 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than "Means to an End": Supporting Reasoning with Transparently Designed AI Data Science Processes
Mar 25, 2026Generative artificial intelligence (AI) tools can now help people perform complex data science tasks regardless of their expertise. While these tools have great potential to help more people work with data, their end-to-end approach does not support users in evaluating alternative approaches and reformulating problems, both critical to solving open-ended tasks in high-stakes domains. In this paper, we reflect on two AI data science systems designed for the medical setting and how they function as tools for thought. We find that success in these systems was driven by constructing AI workflows around intentionally-designed intermediate artifacts, such as readable query languages, concept definitions, or input-output examples. Despite opaqueness in other parts of the AI process, these intermediates helped users reason about important analytical choices, refine their initial questions, and contribute their unique knowledge. We invite the HCI community to consider when and how intermediate artifacts should be designed to promote effective data science thinking.
Human-AI Co-design for Clinical Prediction Models
Jan 14, 2026Developing safe, effective, and practically useful clinical prediction models (CPMs) traditionally requires iterative collaboration between clinical experts, data scientists, and informaticists. This process refines the often small but critical details of the model building process, such as which features/patients to include and how clinical categories should be defined. However, this traditional collaboration process is extremely time- and resource-intensive, resulting in only a small fraction of CPMs reaching clinical practice. This challenge intensifies when teams attempt to incorporate unstructured clinical notes, which can contain an enormous number of concepts. To address this challenge, we introduce HACHI, an iterative human-in-the-loop framework that uses AI agents to accelerate the development of fully interpretable CPMs by enabling the exploration of concepts in clinical notes. HACHI alternates between (i) an AI agent rapidly exploring and evaluating candidate concepts in clinical notes and (ii) clinical and domain experts providing feedback to improve the CPM learning process. HACHI defines concepts as simple yes-no questions that are used in linear models, allowing the clinical AI team to transparently review, refine, and validate the CPM learned in each round. In two real-world prediction tasks (acute kidney injury and traumatic brain injury), HACHI outperforms existing approaches, surfaces new clinically relevant concepts not included in commonly-used CPMs, and improves model generalizability across clinical sites and time periods. Furthermore, HACHI reveals the critical role of the clinical AI team, such as directing the AI agent to explore concepts that it had not previously considered, adjusting the granularity of concepts it considers, changing the objective function to better align with the clinical objectives, and identifying issues of data bias and leakage.
Realistic CDSS Drug Dosing with End-to-end Recurrent Q-learning for Dual Vasopressor Control
Oct 01, 2025Reinforcement learning (RL) applications in Clinical Decision Support Systems (CDSS) frequently encounter skepticism from practitioners regarding inoperable dosing decisions. We address this challenge with an end-to-end approach for learning optimal drug dosing and control policies for dual vasopressor administration in intensive care unit (ICU) patients with septic shock. For realistic drug dosing, we apply action space design that accommodates discrete, continuous, and directional dosing strategies in a system that combines offline conservative Q-learning with a novel recurrent modeling in a replay buffer to capture temporal dependencies in ICU time-series data. Our comparative analysis of norepinephrine dosing strategies across different action space formulations reveals that the designed action spaces improve interpretability and facilitate clinical adoption while preserving efficacy. Empirical results1 on eICU and MIMIC demonstrate that action space design profoundly influences learned behavioral policies. The proposed methods achieve improved patient outcomes of over 15% in survival improvement probability, while aligning with established clinical protocols.
When the Domain Expert Has No Time and the LLM Developer Has No Clinical Expertise: Real-World Lessons from LLM Co-Design in a Safety-Net Hospital
Aug 11, 2025Large language models (LLMs) have the potential to address social and behavioral determinants of health by transforming labor intensive workflows in resource-constrained settings. Creating LLM-based applications that serve the needs of underserved communities requires a deep understanding of their local context, but it is often the case that neither LLMs nor their developers possess this local expertise, and the experts in these communities often face severe time/resource constraints. This creates a disconnect: how can one engage in meaningful co-design of an LLM-based application for an under-resourced community when the communication channel between the LLM developer and domain expert is constrained? We explored this question through a real-world case study, in which our data science team sought to partner with social workers at a safety net hospital to build an LLM application that summarizes patients' social needs. Whereas prior works focus on the challenge of prompt tuning, we found that the most critical challenge in this setting is the careful and precise specification of \what information to surface to providers so that the LLM application is accurate, comprehensive, and verifiable. Here we present a novel co-design framework for settings with limited access to domain experts, in which the summary generation task is first decomposed into individually-optimizable attributes and then each attribute is efficiently refined and validated through a multi-tier cascading approach.
Judging LLMs on a Simplex
May 28, 2025Automated evaluation of free-form outputs from large language models (LLMs) is challenging because many distinct answers can be equally valid. A common practice is to use LLMs themselves as judges, but the theoretical properties of this approach are not yet well understood. We show that a geometric framework that represents both judges and candidates as points on a probability simplex can provide helpful insight on what is or is not identifiable using LLM judges. Our theoretical analysis uncovers a "phase transition" in ranking identifiability: for binary scoring systems, true rankings are identifiable even with weak judges under mild assumptions, while rankings become non-identifiable for three or more scoring levels even with infinite data, absent additional prior knowledge. This non-identifiability highlights how uncertainty in rankings stems from not only aleatoric uncertainty (i.e., inherent stochasticity in the data) but also epistemic uncertainty regarding which assumptions hold, an aspect that has received limited attention until now. To integrate both types of uncertainty, we use Bayesian inference to encode assumptions as priors and conduct sensitivity analysis of ranking estimates and credible intervals. Empirical evaluations across multiple benchmarks demonstrate that Bayesian inference yields more accurate rankings and substantially improves coverage rates. These results underscore the importance of taking a more holistic approach to uncertainty quantification when using LLMs as judges.
Bayesian Concept Bottleneck Models with LLM Priors
Oct 21, 2024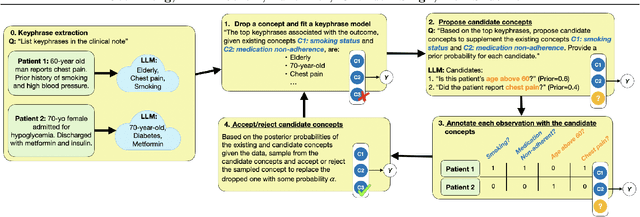
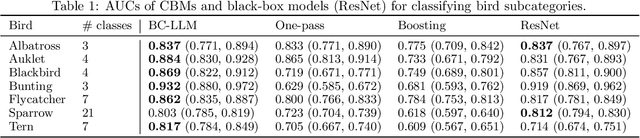
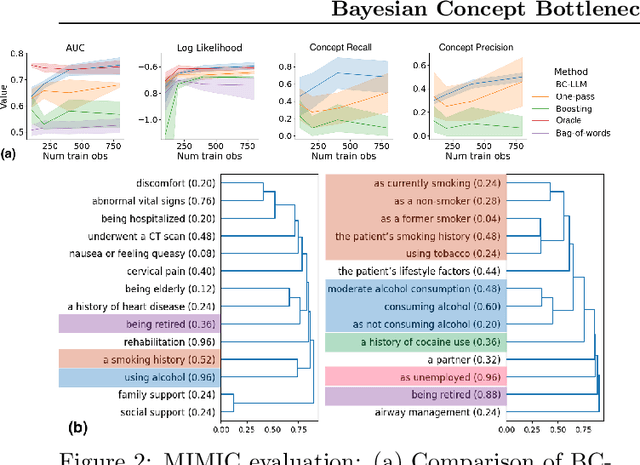
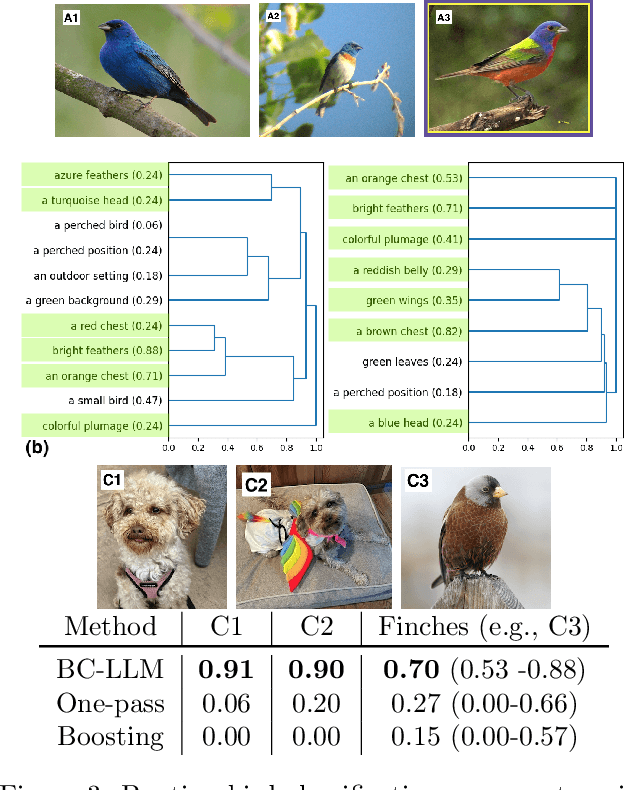
Concept Bottleneck Models (CBMs) have been proposed as a compromise between white-box and black-box models, aiming to achieve interpretability without sacrificing accuracy. The standard training procedure for CBMs is to predefine a candidate set of human-interpretable concepts, extract their values from the training data, and identify a sparse subset as inputs to a transparent prediction model. However, such approaches are often hampered by the tradeoff between enumerating a sufficiently large set of concepts to include those that are truly relevant versus controlling the cost of obtaining concept extractions. This work investigates a novel approach that sidesteps these challenges: BC-LLM iteratively searches over a potentially infinite set of concepts within a Bayesian framework, in which Large Language Models (LLMs) serve as both a concept extraction mechanism and prior. BC-LLM is broadly applicable and multi-modal. Despite imperfections in LLMs, we prove that BC-LLM can provide rigorous statistical inference and uncertainty quantification. In experiments, it outperforms comparator methods including black-box models, converges more rapidly towards relevant concepts and away from spuriously correlated ones, and is more robust to out-of-distribution samples.
A hierarchical decomposition for explaining ML performance discrepancies
Feb 22, 2024Machine learning (ML) algorithms can often differ in performance across domains. Understanding $\textit{why}$ their performance differs is crucial for determining what types of interventions (e.g., algorithmic or operational) are most effective at closing the performance gaps. Existing methods focus on $\textit{aggregate decompositions}$ of the total performance gap into the impact of a shift in the distribution of features $p(X)$ versus the impact of a shift in the conditional distribution of the outcome $p(Y|X)$; however, such coarse explanations offer only a few options for how one can close the performance gap. $\textit{Detailed variable-level decompositions}$ that quantify the importance of each variable to each term in the aggregate decomposition can provide a much deeper understanding and suggest much more targeted interventions. However, existing methods assume knowledge of the full causal graph or make strong parametric assumptions. We introduce a nonparametric hierarchical framework that provides both aggregate and detailed decompositions for explaining why the performance of an ML algorithm differs across domains, without requiring causal knowledge. We derive debiased, computationally-efficient estimators, and statistical inference procedures for asymptotically valid confidence intervals.
A Brief Tutorial on Sample Size Calculations for Fairness Audits
Dec 07, 2023

In fairness audits, a standard objective is to detect whether a given algorithm performs substantially differently between subgroups. Properly powering the statistical analysis of such audits is crucial for obtaining informative fairness assessments, as it ensures a high probability of detecting unfairness when it exists. However, limited guidance is available on the amount of data necessary for a fairness audit, lacking directly applicable results concerning commonly used fairness metrics. Additionally, the consideration of unequal subgroup sample sizes is also missing. In this tutorial, we address these issues by providing guidance on how to determine the required subgroup sample sizes to maximize the statistical power of hypothesis tests for detecting unfairness. Our findings are applicable to audits of binary classification models and multiple fairness metrics derived as summaries of the confusion matrix. Furthermore, we discuss other aspects of audit study designs that can increase the reliability of audit results.
Towards a Post-Market Monitoring Framework for Machine Learning-based Medical Devices: A case study
Nov 20, 2023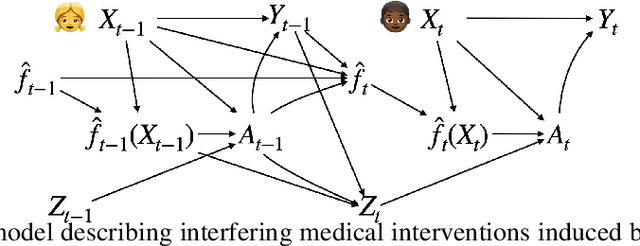
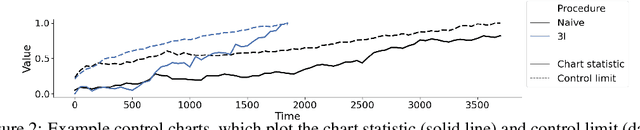
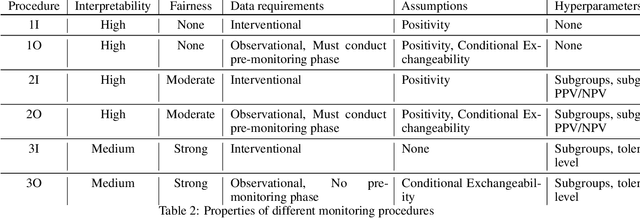
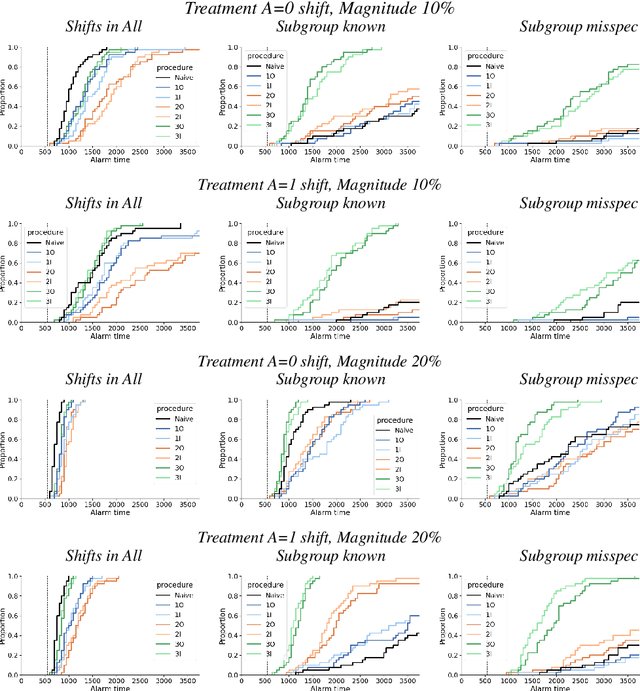
After a machine learning (ML)-based system is deployed in clinical practice, performance monitoring is important to ensure the safety and effectiveness of the algorithm over time. The goal of this work is to highlight the complexity of designing a monitoring strategy and the need for a systematic framework that compares the multitude of monitoring options. One of the main decisions is choosing between using real-world (observational) versus interventional data. Although the former is the most convenient source of monitoring data, it exhibits well-known biases, such as confounding, selection, and missingness. In fact, when the ML algorithm interacts with its environment, the algorithm itself may be a primary source of bias. On the other hand, a carefully designed interventional study that randomizes individuals can explicitly eliminate such biases, but the ethics, feasibility, and cost of such an approach must be carefully considered. Beyond the decision of the data source, monitoring strategies vary in the performance criteria they track, the interpretability of the test statistics, the strength of their assumptions, and their speed at detecting performance decay. As a first step towards developing a framework that compares the various monitoring options, we consider a case study of an ML-based risk prediction algorithm for postoperative nausea and vomiting (PONV). Bringing together tools from causal inference and statistical process control, we walk through the basic steps of defining candidate monitoring criteria, describing potential sources of bias and the causal model, and specifying and comparing candidate monitoring procedures. We hypothesize that these steps can be applied more generally, as causal inference can address other sources of biases as well.
Is this model reliable for everyone? Testing for strong calibration
Jul 28, 2023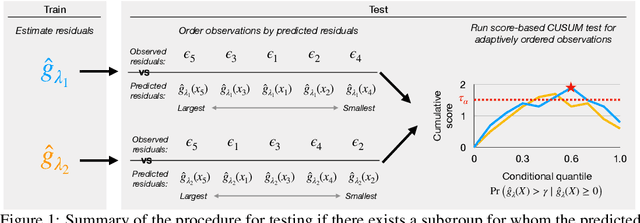

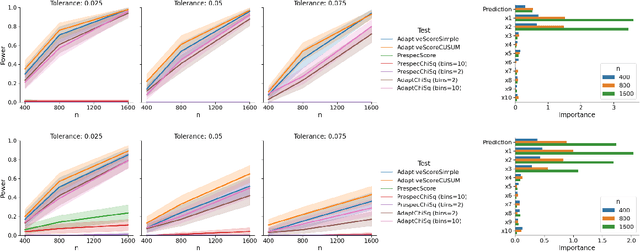
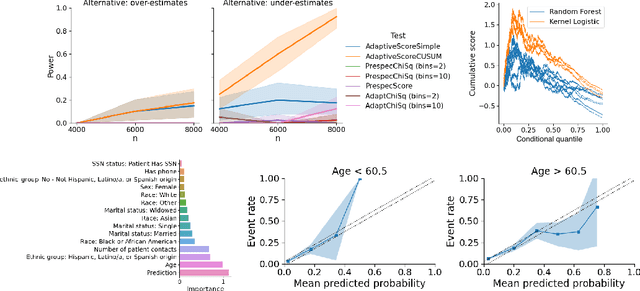
In a well-calibrated risk prediction model, the average predicted probability is close to the true event rate for any given subgroup. Such models are reliable across heterogeneous populations and satisfy strong notions of algorithmic fairness. However, the task of auditing a model for strong calibration is well-known to be difficult -- particularly for machine learning (ML) algorithms -- due to the sheer number of potential subgroups. As such, common practice is to only assess calibration with respect to a few predefined subgroups. Recent developments in goodness-of-fit testing offer potential solutions but are not designed for settings with weak signal or where the poorly calibrated subgroup is small, as they either overly subdivide the data or fail to divide the data at all. We introduce a new testing procedure based on the following insight: if we can reorder observations by their expected residuals, there should be a change in the association between the predicted and observed residuals along this sequence if a poorly calibrated subgroup exists. This lets us reframe the problem of calibration testing into one of changepoint detection, for which powerful methods already exist. We begin with introducing a sample-splitting procedure where a portion of the data is used to train a suite of candidate models for predicting the residual, and the remaining data are used to perform a score-based cumulative sum (CUSUM) test. To further improve power, we then extend this adaptive CUSUM test to incorporate cross-validation, while maintaining Type I error control under minimal assumptions. Compared to existing methods, the proposed procedure consistently achieved higher power in simulation studies and more than doubled the power when auditing a mortality risk prediction model.