 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Post-Market Monitoring Framework for Machine Learning-based Medical Devices: A case study
Paper and Code
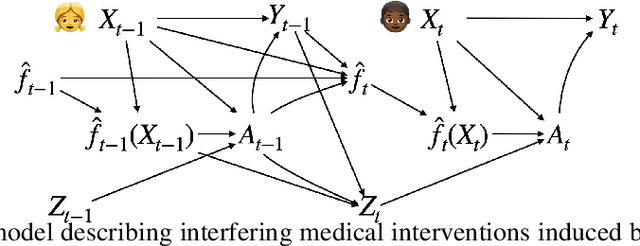
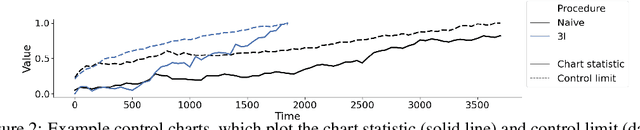
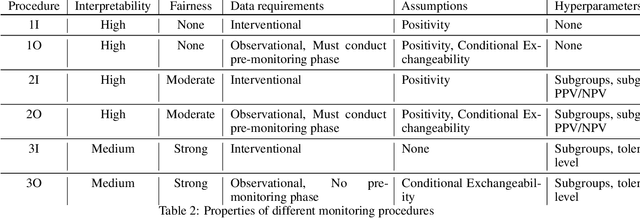
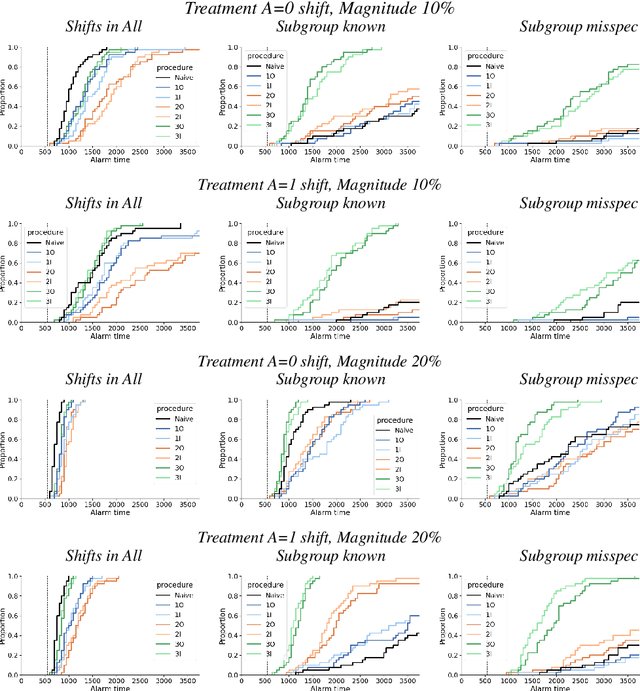
After a machine learning (ML)-based system is deployed in clinical practice, performance monitoring is important to ensure the safety and effectiveness of the algorithm over time. The goal of this work is to highlight the complexity of designing a monitoring strategy and the need for a systematic framework that compares the multitude of monitoring options. One of the main decisions is choosing between using real-world (observational) versus interventional data. Although the former is the most convenient source of monitoring data, it exhibits well-known biases, such as confounding, selection, and missingness. In fact, when the ML algorithm interacts with its environment, the algorithm itself may be a primary source of bias. On the other hand, a carefully designed interventional study that randomizes individuals can explicitly eliminate such biases, but the ethics, feasibility, and cost of such an approach must be carefully considered. Beyond the decision of the data source, monitoring strategies vary in the performance criteria they track, the interpretability of the test statistics, the strength of their assumptions, and their speed at detecting performance decay. As a first step towards developing a framework that compares the various monitoring options, we consider a case study of an ML-based risk prediction algorithm for postoperative nausea and vomiting (PONV). Bringing together tools from causal inference and statistical process control, we walk through the basic steps of defining candidate monitoring criteria, describing potential sources of bias and the causal model, and specifying and comparing candidate monitoring procedures. We hypothesize that these steps can be applied more generally, as causal inference can address other sources of biases as well.