 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScarecrow: A Framework for Scrutinizing Machine Text
Paper and Code

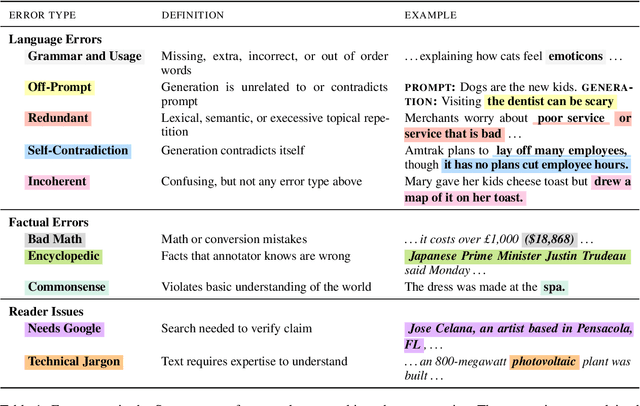
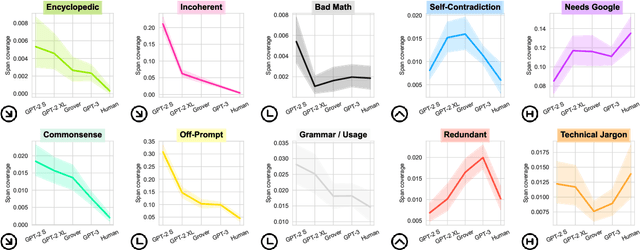
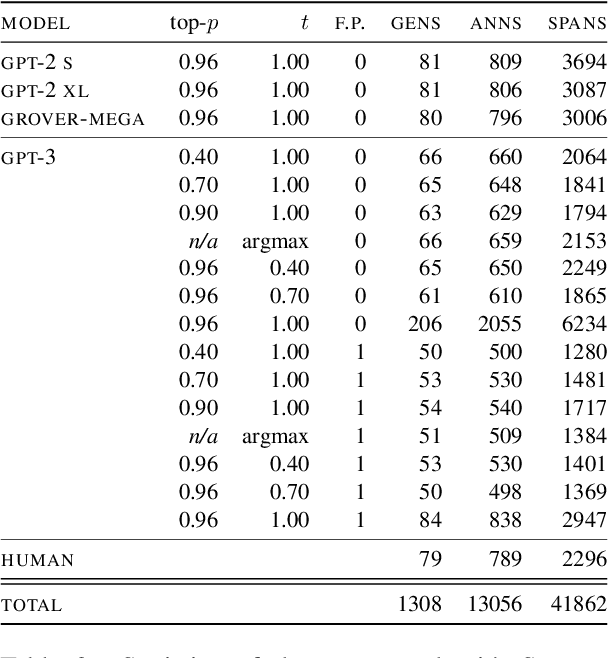
Modern neural text generation systems can produce remarkably fluent and grammatical texts. While earlier language models suffered from repetition and syntactic errors, the errors made by contemporary models are often semantic, narrative, or discourse failures. To facilitate research of these complex error types, we introduce a new structured, crowdsourced error annotation schema called Scarecrow. The error categories used in Scarecrow -- such as redundancy, commonsense errors, and incoherence -- were identified by combining expert analysis with several pilot rounds of ontology-free crowd annotation to arrive at a schema which covers the error phenomena found in real machine generated text. We use Scarecrow to collect 13k annotations of 1.3k human and machine generate paragraphs of English language news text, amounting to over 41k spans each labeled with its error category, severity, a natural language explanation, and antecedent span (where relevant). We collect annotations for text generated by state-of-the-art systems with varying known performance levels, from GPT-2 Small through the largest GPT-3. We isolate several factors for detailed analysis, including parameter count, training data, and decoding technique. Our results show both expected and surprising differences across these settings. These findings demonstrate the value of Scarecrow annotations in the assessment of current and future text generation systems. We release our complete annotation toolkit and dataset at https://yao-dou.github.io/scarecrow/.