 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Why did the Model Fail?": Attributing Model Performance Changes to Distribution Shifts
Paper and Code
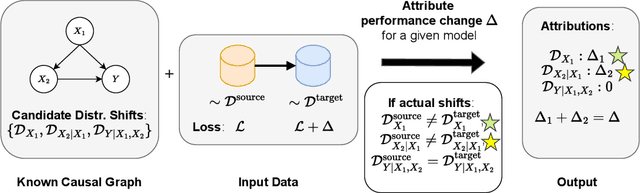

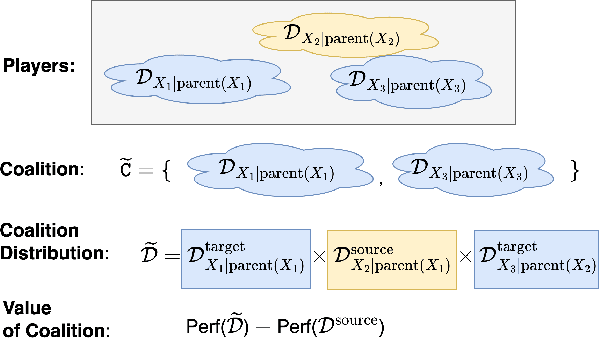
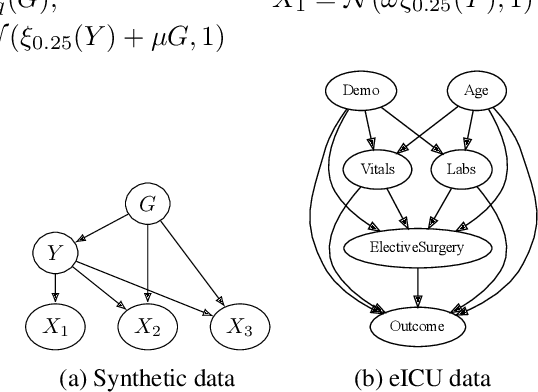
Performance of machine learning models may differ between training and deployment for many reasons. For instance, model performance can change between environments due to changes in data quality, observing a different population than the one in training, or changes in the relationship between labels and features. These manifest as changes to the underlying data generating mechanisms, and thereby result in distribution shifts across environments. Attributing performance changes to specific shifts, such as covariate or concept shifts, is critical for identifying sources of model failures, and for taking mitigating actions that ensure robust models. In this work, we introduce the problem of attributing performance differences between environments to shifts in the underlying data generating mechanisms. We formulate the problem as a cooperative game and derive an importance weighting method for computing the value of a coalition (or a set) of distributions. The contribution of each distribution to the total performance change is then quantified as its Shapley value. We demonstrate the correctness and utility of our method on two synthetic datasets and two real-world case studies, showing its effectiveness in attributing performance changes to a wide range of distribution shifts.