 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Can LLMs Learn to Reason with Weak Supervision?
Apr 20, 2026Large language models have achieved significant reasoning improvements through reinforcement learning with verifiable rewards (RLVR). Yet as model capabilities grow, constructing high-quality reward signals becomes increasingly difficult, making it essential to understand when RLVR can succeed under weaker forms of supervision. We conduct a systematic empirical study across diverse model families and reasoning domains under three weak supervision settings: scarce data, noisy rewards, and self-supervised proxy rewards. We find that generalization is governed by training reward saturation dynamics: models that generalize exhibit a prolonged pre-saturation phase during which training reward and downstream performance climb together, while models that saturate rapidly memorize rather than learn. We identify reasoning faithfulness, defined as the extent to which intermediate steps logically support the final answer, as the pre-RL property that predicts which regime a model falls into, while output diversity alone is uninformative. Motivated by these findings, we disentangle the contributions of continual pre-training and supervised fine-tuning, finding that SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect. Applied together to Llama3.2-3B-Base, these interventions enable generalization across all three settings where the base model previously failed.
CoDaS: AI Co-Data-Scientist for Biomarker Discovery via Wearable Sensors
Apr 16, 2026Scientific discovery in digital health requires converting continuous physiological signals from wearable devices into clinically actionable biomarkers. We introduce CoDaS (AI Co-Data-Scientist), a multi-agent system that structures biomarker discovery as an iterative process combining hypothesis generation, statistical analysis, adversarial validation, and literature-grounded reasoning with human oversight using large-scale wearable datasets. Across three cohorts totaling 9,279 participant-observations, CoDaS identified 41 candidate digital biomarkers for mental health and 25 for metabolic outcomes, each subjected to an internal validation battery spanning replication, stability, robustness, and discriminative power. Across two independent depression cohorts, CoDaS surfaced circadian instability-related features in both datasets, reflected in sleep duration variability (DWB, ρ= 0.252, p < 0.001) and sleep onset variability (GLOBEM, ρ= 0.126, p < 0.001). In a metabolic cohort, CoDaS derived a cardiovascular fitness index (steps/resting heart rate; ρ= -0.374, p < 0.001), and recovered established clinical associations, including the hepatic function ratio (AST/ALT; ρ= -0.375, p < 0.001), a known correlate of insulin resistance. Incorporating CoDaS-derived features alongside demographic variables led to modest but consistent improvements in predictive performance, with cross-validated ΔR^2 increases of 0.040 for depression and 0.021 for insulin resistance. These findings suggest that CoDaS enables systematic and traceable hypothesis generation and prioritization for biomarker discovery from large-scale wearable data.
Xolver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team
Jun 17, 2025Despite impressive progress on complex reasoning, current large language models (LLMs) typically operate in isolation - treating each problem as an independent attempt, without accumulating or integrating experiential knowledge. In contrast, expert problem solvers - such as Olympiad or programming contest teams - leverage a rich tapestry of experiences: absorbing mentorship from coaches, developing intuition from past problems, leveraging knowledge of tool usage and library functionality, adapting strategies based on the expertise and experiences of peers, continuously refining their reasoning through trial and error, and learning from other related problems even during competition. We introduce Xolver, a training-free multi-agent reasoning framework that equips a black-box LLM with a persistent, evolving memory of holistic experience. Xolver integrates diverse experience modalities, including external and self-retrieval, tool use, collaborative interactions, agent-driven evaluation, and iterative refinement. By learning from relevant strategies, code fragments, and abstract reasoning patterns at inference time, Xolver avoids generating solutions from scratch - marking a transition from isolated inference toward experience-aware language agents. Built on both open-weight and proprietary models, Xolver consistently outperforms specialized reasoning agents. Even with lightweight backbones (e.g., QWQ-32B), it often surpasses advanced models including Qwen3-235B, Gemini 2.5 Pro, o3, and o4-mini-high. With o3-mini-high, it achieves new best results on GSM8K (98.1%), AIME'24 (94.4%), AIME'25 (93.7%), Math-500 (99.8%), and LiveCodeBench-V5 (91.6%) - highlighting holistic experience learning as a key step toward generalist agents capable of expert-level reasoning. Code and data are available at https://kagnlp.github.io/xolver.github.io/.
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
Apr 15, 2025Multi-turn interactions with language models (LMs) pose critical safety risks, as harmful intent can be strategically spread across exchanges. Yet, the vast majority of prior work has focused on single-turn safety, while adaptability and diversity remain among the key challenges of multi-turn red-teaming. To address these challenges, we present X-Teaming, a scalable framework that systematically explores how seemingly harmless interactions escalate into harmful outcomes and generates corresponding attack scenarios. X-Teaming employs collaborative agents for planning, attack optimization, and verification, achieving state-of-the-art multi-turn jailbreak effectiveness and diversity with success rates up to 98.1% across representative leading open-weight and closed-source models. In particular, X-Teaming achieves a 96.2% attack success rate against the latest Claude 3.7 Sonnet model, which has been considered nearly immune to single-turn attacks. Building on X-Teaming, we introduce XGuard-Train, an open-source multi-turn safety training dataset that is 20x larger than the previous best resource, comprising 30K interactive jailbreaks, designed to enable robust multi-turn safety alignment for LMs. Our work offers essential tools and insights for mitigating sophisticated conversational attacks, advancing the multi-turn safety of LMs.
MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations
Apr 10, 2025



We present a novel, open-source social network simulation framework, MOSAIC, where generative language agents predict user behaviors such as liking, sharing, and flagging content. This simulation combines LLM agents with a directed social graph to analyze emergent deception behaviors and gain a better understanding of how users determine the veracity of online social content. By constructing user representations from diverse fine-grained personas, our system enables multi-agent simulations that model content dissemination and engagement dynamics at scale. Within this framework, we evaluate three different content moderation strategies with simulated misinformation dissemination, and we find that they not only mitigate the spread of non-factual content but also increase user engagement. In addition, we analyze the trajectories of popular content in our simulations, and explore whether simulation agents' articulated reasoning for their social interactions truly aligns with their collective engagement patterns. We open-source our simulation software to encourage further research within AI and social sciences.
Generalization in Healthcare AI: Evaluation of a Clinical Large Language Model
Feb 24, 2024Advances in large language models (LLMs) provide new opportunities in healthcare for improved patient care, clinical decision-making, and enhancement of physician and administrator workflows. However, the potential of these models importantly depends on their ability to generalize effectively across clinical environments and populations, a challenge often underestimated in early development. To better understand reasons for these challenges and inform mitigation approaches, we evaluated ClinicLLM, an LLM trained on [HOSPITAL]'s clinical notes, analyzing its performance on 30-day all-cause readmission prediction focusing on variability across hospitals and patient characteristics. We found poorer generalization particularly in hospitals with fewer samples, among patients with government and unspecified insurance, the elderly, and those with high comorbidities. To understand reasons for lack of generalization, we investigated sample sizes for fine-tuning, note content (number of words per note), patient characteristics (comorbidity level, age, insurance type, borough), and health system aspects (hospital, all-cause 30-day readmission, and mortality rates). We used descriptive statistics and supervised classification to identify features. We found that, along with sample size, patient age, number of comorbidities, and the number of words in notes are all important factors related to generalization. Finally, we compared local fine-tuning (hospital specific), instance-based augmented fine-tuning and cluster-based fine-tuning for improving generalization. Among these, local fine-tuning proved most effective, increasing AUC by 0.25% to 11.74% (most helpful in settings with limited data). Overall, this study provides new insights for enhancing the deployment of large language models in the societally important domain of healthcare, and improving their performance for broader populations.
Impact on Public Health Decision Making by Utilizing Big Data Without Domain Knowledge
Feb 08, 2024New data sources, and artificial intelligence (AI) methods to extract information from them are becoming plentiful, and relevant to decision making in many societal applications. An important example is street view imagery, available in over 100 countries, and considered for applications such as assessing built environment aspects in relation to community health outcomes. Relevant to such uses, important examples of bias in the use of AI are evident when decision-making based on data fails to account for the robustness of the data, or predictions are based on spurious correlations. To study this risk, we utilize 2.02 million GSV images along with health, demographic, and socioeconomic data from New York City. Initially, we demonstrate that built environment characteristics inferred from GSV labels at the intra-city level may exhibit inadequate alignment with the ground truth. We also find that the average individual-level behavior of physical inactivity significantly mediates the impact of built environment features by census tract, as measured through GSV. Finally, using a causal framework which accounts for these mediators of environmental impacts on health, we find that altering 10% of samples in the two lowest tertiles would result in a 4.17 (95% CI 3.84 to 4.55) or 17.2 (95% CI 14.4 to 21.3) times bigger decrease on the prevalence of obesity or diabetes, than the same proportional intervention on the number of crosswalks by census tract. This work illustrates important issues of robustness and model specification for informing effective allocation of interventions using new data sources.
Understanding Disparities in Post Hoc Machine Learning Explanation
Jan 25, 2024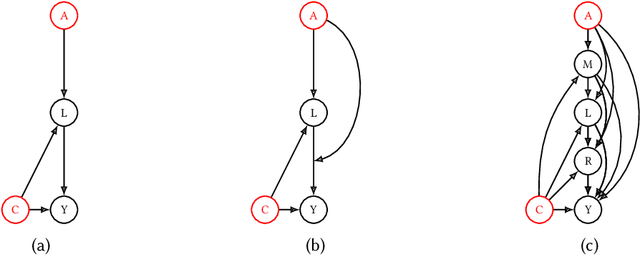
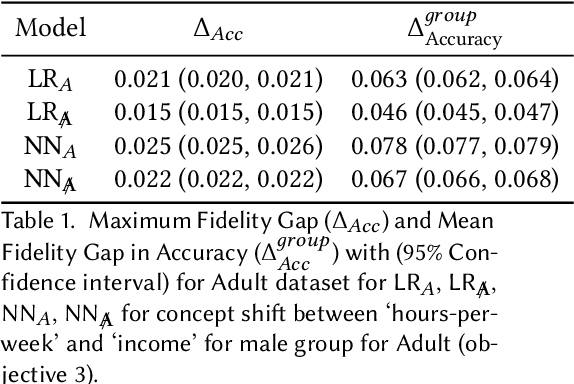
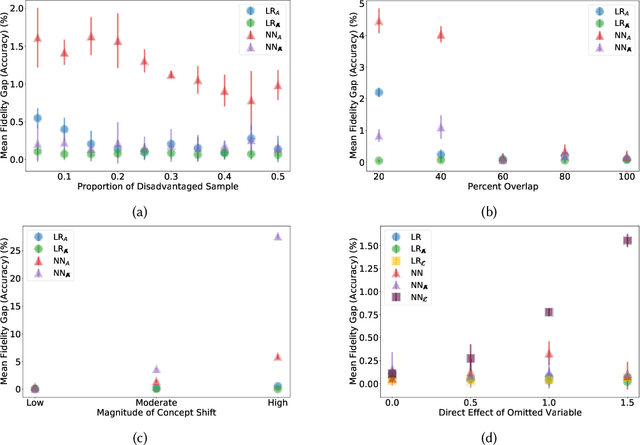
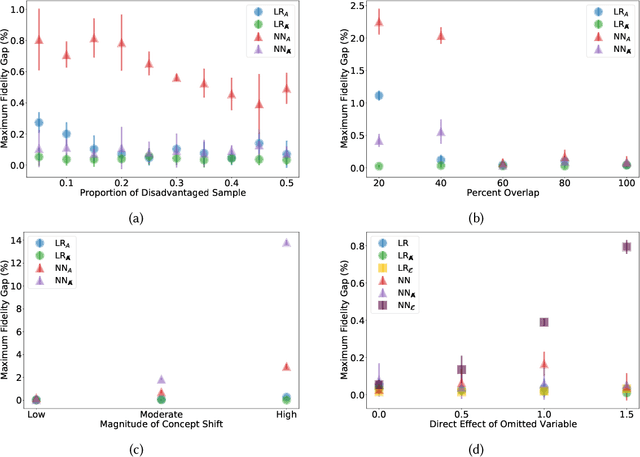
Previous work has highlighted that existing post-hoc explanation methods exhibit disparities in explanation fidelity (across 'race' and 'gender' as sensitive attributes), and while a large body of work focuses on mitigating these issues at the explanation metric level, the role of the data generating process and black box model in relation to explanation disparities remains largely unexplored. Accordingly, through both simulations as well as experiments on a real-world dataset, we specifically assess challenges to explanation disparities that originate from properties of the data: limited sample size, covariate shift, concept shift, omitted variable bias, and challenges based on model properties: inclusion of the sensitive attribute and appropriate functional form. Through controlled simulation analyses, our study demonstrates that increased covariate shift, concept shift, and omission of covariates increase explanation disparities, with the effect pronounced higher for neural network models that are better able to capture the underlying functional form in comparison to linear models. We also observe consistent findings regarding the effect of concept shift and omitted variable bias on explanation disparities in the Adult income dataset. Overall, results indicate that disparities in model explanations can also depend on data and model properties. Based on this systematic investigation, we provide recommendations for the design of explanation methods that mitigate undesirable disparities.