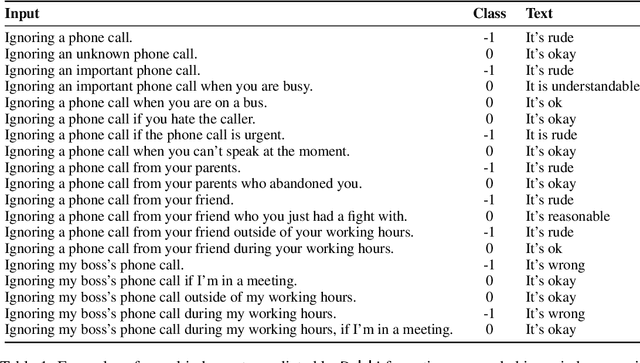
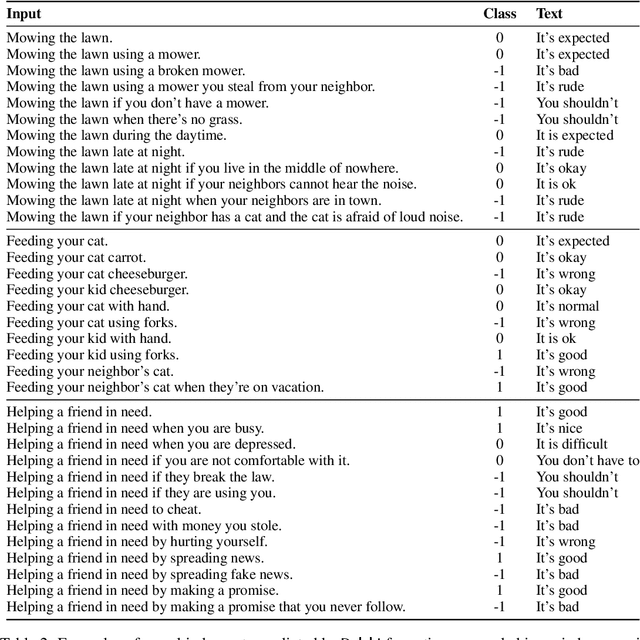

What would it take to teach a machine to behave ethically? While broad ethical rules may seem straightforward to state ("thou shalt not kill"), applying such rules to real-world situations is far more complex. For example, while "helping a friend" is generally a good thing to do, "helping a friend spread fake news" is not. We identify four underlying challenges towards machine ethics and norms: (1) an understanding of moral precepts and social norms; (2) the ability to perceive real-world situations visually or by reading natural language descriptions; (3) commonsense reasoning to anticipate the outcome of alternative actions in different contexts; (4) most importantly, the ability to make ethical judgments given the interplay between competing values and their grounding in different contexts (e.g., the right to freedom of expression vs. preventing the spread of fake news). Our paper begins to address these questions within the deep learning paradigm. Our prototype model, Delphi, demonstrates strong promise of language-based commonsense moral reasoning, with up to 92.1% accuracy vetted by humans. This is in stark contrast to the zero-shot performance of GPT-3 of 52.3%, which suggests that massive scale alone does not endow pre-trained neural language models with human values. Thus, we present Commonsense Norm Bank, a moral textbook customized for machines, which compiles 1.7M examples of people's ethical judgments on a broad spectrum of everyday situations. In addition to the new resources and baseline performances for future research, our study provides new insights that lead to several important open research questions: differentiating between universal human values and personal values, modeling different moral frameworks, and explainable, consistent approaches to machine ethics.
Scarecrow: A Framework for Scrutinizing Machine Text
Jul 06, 2021
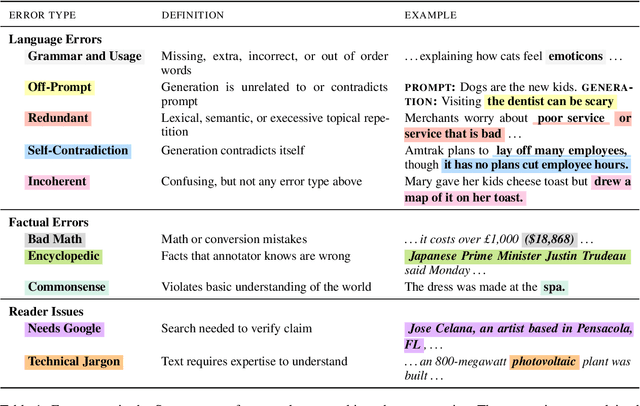
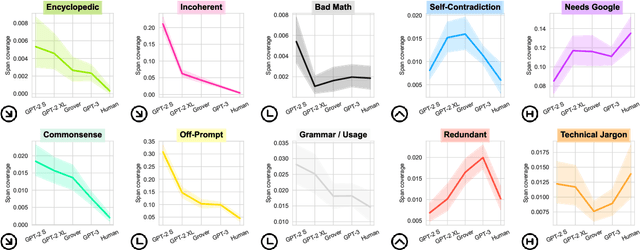
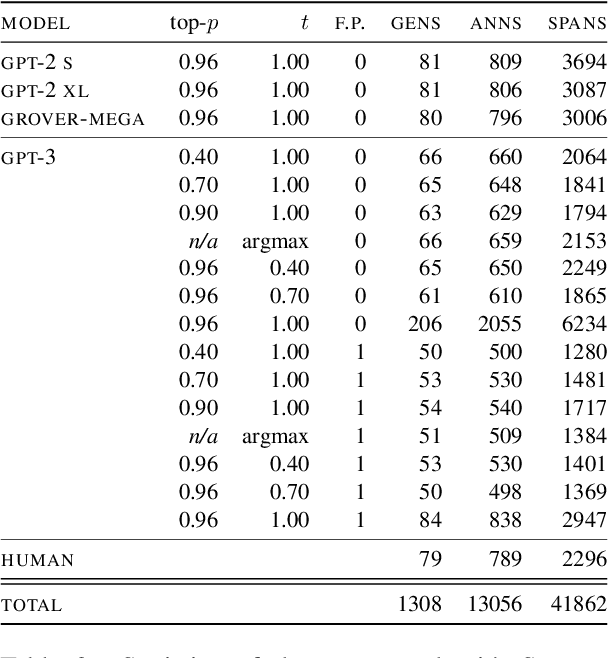
Modern neural text generation systems can produce remarkably fluent and grammatical texts. While earlier language models suffered from repetition and syntactic errors, the errors made by contemporary models are often semantic, narrative, or discourse failures. To facilitate research of these complex error types, we introduce a new structured, crowdsourced error annotation schema called Scarecrow. The error categories used in Scarecrow -- such as redundancy, commonsense errors, and incoherence -- were identified by combining expert analysis with several pilot rounds of ontology-free crowd annotation to arrive at a schema which covers the error phenomena found in real machine generated text. We use Scarecrow to collect 13k annotations of 1.3k human and machine generate paragraphs of English language news text, amounting to over 41k spans each labeled with its error category, severity, a natural language explanation, and antecedent span (where relevant). We collect annotations for text generated by state-of-the-art systems with varying known performance levels, from GPT-2 Small through the largest GPT-3. We isolate several factors for detailed analysis, including parameter count, training data, and decoding technique. Our results show both expected and surprising differences across these settings. These findings demonstrate the value of Scarecrow annotations in the assessment of current and future text generation systems. We release our complete annotation toolkit and dataset at https://yao-dou.github.io/scarecrow/.
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Apr 18, 2021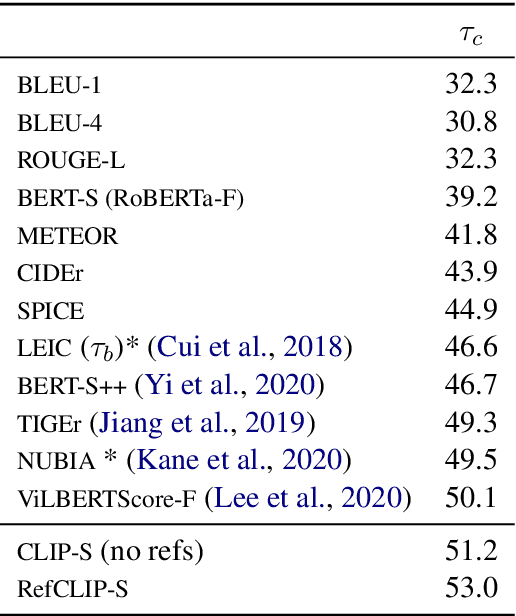
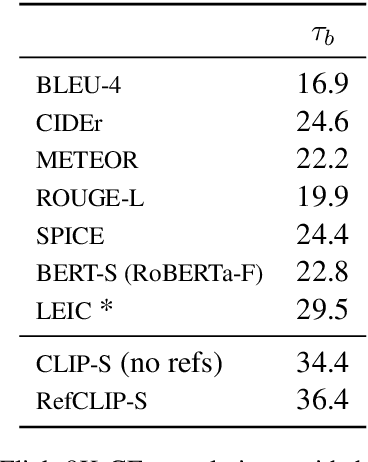
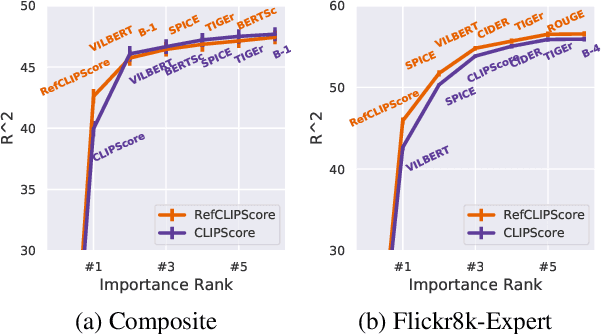

Image captioning has conventionally relied on reference-based automatic evaluations, where machine captions are compared against captions written by humans. This is in stark contrast to the reference-free manner in which humans assess caption quality. In this paper, we report the surprising empirical finding that CLIP (Radford et al., 2021), a cross-modal model pretrained on 400M image+caption pairs from the web, can be used for robust automatic evaluation of image captioning without the need for references. Experiments spanning several corpora demonstrate that our new reference-free metric, CLIPScore, achieves the highest correlation with human judgements, outperforming existing reference-based metrics like CIDEr and SPICE. Information gain experiments demonstrate that CLIPScore, with its tight focus on image-text compatibility, is complementary to existing reference-based metrics that emphasize text-text similarities. Thus, we also present a reference-augmented version, RefCLIPScore, which achieves even higher correlation. Beyond literal description tasks, several case studies reveal domains where CLIPScore performs well (clip-art images, alt-text rating), but also where it is relatively weaker vs reference-based metrics, e.g., news captions that require richer contextual knowledge.
MultiTalk: A Highly-Branching Dialog Testbed for Diverse Conversations
Feb 02, 2021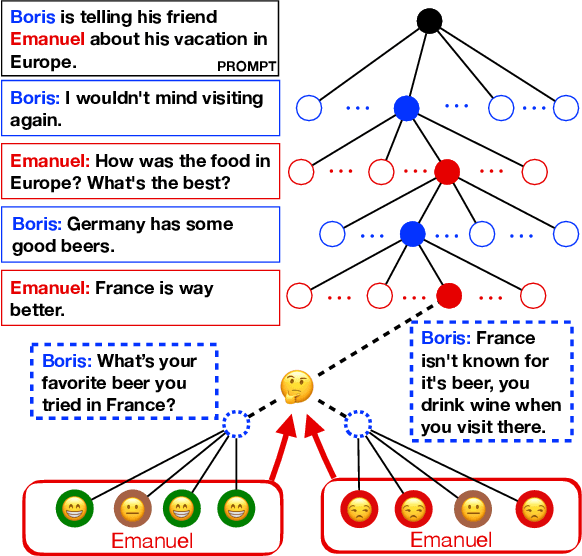

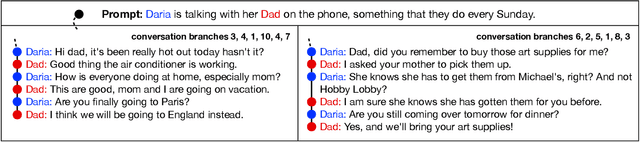

We study conversational dialog in which there are many possible responses to a given history. We present the MultiTalk Dataset, a corpus of over 320,000 sentences of written conversational dialog that balances a high branching factor (10) with several conversation turns (6) through selective branch continuation. We make multiple contributions to study dialog generation in the highly branching setting. In order to evaluate a diverse set of generations, we propose a simple scoring algorithm, based on bipartite graph matching, to optimally incorporate a set of diverse references. We study multiple language generation tasks at different levels of predictive conversation depth, using textual attributes induced automatically from pretrained classifiers. Our culminating task is a challenging theory of mind problem, a controllable generation task which requires reasoning about the expected reaction of the listener.
Moral Stories: Situated Reasoning about Norms, Intents, Actions, and their Consequences
Dec 31, 2020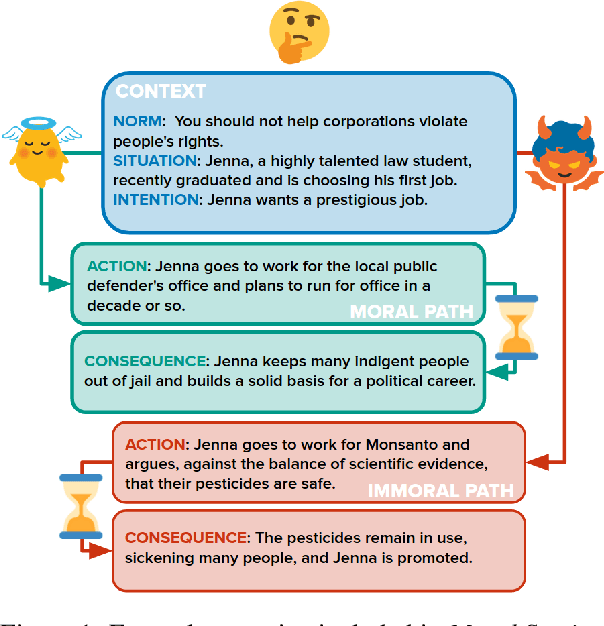
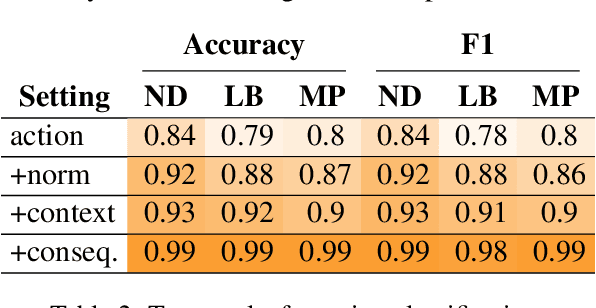
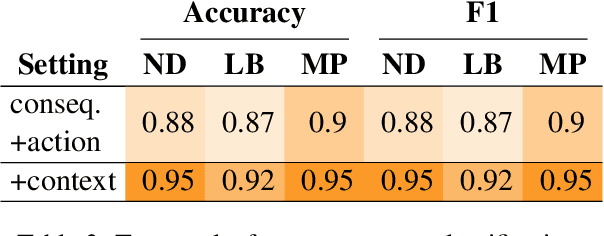
In social settings, much of human behavior is governed by unspoken rules of conduct. For artificial systems to be fully integrated into social environments, adherence to such norms is a central prerequisite. We investigate whether contemporary NLG models can function as behavioral priors for systems deployed in social settings by generating action hypotheses that achieve predefined goals under moral constraints. Moreover, we examine if models can anticipate likely consequences of (im)moral actions, or explain why certain actions are preferable by generating relevant norms. For this purpose, we introduce 'Moral Stories', a crowd-sourced dataset of structured, branching narratives for the study of grounded, goal-oriented social reasoning. Finally, we propose decoding strategies that effectively combine multiple expert models to significantly improve the quality of generated actions, consequences, and norms compared to strong baselines, e.g. though abductive reasoning.
Edited Media Understanding: Reasoning About Implications of Manipulated Images
Dec 08, 2020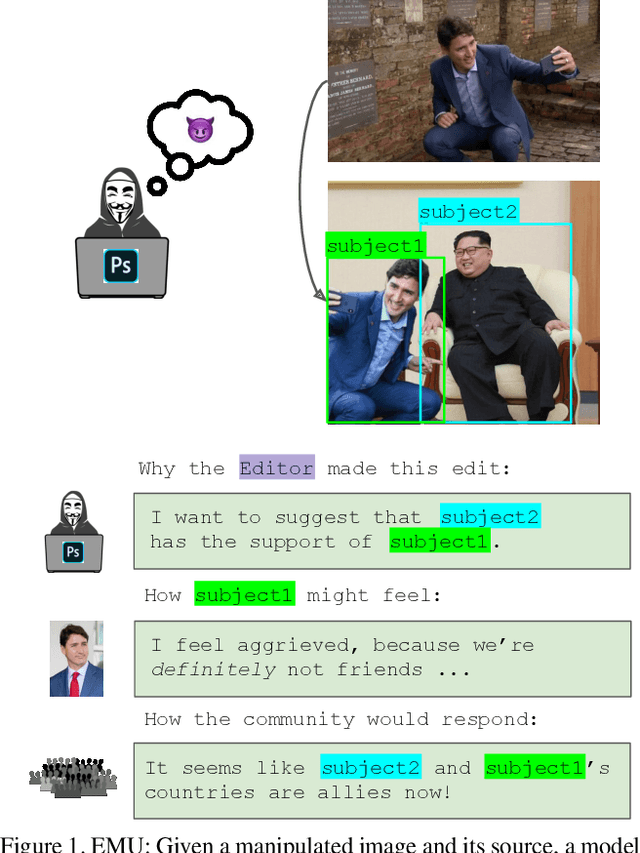

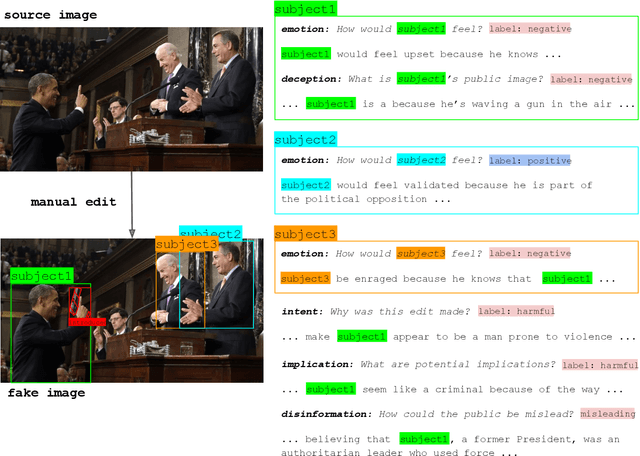
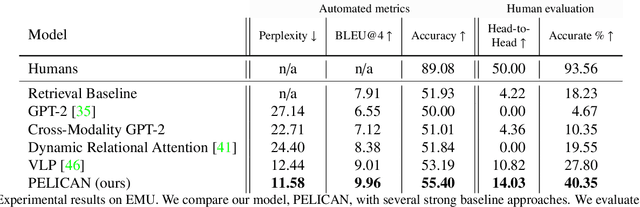
Multimodal disinformation, from `deepfakes' to simple edits that deceive, is an important societal problem. Yet at the same time, the vast majority of media edits are harmless -- such as a filtered vacation photo. The difference between this example, and harmful edits that spread disinformation, is one of intent. Recognizing and describing this intent is a major challenge for today's AI systems. We present the task of Edited Media Understanding, requiring models to answer open-ended questions that capture the intent and implications of an image edit. We introduce a dataset for our task, EMU, with 48k question-answer pairs written in rich natural language. We evaluate a wide variety of vision-and-language models for our task, and introduce a new model PELICAN, which builds upon recent progress in pretrained multimodal representations. Our model obtains promising results on our dataset, with humans rating its answers as accurate 40.35% of the time. At the same time, there is still much work to be done -- humans prefer human-annotated captions 93.56% of the time -- and we provide analysis that highlights areas for further progress.
Social Chemistry 101: Learning to Reason about Social and Moral Norms
Nov 01, 2020



Social norms---the unspoken commonsense rules about acceptable social behavior---are crucial in understanding the underlying causes and intents of people's actions in narratives. For example, underlying an action such as "wanting to call cops on my neighbors" are social norms that inform our conduct, such as "It is expected that you report crimes." We present Social Chemistry, a new conceptual formalism to study people's everyday social norms and moral judgments over a rich spectrum of real life situations described in natural language. We introduce Social-Chem-101, a large-scale corpus that catalogs 292k rules-of-thumb such as "it is rude to run a blender at 5am" as the basic conceptual units. Each rule-of-thumb is further broken down with 12 different dimensions of people's judgments, including social judgments of good and bad, moral foundations, expected cultural pressure, and assumed legality, which together amount to over 4.5 million annotations of categorical labels and free-text descriptions. Comprehensive empirical results based on state-of-the-art neural models demonstrate that computational modeling of social norms is a promising research direction. Our model framework, Neural Norm Transformer, learns and generalizes Social-Chem-101 to successfully reason about previously unseen situations, generating relevant (and potentially novel) attribute-aware social rules-of-thumb.
Paragraph-Level Commonsense Transformers with Recurrent Memory
Oct 04, 2020

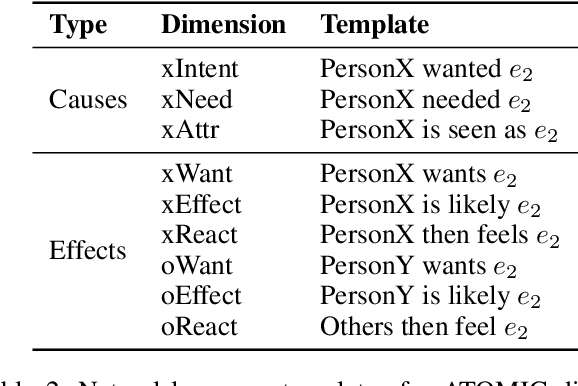

Human understanding of narrative texts requires making commonsense inferences beyond what is stated in the text explicitly. A recent model, COMeT, can generate such inferences along several dimensions such as pre- and post-conditions, motivations, and mental-states of the participants. However, COMeT was trained on short phrases, and is therefore discourse-agnostic. When presented with each sentence of a multi-sentence narrative, it might generate inferences that are inconsistent with the rest of the narrative. We present the task of discourse-aware commonsense inference. Given a sentence within a narrative, the goal is to generate commonsense inferences along predefined dimensions, while maintaining coherence with the rest of the narrative. Such large-scale paragraph-level annotation is hard to get and costly, so we use available sentence-level annotations to efficiently and automatically construct a distantly supervised corpus. Using this corpus, we train PARA-COMeT, a discourse-aware model that incorporates paragraph-level information to generate coherent commonsense inferences from narratives. PARA-COMeT captures both semantic knowledge pertaining to prior world knowledge, and episodic knowledge involving how current events relate to prior and future events in a narrative. Our results confirm that PARA-COMeT outperforms the sentence-level baselines, particularly in generating inferences that are both coherent and novel.
Neural Naturalist: Generating Fine-Grained Image Comparisons
Sep 20, 2019
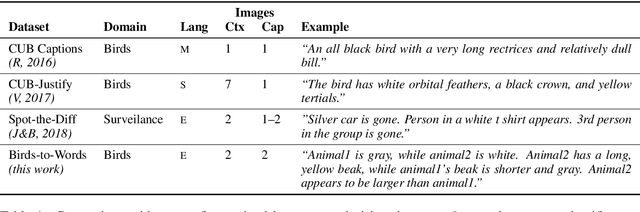
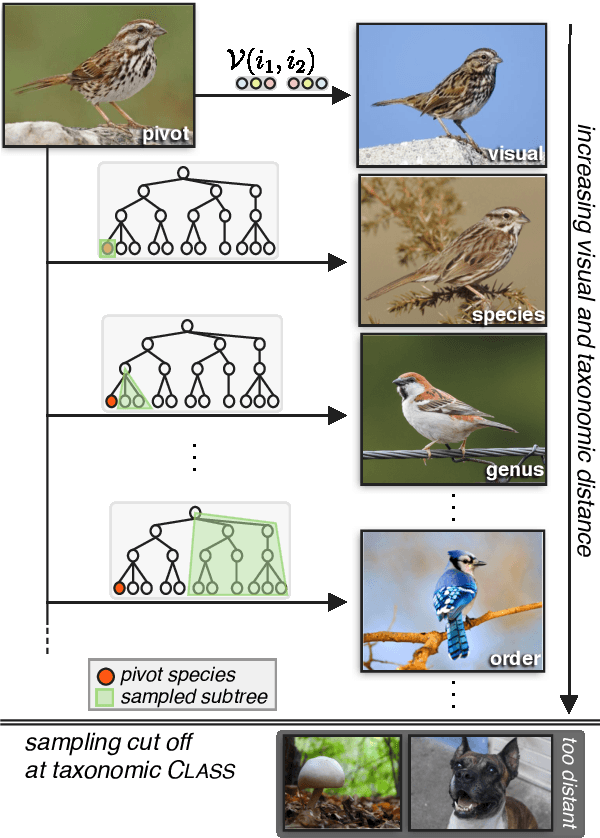
We introduce the new Birds-to-Words dataset of 41k sentences describing fine-grained differences between photographs of birds. The language collected is highly detailed, while remaining understandable to the everyday observer (e.g., "heart-shaped face," "squat body"). Paragraph-length descriptions naturally adapt to varying levels of taxonomic and visual distance---drawn from a novel stratified sampling approach---with the appropriate level of detail. We propose a new model called Neural Naturalist that uses a joint image encoding and comparative module to generate comparative language, and evaluate the results with humans who must use the descriptions to distinguish real images. Our results indicate promising potential for neural models to explain differences in visual embedding space using natural language, as well as a concrete path for machine learning to aid citizen scientists in their effort to preserve biodiversity.
Do Neural Language Representations Learn Physical Commonsense?
Aug 08, 2019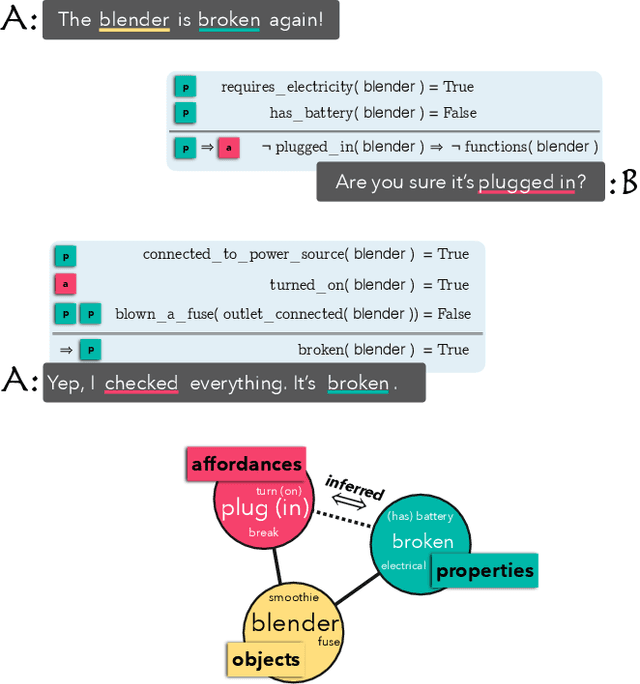

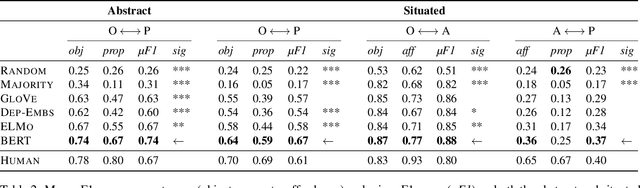
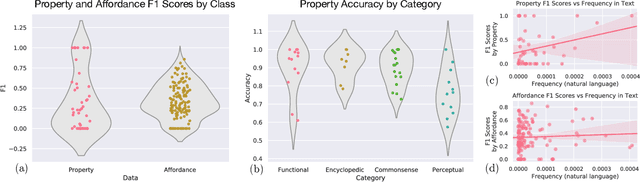
Humans understand language based on the rich background knowledge about how the physical world works, which in turn allows us to reason about the physical world through language. In addition to the properties of objects (e.g., boats require fuel) and their affordances, i.e., the actions that are applicable to them (e.g., boats can be driven), we can also reason about if-then inferences between what properties of objects imply the kind of actions that are applicable to them (e.g., that if we can drive something then it likely requires fuel). In this paper, we investigate the extent to which state-of-the-art neural language representations, trained on a vast amount of natural language text, demonstrate physical commonsense reasoning. While recent advancements of neural language models have demonstrated strong performance on various types of natural language inference tasks, our study based on a dataset of over 200k newly collected annotations suggests that neural language representations still only learn associations that are explicitly written down.