 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Poisoning Attacks on Off-Policy Policy Evaluation Methods
Apr 06, 2024Off-policy Evaluation (OPE) methods are a crucial tool for evaluating policies in high-stakes domains such as healthcare, where exploration is often infeasible, unethical, or expensive. However, the extent to which such methods can be trusted under adversarial threats to data quality is largely unexplored. In this work, we make the first attempt at investigating the sensitivity of OPE methods to marginal adversarial perturbations to the data. We design a generic data poisoning attack framework leveraging influence functions from robust statistics to carefully construct perturbations that maximize error in the policy value estimates. We carry out extensive experimentation with multiple healthcare and control datasets. Our results demonstrate that many existing OPE methods are highly prone to generating value estimates with large errors when subject to data poisoning attacks, even for small adversarial perturbations. These findings question the reliability of policy values derived using OPE methods and motivate the need for developing OPE methods that are statistically robust to train-time data poisoning attacks.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
A hierarchical decomposition for explaining ML performance discrepancies
Feb 22, 2024Machine learning (ML) algorithms can often differ in performance across domains. Understanding $\textit{why}$ their performance differs is crucial for determining what types of interventions (e.g., algorithmic or operational) are most effective at closing the performance gaps. Existing methods focus on $\textit{aggregate decompositions}$ of the total performance gap into the impact of a shift in the distribution of features $p(X)$ versus the impact of a shift in the conditional distribution of the outcome $p(Y|X)$; however, such coarse explanations offer only a few options for how one can close the performance gap. $\textit{Detailed variable-level decompositions}$ that quantify the importance of each variable to each term in the aggregate decomposition can provide a much deeper understanding and suggest much more targeted interventions. However, existing methods assume knowledge of the full causal graph or make strong parametric assumptions. We introduce a nonparametric hierarchical framework that provides both aggregate and detailed decompositions for explaining why the performance of an ML algorithm differs across domains, without requiring causal knowledge. We derive debiased, computationally-efficient estimators, and statistical inference procedures for asymptotically valid confidence intervals.
A Brief Tutorial on Sample Size Calculations for Fairness Audits
Dec 07, 2023

In fairness audits, a standard objective is to detect whether a given algorithm performs substantially differently between subgroups. Properly powering the statistical analysis of such audits is crucial for obtaining informative fairness assessments, as it ensures a high probability of detecting unfairness when it exists. However, limited guidance is available on the amount of data necessary for a fairness audit, lacking directly applicable results concerning commonly used fairness metrics. Additionally, the consideration of unequal subgroup sample sizes is also missing. In this tutorial, we address these issues by providing guidance on how to determine the required subgroup sample sizes to maximize the statistical power of hypothesis tests for detecting unfairness. Our findings are applicable to audits of binary classification models and multiple fairness metrics derived as summaries of the confusion matrix. Furthermore, we discuss other aspects of audit study designs that can increase the reliability of audit results.
Machine Learning for Health symposium 2023 -- Findings track
Dec 01, 2023A collection of the accepted Findings papers that were presented at the 3rd Machine Learning for Health symposium (ML4H 2023), which was held on December 10, 2023, in New Orleans, Louisiana, USA. ML4H 2023 invited high-quality submissions on relevant problems in a variety of health-related disciplines including healthcare, biomedicine, and public health. Two submission tracks were offered: the archival Proceedings track, and the non-archival Findings track. Proceedings were targeted at mature work with strong technical sophistication and a high impact to health. The Findings track looked for new ideas that could spark insightful discussion, serve as valuable resources for the community, or could enable new collaborations. Submissions to the Proceedings track, if not accepted, were automatically considered for the Findings track. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
Towards a Post-Market Monitoring Framework for Machine Learning-based Medical Devices: A case study
Nov 20, 2023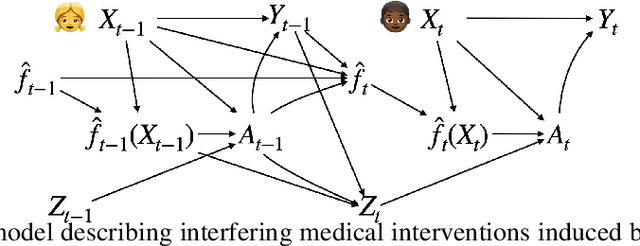
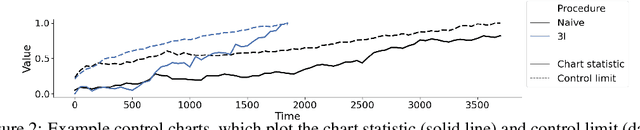
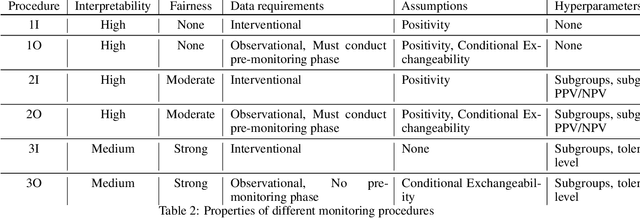
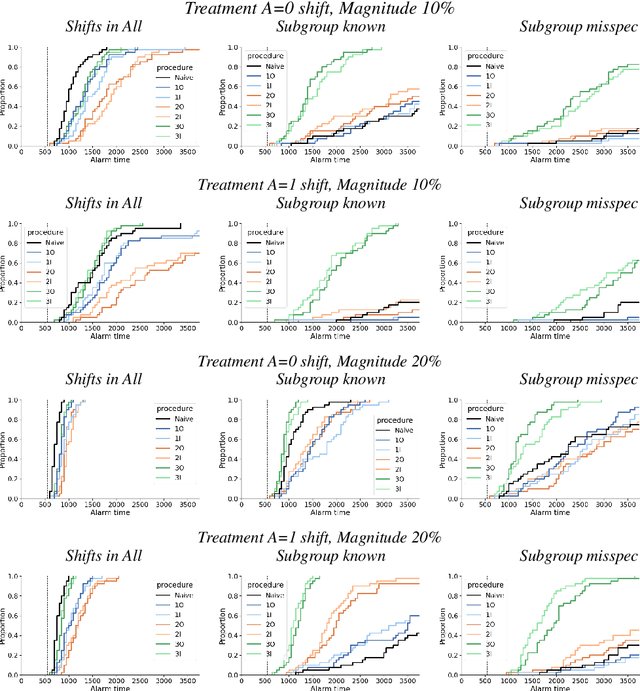
After a machine learning (ML)-based system is deployed in clinical practice, performance monitoring is important to ensure the safety and effectiveness of the algorithm over time. The goal of this work is to highlight the complexity of designing a monitoring strategy and the need for a systematic framework that compares the multitude of monitoring options. One of the main decisions is choosing between using real-world (observational) versus interventional data. Although the former is the most convenient source of monitoring data, it exhibits well-known biases, such as confounding, selection, and missingness. In fact, when the ML algorithm interacts with its environment, the algorithm itself may be a primary source of bias. On the other hand, a carefully designed interventional study that randomizes individuals can explicitly eliminate such biases, but the ethics, feasibility, and cost of such an approach must be carefully considered. Beyond the decision of the data source, monitoring strategies vary in the performance criteria they track, the interpretability of the test statistics, the strength of their assumptions, and their speed at detecting performance decay. As a first step towards developing a framework that compares the various monitoring options, we consider a case study of an ML-based risk prediction algorithm for postoperative nausea and vomiting (PONV). Bringing together tools from causal inference and statistical process control, we walk through the basic steps of defining candidate monitoring criteria, describing potential sources of bias and the causal model, and specifying and comparing candidate monitoring procedures. We hypothesize that these steps can be applied more generally, as causal inference can address other sources of biases as well.
"Why did the Model Fail?": Attributing Model Performance Changes to Distribution Shifts
Oct 19, 2022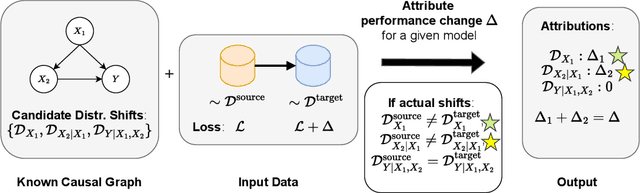

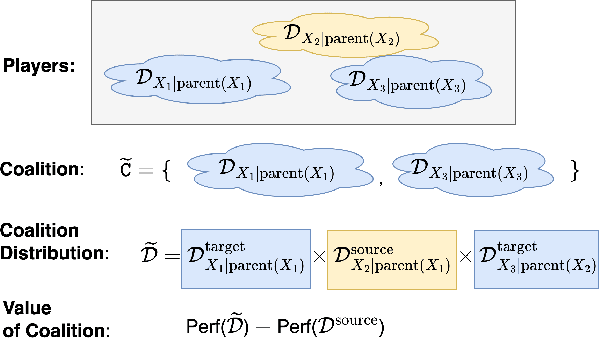
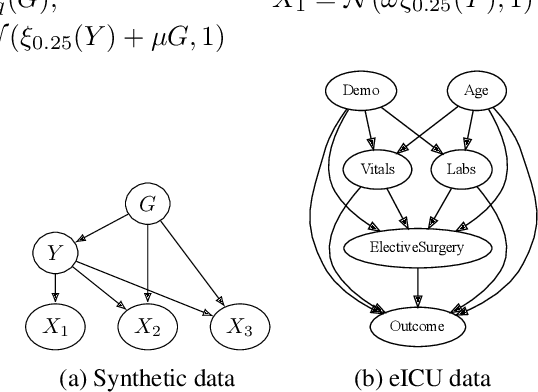
Performance of machine learning models may differ between training and deployment for many reasons. For instance, model performance can change between environments due to changes in data quality, observing a different population than the one in training, or changes in the relationship between labels and features. These manifest as changes to the underlying data generating mechanisms, and thereby result in distribution shifts across environments. Attributing performance changes to specific shifts, such as covariate or concept shifts, is critical for identifying sources of model failures, and for taking mitigating actions that ensure robust models. In this work, we introduce the problem of attributing performance differences between environments to shifts in the underlying data generating mechanisms. We formulate the problem as a cooperative game and derive an importance weighting method for computing the value of a coalition (or a set) of distributions. The contribution of each distribution to the total performance change is then quantified as its Shapley value. We demonstrate the correctness and utility of our method on two synthetic datasets and two real-world case studies, showing its effectiveness in attributing performance changes to a wide range of distribution shifts.
Towards Robust Off-Policy Evaluation via Human Inputs
Sep 18, 2022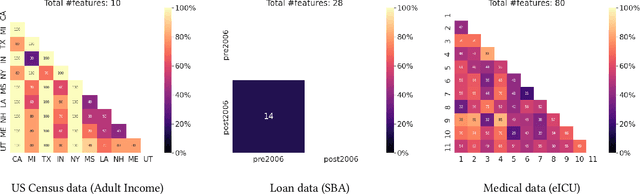

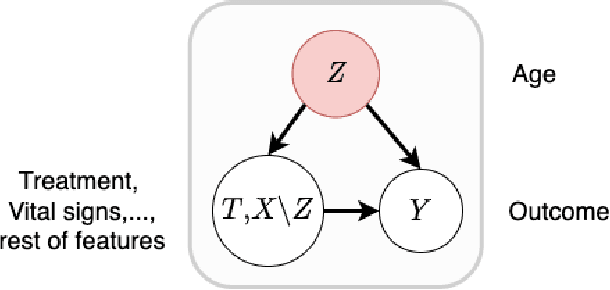
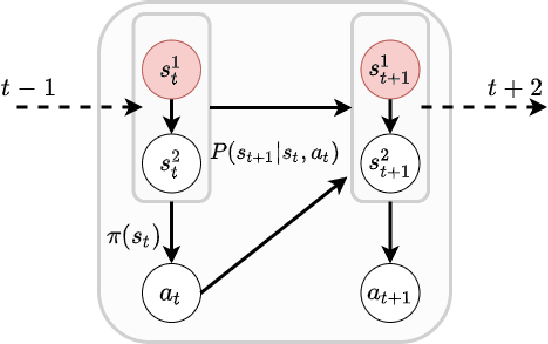
Off-policy Evaluation (OPE) methods are crucial tools for evaluating policies in high-stakes domains such as healthcare, where direct deployment is often infeasible, unethical, or expensive. When deployment environments are expected to undergo changes (that is, dataset shifts), it is important for OPE methods to perform robust evaluation of the policies amidst such changes. Existing approaches consider robustness against a large class of shifts that can arbitrarily change any observable property of the environment. This often results in highly pessimistic estimates of the utilities, thereby invalidating policies that might have been useful in deployment. In this work, we address the aforementioned problem by investigating how domain knowledge can help provide more realistic estimates of the utilities of policies. We leverage human inputs on which aspects of the environments may plausibly change, and adapt the OPE methods to only consider shifts on these aspects. Specifically, we propose a novel framework, Robust OPE (ROPE), which considers shifts on a subset of covariates in the data based on user inputs, and estimates worst-case utility under these shifts. We then develop computationally efficient algorithms for OPE that are robust to the aforementioned shifts for contextual bandits and Markov decision processes. We also theoretically analyze the sample complexity of these algorithms. Extensive experimentation with synthetic and real world datasets from the healthcare domain demonstrates that our approach not only captures realistic dataset shifts accurately, but also results in less pessimistic policy evaluations.
Segmenting across places: The need for fair transfer learning with satellite imagery
Apr 15, 2022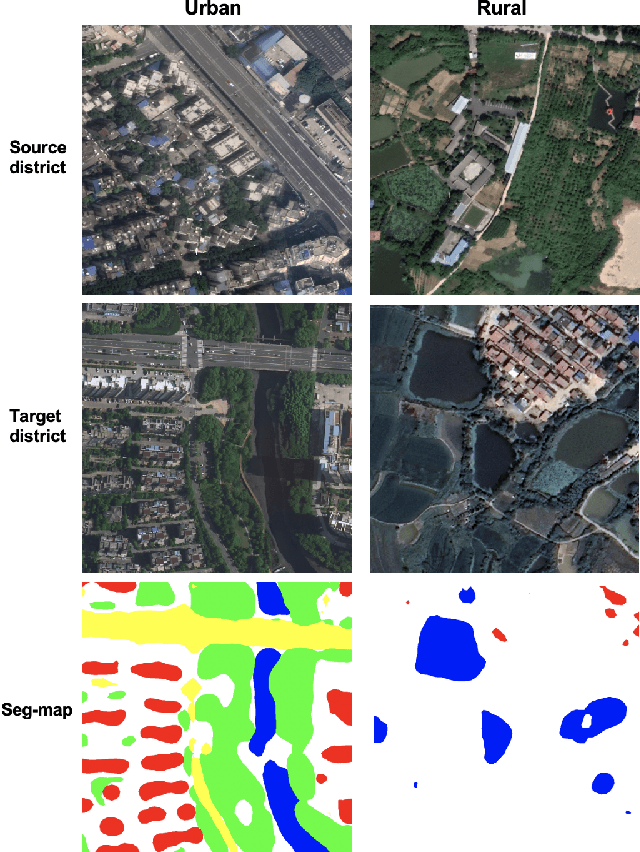
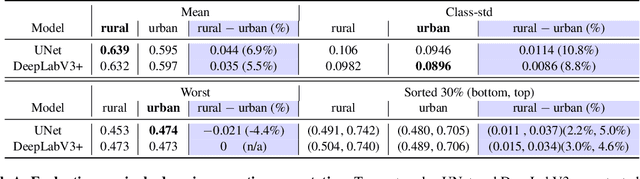
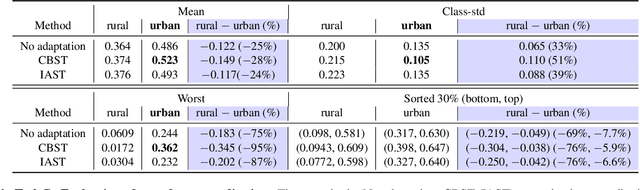
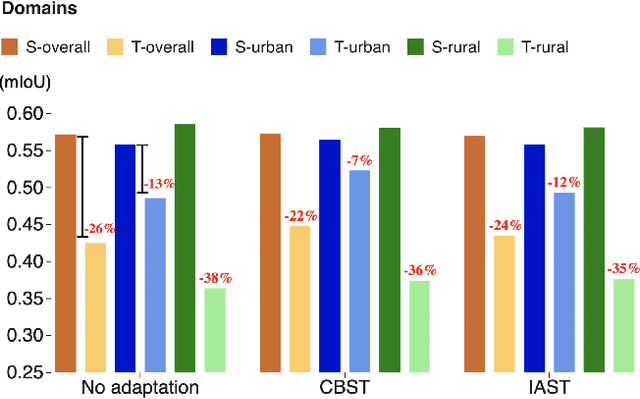
The increasing availability of high-resolution satellite imagery has enabled the use of machine learning to support land-cover measurement and inform policy-making. However, labelling satellite images is expensive and is available for only some locations. This prompts the use of transfer learning to adapt models from data-rich locations to others. Given the potential for high-impact applications of satellite imagery across geographies, a systematic assessment of transfer learning implications is warranted. In this work, we consider the task of land-cover segmentation and study the fairness implications of transferring models across locations. We leverage a large satellite image segmentation benchmark with 5987 images from 18 districts (9 urban and 9 rural). Via fairness metrics we quantify disparities in model performance along two axes -- across urban-rural locations and across land-cover classes. Findings show that state-of-the-art models have better overall accuracy in rural areas compared to urban areas, through unsupervised domain adaptation methods transfer learning better to urban versus rural areas and enlarge fairness gaps. In analysis of reasons for these findings, we show that raw satellite images are overall more dissimilar between source and target districts for rural than for urban locations. This work highlights the need to conduct fairness analysis for satellite imagery segmentation models and motivates the development of methods for fair transfer learning in order not to introduce disparities between places, particularly urban and rural locations.
Learning Under Adversarial and Interventional Shifts
Mar 29, 2021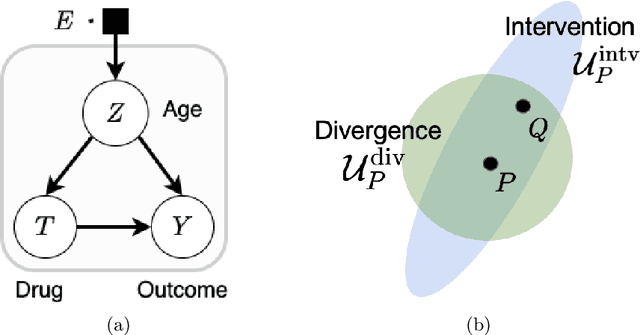
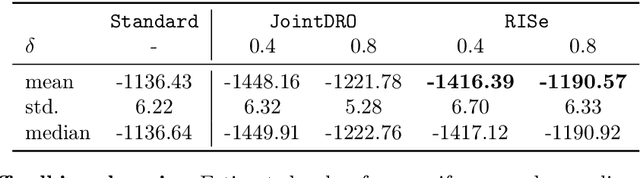
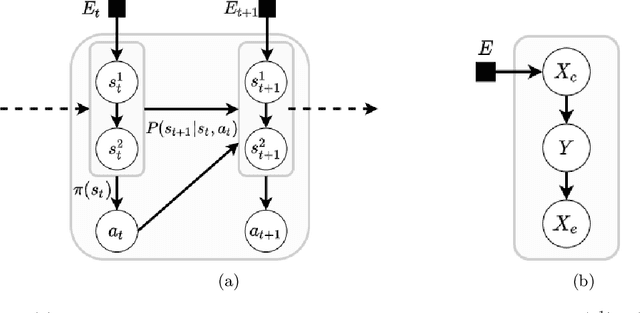
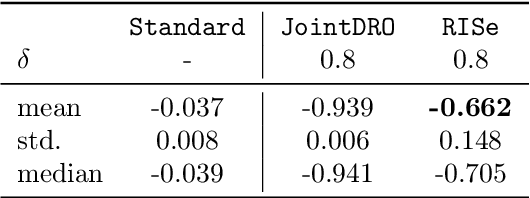
Machine learning models are often trained on data from one distribution and deployed on others. So it becomes important to design models that are robust to distribution shifts. Most of the existing work focuses on optimizing for either adversarial shifts or interventional shifts. Adversarial methods lack expressivity in representing plausible shifts as they consider shifts to joint distributions in the data. Interventional methods allow more expressivity but provide robustness to unbounded shifts, resulting in overly conservative models. In this work, we combine the complementary strengths of the two approaches and propose a new formulation, RISe, for designing robust models against a set of distribution shifts that are at the intersection of adversarial and interventional shifts. We employ the distributionally robust optimization framework to optimize the resulting objective in both supervised and reinforcement learning settings. Extensive experimentation with synthetic and real world datasets from healthcare demonstrate the efficacy of the proposed approach.