 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebCoach: Self-Evolving Web Agents with Cross-Session Memory Guidance
Nov 17, 2025Multimodal LLM-powered agents have recently demonstrated impressive capabilities in web navigation, enabling agents to complete complex browsing tasks across diverse domains. However, current agents struggle with repetitive errors and lack the ability to learn from past experiences across sessions, limiting their long-term robustness and sample efficiency. We introduce WebCoach, a model-agnostic self-evolving framework that equips web browsing agents with persistent cross-session memory, enabling improved long-term planning, reflection, and continual learning without retraining. WebCoach consists of three key components: (1) a WebCondenser, which standardizes raw navigation logs into concise summaries; (2) an External Memory Store, which organizes complete trajectories as episodic experiences; and (3) a Coach, which retrieves relevant experiences based on similarity and recency, and decides whether to inject task-specific advice into the agent via runtime hooks. This design empowers web agents to access long-term memory beyond their native context window, improving robustness in complex browsing tasks. Moreover, WebCoach achieves self-evolution by continuously curating episodic memory from new navigation trajectories, enabling agents to improve over time without retraining. Evaluations on the WebVoyager benchmark demonstrate that WebCoach consistently improves the performance of browser-use agents across three different LLM backbones. With a 38B model, it increases task success rates from 47% to 61% while reducing or maintaining the average number of steps. Notably, smaller base models with WebCoach achieve performance comparable to the same web agent using GPT-4o.
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
Apr 15, 2025Multi-turn interactions with language models (LMs) pose critical safety risks, as harmful intent can be strategically spread across exchanges. Yet, the vast majority of prior work has focused on single-turn safety, while adaptability and diversity remain among the key challenges of multi-turn red-teaming. To address these challenges, we present X-Teaming, a scalable framework that systematically explores how seemingly harmless interactions escalate into harmful outcomes and generates corresponding attack scenarios. X-Teaming employs collaborative agents for planning, attack optimization, and verification, achieving state-of-the-art multi-turn jailbreak effectiveness and diversity with success rates up to 98.1% across representative leading open-weight and closed-source models. In particular, X-Teaming achieves a 96.2% attack success rate against the latest Claude 3.7 Sonnet model, which has been considered nearly immune to single-turn attacks. Building on X-Teaming, we introduce XGuard-Train, an open-source multi-turn safety training dataset that is 20x larger than the previous best resource, comprising 30K interactive jailbreaks, designed to enable robust multi-turn safety alignment for LMs. Our work offers essential tools and insights for mitigating sophisticated conversational attacks, advancing the multi-turn safety of LMs.
MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations
Apr 10, 2025



We present a novel, open-source social network simulation framework, MOSAIC, where generative language agents predict user behaviors such as liking, sharing, and flagging content. This simulation combines LLM agents with a directed social graph to analyze emergent deception behaviors and gain a better understanding of how users determine the veracity of online social content. By constructing user representations from diverse fine-grained personas, our system enables multi-agent simulations that model content dissemination and engagement dynamics at scale. Within this framework, we evaluate three different content moderation strategies with simulated misinformation dissemination, and we find that they not only mitigate the spread of non-factual content but also increase user engagement. In addition, we analyze the trajectories of popular content in our simulations, and explore whether simulation agents' articulated reasoning for their social interactions truly aligns with their collective engagement patterns. We open-source our simulation software to encourage further research within AI and social sciences.
SciCode: A Research Coding Benchmark Curated by Scientists
Jul 18, 2024



Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs' capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode. The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.
Prudent Silence or Foolish Babble? Examining Large Language Models' Responses to the Unknown
Nov 16, 2023
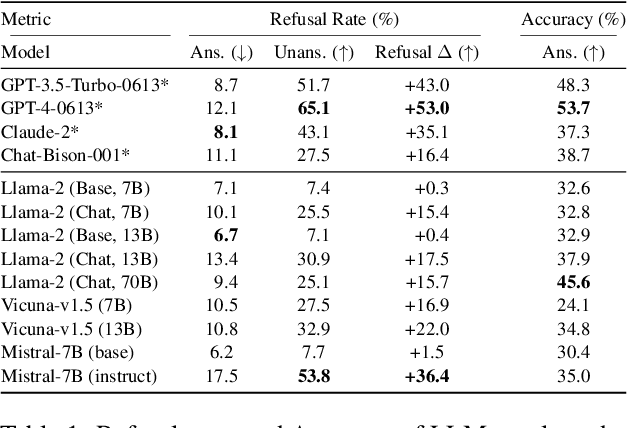

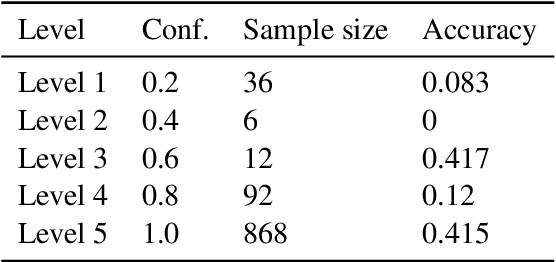
Large Language Models (LLMs) often struggle when faced with situations where they lack the prerequisite knowledge to generate a sensical response. In these cases, models tend to fabricate and hallucinate, rather than appropriately signaling uncertainty as humans would. This behavior misaligns with human conversational norms and presents challenges surrounding responsible and ethical AI development. This work aims to systematically investigate LLMs' behaviors in such situations. We curate an adversarial question-answering benchmark containing unanswerable questions targeting information absent from the LLM's training data. Concretely, these unanswerable questions contain non-existent concepts or false premises. When presented with such unanswerable questions, an LLM should appropriately convey uncertainty, and be able to challenge the premise and refuse to generate a response. While facing answerable valid questions, a model should demonstrate a positive correlation between accuracy and confidence. Using a model-agnostic unified confidence elicitation approach, we observe that LLMs that have gone through instruction finetuning and reinforcement learning from human feedback (RLHF) perform significantly better than their counterparts that do not. Moreover, uncertainty expression 1 through our elicitation method does not always stay consistent with the perceived confidence of the direct response of an LLM. Our findings call for further research into teaching LLMs to proactively and reliably express uncertainty.
Paxion: Patching Action Knowledge in Video-Language Foundation Models
May 26, 2023



Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks: Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models' (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks.