 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair contrastive pre-training for geographic images
Paper and Code
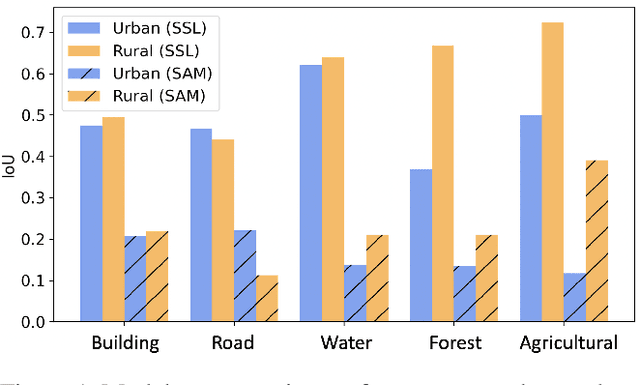

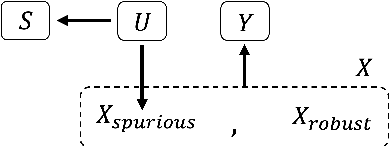

Contrastive representation learning is widely employed in visual recognition for geographic image data (remote-sensing such as satellite imagery or proximal sensing such as street-view imagery), but because of landscape heterogeneity, models can show disparate performance across spatial units. In this work, we consider fairness risks in land-cover semantic segmentation which uses pre-trained representation in contrastive self-supervised learning. We assess class distribution shifts and model prediction disparities across selected sensitive groups: urban and rural scenes for satellite image datasets and city GDP level for a street view image dataset. We propose a mutual information training objective for multi-level latent space. The objective improves feature identification by removing spurious representations of dense local features which are disparately distributed across groups. The method achieves improved fairness results and outperforms state-of-the-art methods in terms of precision-fairness trade-off. In addition, we validate that representations learnt with the proposed method include lowest sensitive information using a linear separation evaluation. This work highlights the need for specific fairness analyses in geographic images, and provides a solution that can be generalized to different self-supervised learning methods or image data. Our code is available at: https://anonymous.4open.science/r/FairDCL-1283