 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Concept Bottleneck Models with LLM Priors
Oct 21, 2024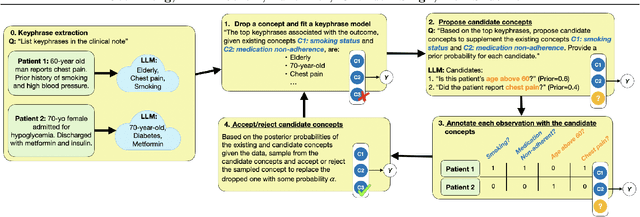
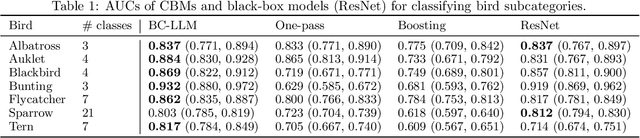
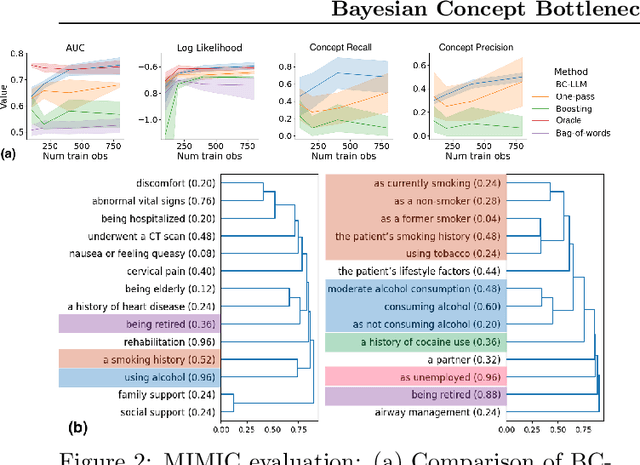
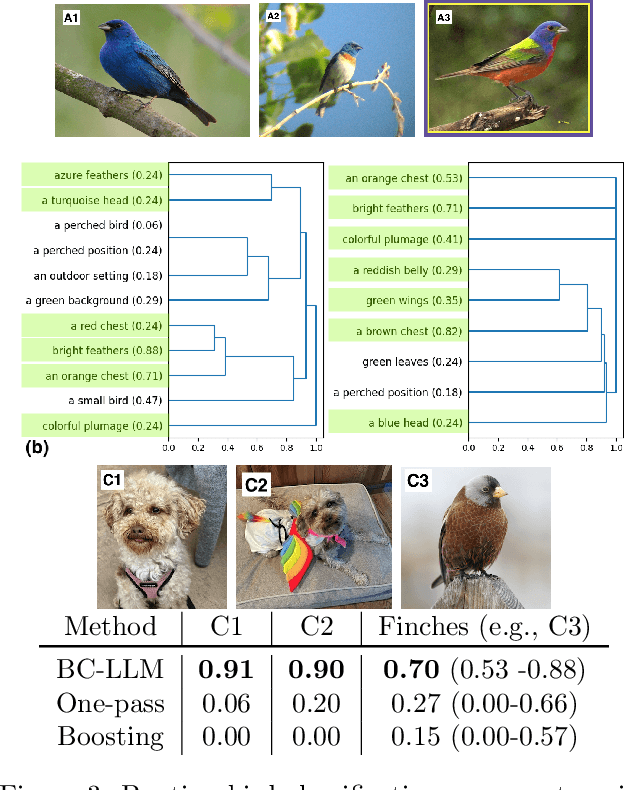
Concept Bottleneck Models (CBMs) have been proposed as a compromise between white-box and black-box models, aiming to achieve interpretability without sacrificing accuracy. The standard training procedure for CBMs is to predefine a candidate set of human-interpretable concepts, extract their values from the training data, and identify a sparse subset as inputs to a transparent prediction model. However, such approaches are often hampered by the tradeoff between enumerating a sufficiently large set of concepts to include those that are truly relevant versus controlling the cost of obtaining concept extractions. This work investigates a novel approach that sidesteps these challenges: BC-LLM iteratively searches over a potentially infinite set of concepts within a Bayesian framework, in which Large Language Models (LLMs) serve as both a concept extraction mechanism and prior. BC-LLM is broadly applicable and multi-modal. Despite imperfections in LLMs, we prove that BC-LLM can provide rigorous statistical inference and uncertainty quantification. In experiments, it outperforms comparator methods including black-box models, converges more rapidly towards relevant concepts and away from spuriously correlated ones, and is more robust to out-of-distribution samples.