 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTalk: A Highly-Branching Dialog Testbed for Diverse Conversations
Paper and Code
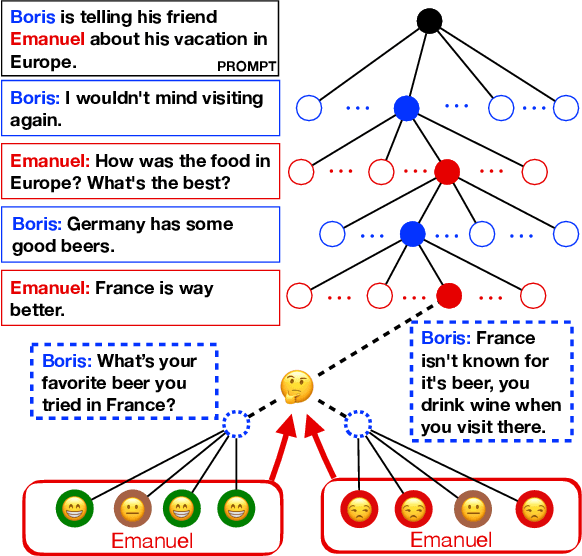

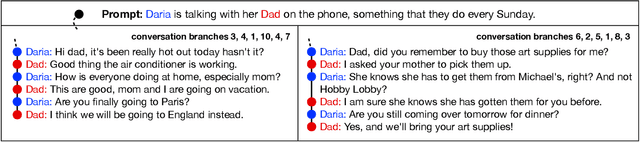

We study conversational dialog in which there are many possible responses to a given history. We present the MultiTalk Dataset, a corpus of over 320,000 sentences of written conversational dialog that balances a high branching factor (10) with several conversation turns (6) through selective branch continuation. We make multiple contributions to study dialog generation in the highly branching setting. In order to evaluate a diverse set of generations, we propose a simple scoring algorithm, based on bipartite graph matching, to optimally incorporate a set of diverse references. We study multiple language generation tasks at different levels of predictive conversation depth, using textual attributes induced automatically from pretrained classifiers. Our culminating task is a challenging theory of mind problem, a controllable generation task which requires reasoning about the expected reaction of the listener.