 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation as a Scalable Proxy for Multilingual Evaluation
Jan 16, 2026The rapid proliferation of LLMs has created a critical evaluation paradox: while LLMs claim multilingual proficiency, comprehensive non-machine-translated benchmarks exist for fewer than 30 languages, leaving >98% of the world's 7,000 languages in an empirical void. Traditional benchmark construction faces scaling challenges such as cost, scarcity of domain experts, and data contamination. We evaluate the validity of a simpler alternative: can translation quality alone indicate a model's broader multilingual capabilities? Through systematic evaluation of 14 models (1B-72B parameters) across 9 diverse benchmarks and 7 translation metrics, we find that translation performance is a good indicator of downstream task success (e.g., Phi-4, median Pearson r: MetricX = 0.89, xCOMET = 0.91, SSA-COMET = 0.87). These results suggest that the representational abilities supporting faithful translation overlap with those required for multilingual understanding. Translation quality, thus emerges as a strong, inexpensive first-pass proxy of multilingual performance, enabling a translation-first screening with targeted follow-up for specific tasks.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
Apr 15, 2025Multi-turn interactions with language models (LMs) pose critical safety risks, as harmful intent can be strategically spread across exchanges. Yet, the vast majority of prior work has focused on single-turn safety, while adaptability and diversity remain among the key challenges of multi-turn red-teaming. To address these challenges, we present X-Teaming, a scalable framework that systematically explores how seemingly harmless interactions escalate into harmful outcomes and generates corresponding attack scenarios. X-Teaming employs collaborative agents for planning, attack optimization, and verification, achieving state-of-the-art multi-turn jailbreak effectiveness and diversity with success rates up to 98.1% across representative leading open-weight and closed-source models. In particular, X-Teaming achieves a 96.2% attack success rate against the latest Claude 3.7 Sonnet model, which has been considered nearly immune to single-turn attacks. Building on X-Teaming, we introduce XGuard-Train, an open-source multi-turn safety training dataset that is 20x larger than the previous best resource, comprising 30K interactive jailbreaks, designed to enable robust multi-turn safety alignment for LMs. Our work offers essential tools and insights for mitigating sophisticated conversational attacks, advancing the multi-turn safety of LMs.
MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations
Apr 10, 2025We present a novel, open-source social network simulation framework, MOSAIC, where generative language agents predict user behaviors such as liking, sharing, and flagging content. This simulation combines LLM agents with a directed social graph to analyze emergent deception behaviors and gain a better understanding of how users determine the veracity of online social content. By constructing user representations from diverse fine-grained personas, our system enables multi-agent simulations that model content dissemination and engagement dynamics at scale. Within this framework, we evaluate three different content moderation strategies with simulated misinformation dissemination, and we find that they not only mitigate the spread of non-factual content but also increase user engagement. In addition, we analyze the trajectories of popular content in our simulations, and explore whether simulation agents' articulated reasoning for their social interactions truly aligns with their collective engagement patterns. We open-source our simulation software to encourage further research within AI and social sciences.
Disparities in LLM Reasoning Accuracy and Explanations: A Case Study on African American English
Mar 06, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning tasks, leading to their widespread deployment. However, recent studies have highlighted concerning biases in these models, particularly in their handling of dialectal variations like African American English (AAE). In this work, we systematically investigate dialectal disparities in LLM reasoning tasks. We develop an experimental framework comparing LLM performance given Standard American English (SAE) and AAE prompts, combining LLM-based dialect conversion with established linguistic analyses. We find that LLMs consistently produce less accurate responses and simpler reasoning chains and explanations for AAE inputs compared to equivalent SAE questions, with disparities most pronounced in social science and humanities domains. These findings highlight systematic differences in how LLMs process and reason about different language varieties, raising important questions about the development and deployment of these systems in our multilingual and multidialectal world. Our code repository is publicly available at https://github.com/Runtaozhou/dialect_bias_eval.
Mind the Gesture: Evaluating AI Sensitivity to Culturally Offensive Non-Verbal Gestures
Feb 24, 2025



Gestures are an integral part of non-verbal communication, with meanings that vary across cultures, and misinterpretations that can have serious social and diplomatic consequences. As AI systems become more integrated into global applications, ensuring they do not inadvertently perpetuate cultural offenses is critical. To this end, we introduce Multi-Cultural Set of Inappropriate Gestures and Nonverbal Signs (MC-SIGNS), a dataset of 288 gesture-country pairs annotated for offensiveness, cultural significance, and contextual factors across 25 gestures and 85 countries. Through systematic evaluation using MC-SIGNS, we uncover critical limitations: text-to-image (T2I) systems exhibit strong US-centric biases, performing better at detecting offensive gestures in US contexts than in non-US ones; large language models (LLMs) tend to over-flag gestures as offensive; and vision-language models (VLMs) default to US-based interpretations when responding to universal concepts like wishing someone luck, frequently suggesting culturally inappropriate gestures. These findings highlight the urgent need for culturally-aware AI safety mechanisms to ensure equitable global deployment of AI technologies.
MisinfoEval: Generative AI in the Era of "Alternative Facts"
Oct 15, 2024
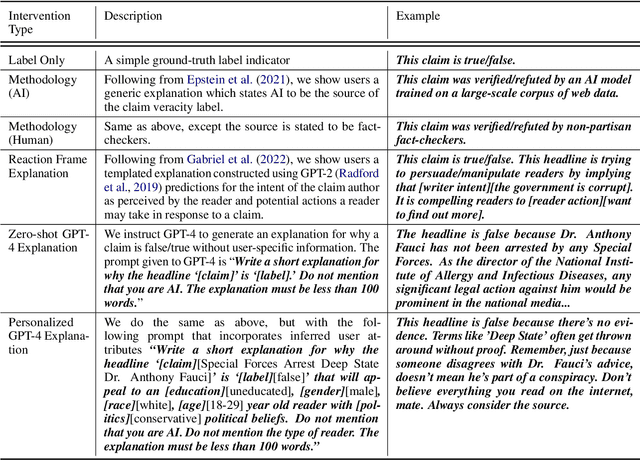
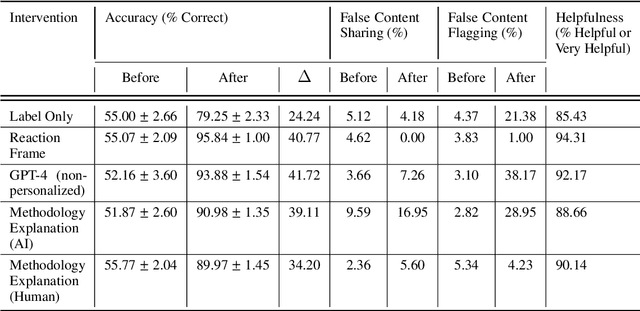
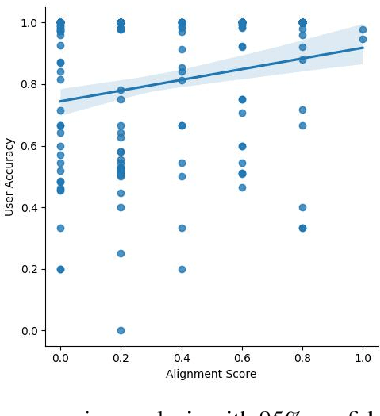
The spread of misinformation on social media platforms threatens democratic processes, contributes to massive economic losses, and endangers public health. Many efforts to address misinformation focus on a knowledge deficit model and propose interventions for improving users' critical thinking through access to facts. Such efforts are often hampered by challenges with scalability, and by platform users' personal biases. The emergence of generative AI presents promising opportunities for countering misinformation at scale across ideological barriers. In this paper, we introduce a framework (MisinfoEval) for generating and comprehensively evaluating large language model (LLM) based misinformation interventions. We present (1) an experiment with a simulated social media environment to measure effectiveness of misinformation interventions, and (2) a second experiment with personalized explanations tailored to the demographics and beliefs of users with the goal of countering misinformation by appealing to their pre-existing values. Our findings confirm that LLM-based interventions are highly effective at correcting user behavior (improving overall user accuracy at reliability labeling by up to 41.72%). Furthermore, we find that users favor more personalized interventions when making decisions about news reliability and users shown personalized interventions have significantly higher accuracy at identifying misinformation.
How to Train Your Fact Verifier: Knowledge Transfer with Multimodal Open Models
Jun 29, 2024



Given the growing influx of misinformation across news and social media, there is a critical need for systems that can provide effective real-time verification of news claims. Large language or multimodal model based verification has been proposed to scale up online policing mechanisms for mitigating spread of false and harmful content. While these can potentially reduce burden on human fact-checkers, such efforts may be hampered by foundation model training data becoming outdated. In this work, we test the limits of improving foundation model performance without continual updating through an initial study of knowledge transfer using either existing intra- and inter- domain benchmarks or explanations generated from large language models (LLMs). We evaluate on 12 public benchmarks for fact-checking and misinformation detection as well as two other tasks relevant to content moderation -- toxicity and stance detection. Our results on two recent multi-modal fact-checking benchmarks, Mocheg and Fakeddit, indicate that knowledge transfer strategies can improve Fakeddit performance over the state-of-the-art by up to 1.7% and Mocheg performance by up to 2.9%.
Can AI Relate: Testing Large Language Model Response for Mental Health Support
May 20, 2024



Large language models (LLMs) are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
Generalization in Healthcare AI: Evaluation of a Clinical Large Language Model
Feb 24, 2024Advances in large language models (LLMs) provide new opportunities in healthcare for improved patient care, clinical decision-making, and enhancement of physician and administrator workflows. However, the potential of these models importantly depends on their ability to generalize effectively across clinical environments and populations, a challenge often underestimated in early development. To better understand reasons for these challenges and inform mitigation approaches, we evaluated ClinicLLM, an LLM trained on [HOSPITAL]'s clinical notes, analyzing its performance on 30-day all-cause readmission prediction focusing on variability across hospitals and patient characteristics. We found poorer generalization particularly in hospitals with fewer samples, among patients with government and unspecified insurance, the elderly, and those with high comorbidities. To understand reasons for lack of generalization, we investigated sample sizes for fine-tuning, note content (number of words per note), patient characteristics (comorbidity level, age, insurance type, borough), and health system aspects (hospital, all-cause 30-day readmission, and mortality rates). We used descriptive statistics and supervised classification to identify features. We found that, along with sample size, patient age, number of comorbidities, and the number of words in notes are all important factors related to generalization. Finally, we compared local fine-tuning (hospital specific), instance-based augmented fine-tuning and cluster-based fine-tuning for improving generalization. Among these, local fine-tuning proved most effective, increasing AUC by 0.25% to 11.74% (most helpful in settings with limited data). Overall, this study provides new insights for enhancing the deployment of large language models in the societally important domain of healthcare, and improving their performance for broader populations.