 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Robust Language Model Generation via Content Integrity Preservation
Jan 14, 2026Large Language Model (LLM) outputs often vary across user sociodemographic attributes, leading to disparities in factual accuracy, utility, and safety, even for objective questions where demographic information is irrelevant. Unlike prior work on stereotypical or representational bias, this paper studies identity-dependent degradation of core response quality. We show empirically that such degradation arises from biased generation behavior, despite factual knowledge being robustly encoded across identities. Motivated by this mismatch, we propose a lightweight, training-free framework for identity-robust generation that selectively neutralizes non-critical identity information while preserving semantically essential attributes, thus maintaining output content integrity. Experiments across four benchmarks and 18 sociodemographic identities demonstrate an average 77% reduction in identity-dependent bias compared to vanilla prompting and a 45% reduction relative to prompt-based defenses. Our work addresses a critical gap in mitigating the impact of user identity cues in prompts on core generation quality.
Dealing with the Evil Twins: Improving Random Augmentation by Addressing Catastrophic Forgetting of Diverse Augmentations
Jun 09, 2025Data augmentation is a promising tool for enhancing out-of-distribution generalization, where the key is to produce diverse, challenging variations of the source domain via costly targeted augmentations that maximize its generalization effect. Conversely, random augmentation is inexpensive but is deemed suboptimal due to its limited effect. In this paper, we revisit random augmentation and explore methods to address its shortcomings. We show that the stochastic nature of random augmentation can produce a set of colliding augmentations that distorts the learned features, similar to catastrophic forgetting. We propose a simple solution that improves the generalization effect of random augmentation by addressing forgetting, which displays strong generalization performance across various single source domain generalization (sDG) benchmarks.
Domain Adaptation Under MNAR Missingness
Apr 01, 2025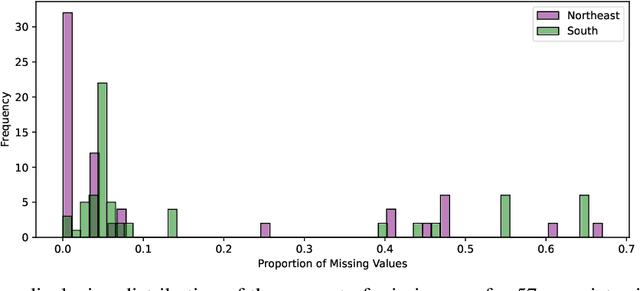
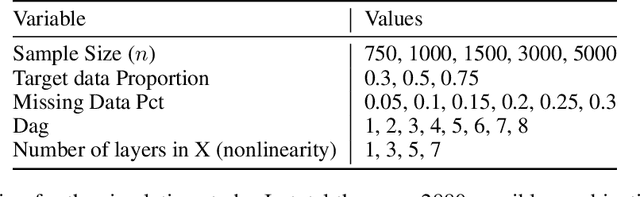
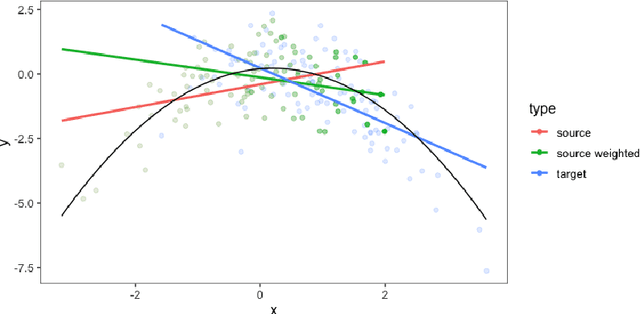
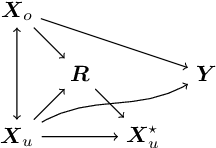
Current domain adaptation methods under missingness shift are restricted to Missing At Random (MAR) missingness mechanisms. However, in many real-world examples, the MAR assumption may be too restrictive. When covariates are Missing Not At Random (MNAR) in both source and target data, the common covariate shift solutions, including importance weighting, are not directly applicable. We show that under reasonable assumptions, the problem of MNAR missingness shift can be reduced to an imputation problem. This allows us to leverage recent methodological developments in both the traditional statistics and machine/deep-learning literature for MNAR imputation to develop a novel domain adaptation procedure for MNAR missingness shift. We further show that our proposed procedure can be extended to handle simultaneous MNAR missingness and covariate shifts. We apply our procedure to Electronic Health Record (EHR) data from two hospitals in south and northeast regions of the US. In this setting we expect different hospital networks and regions to serve different populations and to have different procedures, practices, and software for inputting and recording data, causing simultaneous missingness and covariate shifts.
Cost-Efficient Continual Learning with Sufficient Exemplar Memory
Feb 11, 2025Continual learning (CL) research typically assumes highly constrained exemplar memory resources. However, in many real-world scenarios-especially in the era of large foundation models-memory is abundant, while GPU computational costs are the primary bottleneck. In this work, we investigate CL in a novel setting where exemplar memory is ample (i.e., sufficient exemplar memory). Unlike prior methods designed for strict exemplar memory constraints, we propose a simple yet effective approach that directly operates in the model's weight space through a combination of weight resetting and averaging techniques. Our method achieves state-of-the-art performance while reducing the computational cost to a quarter or third of existing methods. These findings challenge conventional CL assumptions and provide a practical baseline for computationally efficient CL applications.
Leveraging CLIP for Inferring Sensitive Information and Improving Model Fairness
Mar 15, 2024Performance disparities across sub-populations are known to exist in deep learning-based vision recognition models, but previous work has largely addressed such fairness concerns assuming knowledge of sensitive attribute labels. To overcome this reliance, previous strategies have involved separate learning structures to expose and adjust for disparities. In this work, we explore a new paradigm that does not require sensitive attribute labels, and evades the need for extra training by leveraging the vision-language model, CLIP, as a rich knowledge source to infer sensitive information. We present sample clustering based on similarity derived from image and attribute-specified language embeddings and assess their correspondence to true attribute distribution. We train a target model by re-sampling and augmenting under-performed clusters. Extensive experiments on multiple benchmark bias datasets show clear fairness gains of the model over existing baselines, which indicate that CLIP can extract discriminative sensitive information prompted by language, and used to promote model fairness.
Disparate Effect Of Missing Mediators On Transportability of Causal Effects
Mar 13, 2024



Transported mediation effects provide an avenue to understand how upstream interventions (such as improved neighborhood conditions like green spaces) would work differently when applied to different populations as a result of factors that mediate the effects. However, when mediators are missing in the population where the effect is to be transported, these estimates could be biased. We study this issue of missing mediators, motivated by challenges in public health, wherein mediators can be missing, not at random. We propose a sensitivity analysis framework that quantifies the impact of missing mediator data on transported mediation effects. This framework enables us to identify the settings under which the conditional transported mediation effect is rendered insignificant for the subgroup with missing mediator data. Specifically, we provide the bounds on the transported mediation effect as a function of missingness. We then apply the framework to longitudinal data from the Moving to Opportunity Study, a large-scale housing voucher experiment, to quantify the effect of missing mediators on transport effect estimates of voucher receipt, an upstream intervention on living location, in childhood on subsequent risk of mental health or substance use disorder mediated through parental health across sites. Our findings provide a tangible understanding of how much missing data can be withstood for unbiased effect estimates.
Generalization in Healthcare AI: Evaluation of a Clinical Large Language Model
Feb 24, 2024Advances in large language models (LLMs) provide new opportunities in healthcare for improved patient care, clinical decision-making, and enhancement of physician and administrator workflows. However, the potential of these models importantly depends on their ability to generalize effectively across clinical environments and populations, a challenge often underestimated in early development. To better understand reasons for these challenges and inform mitigation approaches, we evaluated ClinicLLM, an LLM trained on [HOSPITAL]'s clinical notes, analyzing its performance on 30-day all-cause readmission prediction focusing on variability across hospitals and patient characteristics. We found poorer generalization particularly in hospitals with fewer samples, among patients with government and unspecified insurance, the elderly, and those with high comorbidities. To understand reasons for lack of generalization, we investigated sample sizes for fine-tuning, note content (number of words per note), patient characteristics (comorbidity level, age, insurance type, borough), and health system aspects (hospital, all-cause 30-day readmission, and mortality rates). We used descriptive statistics and supervised classification to identify features. We found that, along with sample size, patient age, number of comorbidities, and the number of words in notes are all important factors related to generalization. Finally, we compared local fine-tuning (hospital specific), instance-based augmented fine-tuning and cluster-based fine-tuning for improving generalization. Among these, local fine-tuning proved most effective, increasing AUC by 0.25% to 11.74% (most helpful in settings with limited data). Overall, this study provides new insights for enhancing the deployment of large language models in the societally important domain of healthcare, and improving their performance for broader populations.
Impact on Public Health Decision Making by Utilizing Big Data Without Domain Knowledge
Feb 08, 2024New data sources, and artificial intelligence (AI) methods to extract information from them are becoming plentiful, and relevant to decision making in many societal applications. An important example is street view imagery, available in over 100 countries, and considered for applications such as assessing built environment aspects in relation to community health outcomes. Relevant to such uses, important examples of bias in the use of AI are evident when decision-making based on data fails to account for the robustness of the data, or predictions are based on spurious correlations. To study this risk, we utilize 2.02 million GSV images along with health, demographic, and socioeconomic data from New York City. Initially, we demonstrate that built environment characteristics inferred from GSV labels at the intra-city level may exhibit inadequate alignment with the ground truth. We also find that the average individual-level behavior of physical inactivity significantly mediates the impact of built environment features by census tract, as measured through GSV. Finally, using a causal framework which accounts for these mediators of environmental impacts on health, we find that altering 10% of samples in the two lowest tertiles would result in a 4.17 (95% CI 3.84 to 4.55) or 17.2 (95% CI 14.4 to 21.3) times bigger decrease on the prevalence of obesity or diabetes, than the same proportional intervention on the number of crosswalks by census tract. This work illustrates important issues of robustness and model specification for informing effective allocation of interventions using new data sources.
Understanding Disparities in Post Hoc Machine Learning Explanation
Jan 25, 2024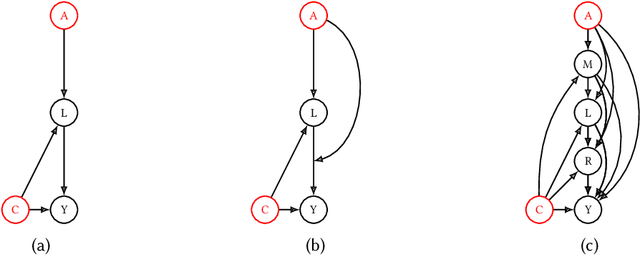
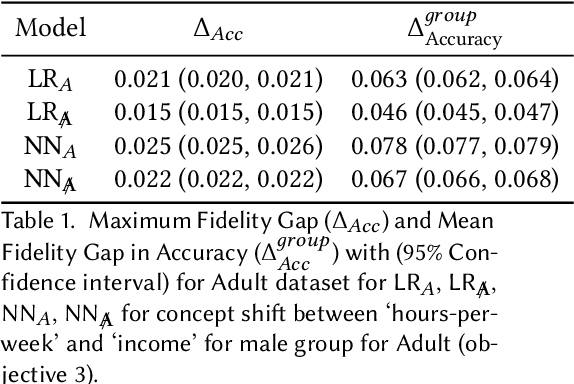
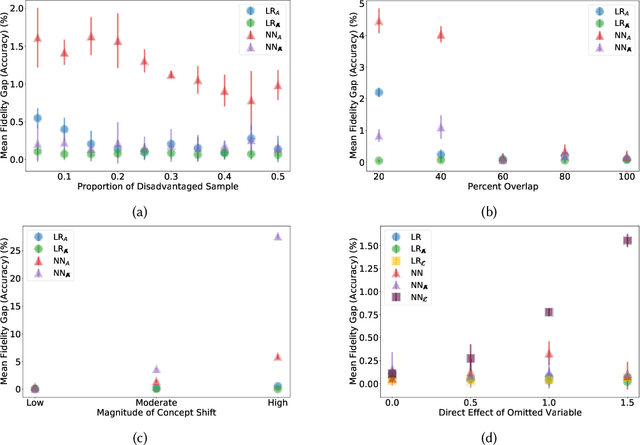
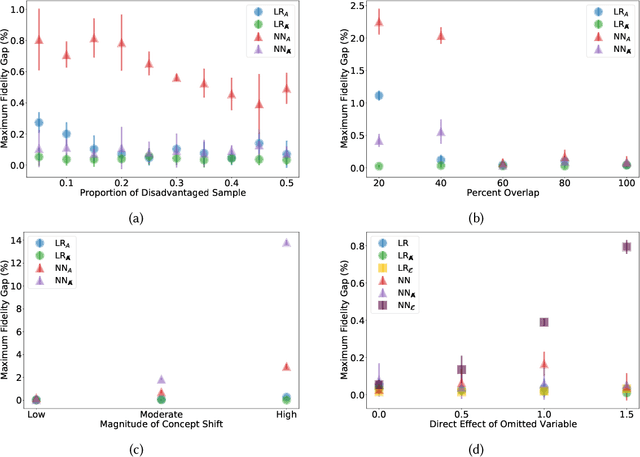
Previous work has highlighted that existing post-hoc explanation methods exhibit disparities in explanation fidelity (across 'race' and 'gender' as sensitive attributes), and while a large body of work focuses on mitigating these issues at the explanation metric level, the role of the data generating process and black box model in relation to explanation disparities remains largely unexplored. Accordingly, through both simulations as well as experiments on a real-world dataset, we specifically assess challenges to explanation disparities that originate from properties of the data: limited sample size, covariate shift, concept shift, omitted variable bias, and challenges based on model properties: inclusion of the sensitive attribute and appropriate functional form. Through controlled simulation analyses, our study demonstrates that increased covariate shift, concept shift, and omission of covariates increase explanation disparities, with the effect pronounced higher for neural network models that are better able to capture the underlying functional form in comparison to linear models. We also observe consistent findings regarding the effect of concept shift and omitted variable bias on explanation disparities in the Adult income dataset. Overall, results indicate that disparities in model explanations can also depend on data and model properties. Based on this systematic investigation, we provide recommendations for the design of explanation methods that mitigate undesirable disparities.
A Brief Tutorial on Sample Size Calculations for Fairness Audits
Dec 07, 2023

In fairness audits, a standard objective is to detect whether a given algorithm performs substantially differently between subgroups. Properly powering the statistical analysis of such audits is crucial for obtaining informative fairness assessments, as it ensures a high probability of detecting unfairness when it exists. However, limited guidance is available on the amount of data necessary for a fairness audit, lacking directly applicable results concerning commonly used fairness metrics. Additionally, the consideration of unequal subgroup sample sizes is also missing. In this tutorial, we address these issues by providing guidance on how to determine the required subgroup sample sizes to maximize the statistical power of hypothesis tests for detecting unfairness. Our findings are applicable to audits of binary classification models and multiple fairness metrics derived as summaries of the confusion matrix. Furthermore, we discuss other aspects of audit study designs that can increase the reliability of audit results.