 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFN-TS: Thompson Sampling for Contextual Bandits via Prior-Data Fitted Networks
May 11, 2026Thompson sampling is a widely used strategy for contextual bandits: at each round, it samples a reward function from a Bayesian posterior and acts greedily under that sample. Prior-data fitted networks (PFNs), such as TabPFN v2+ and TabICL v2, are attractive candidates for this purpose because they approximate Bayesian posterior predictive distributions in a single forward pass. However, PFNs predict noisy future rewards, while Thompson sampling requires uncertainty over the latent mean reward function. We propose PFN-TS, a Thompson sampling algorithm that converts PFN posterior predictives into mean-reward samples using a subsampled predictive central limit theorem. The method estimates posterior variance from a geometric grid of $O(\log n)$ dataset prefixes rather than the full $O(n)$ predictive sequence used in previous predictive-sequence approaches, and reuses TabICL's cached representations across rounds. We prove consistency of the subsampled variance estimator and give a Bayesian regret bound that decomposes PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms. Empirically, PFN-TS achieves the best average rank across nonlinear synthetic and OpenML classification-to-bandit benchmarks, remains competitive on linear and BART-generated rewards, and attains the highest estimated policy value in an offline mobile-health evaluation. Code is available at https://anonymous.4open.science/r/PFN_TS-36ED/.
Agentic-imodels: Evolving agentic interpretability tools via autoresearch
May 05, 2026Agentic data science (ADS) systems are rapidly improving their capability to autonomously analyze, fit, and interpret data, potentially moving towards a future where agents conduct the vast majority of data-science work. However, current ADS systems use statistical tools designed to be interpretable by humans, rather than interpretable by agents. To address this, we introduce Agentic-imodels, an agentic autoresearch loop that evolves data-science tools designed to be interpretable by agents. Specifically, it develops a library of scikit-learn-compatible regressors for tabular data that are optimized for both predictive performance and a novel LLM-based interpretability metric. The metric measures a suite of LLM-graded tests that probe whether a fitted model's string representation is "simulatable" by an LLM, i.e. whether the LLM can answer questions about the model's behavior by reading its string output alone. We find that the evolved models jointly improve predictive performance and agent-facing interpretability, generalizing to new datasets and new interpretability tests. Furthermore, these evolved models improve downstream end-to-end ADS, increasing performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%
On the Statistical Optimality of Optimal Decision Trees
Mar 05, 2026While globally optimal empirical risk minimization (ERM) decision trees have become computationally feasible and empirically successful, rigorous theoretical guarantees for their statistical performance remain limited. In this work, we develop a comprehensive statistical theory for ERM trees under random design in both high-dimensional regression and classification. We first establish sharp oracle inequalities that bound the excess risk of the ERM estimator relative to the best possible approximation achievable by any tree with at most $L$ leaves, thereby characterizing the interpretability-accuracy trade-off. We derive these results using a novel uniform concentration framework based on empirically localized Rademacher complexity. Furthermore, we derive minimax optimal rates over a novel function class: the piecewise sparse heterogeneous anisotropic Besov (PSHAB) space. This space explicitly captures three key structural features encountered in practice: sparsity, anisotropic smoothness, and spatial heterogeneity. While our main results are established under sub-Gaussianity, we also provide robust guarantees that hold under heavy-tailed noise settings. Together, these findings provide a principled foundation for the optimality of ERM trees and introduce empirical process tools broadly applicable to other highly adaptive, data-driven procedures.
BFTS: Thompson Sampling with Bayesian Additive Regression Trees
Feb 08, 2026Contextual bandits are a core technology for personalized mobile health interventions, where decision-making requires adapting to complex, non-linear user behaviors. While Thompson Sampling (TS) is a preferred strategy for these problems, its performance hinges on the quality of the underlying reward model. Standard linear models suffer from high bias, while neural network approaches are often brittle and difficult to tune in online settings. Conversely, tree ensembles dominate tabular data prediction but typically rely on heuristic uncertainty quantification, lacking a principled probabilistic basis for TS. We propose Bayesian Forest Thompson Sampling (BFTS), the first contextual bandit algorithm to integrate Bayesian Additive Regression Trees (BART), a fully probabilistic sum-of-trees model, directly into the exploration loop. We prove that BFTS is theoretically sound, deriving an information-theoretic Bayesian regret bound of $\tilde{O}(\sqrt{T})$. As a complementary result, we establish frequentist minimax optimality for a "feel-good" variant, confirming the structural suitability of BART priors for non-parametric bandits. Empirically, BFTS achieves state-of-the-art regret on tabular benchmarks with near-nominal uncertainty calibration. Furthermore, in an offline policy evaluation on the Drink Less micro-randomized trial, BFTS improves engagement rates by over 30% compared to the deployed policy, demonstrating its practical effectiveness for behavioral interventions.
TabClustPFN: A Prior-Fitted Network for Tabular Data Clustering
Jan 29, 2026Clustering tabular data is a fundamental yet challenging problem due to heterogeneous feature types, diverse data-generating mechanisms, and the absence of transferable inductive biases across datasets. Prior-fitted networks (PFNs) have recently demonstrated strong generalization in supervised tabular learning by amortizing Bayesian inference under a broad synthetic prior. Extending this paradigm to clustering is nontrivial: clustering is unsupervised, admits a combinatorial and permutation-invariant output space, and requires inferring the number of clusters. We introduce TabClustPFN, a prior-fitted network for tabular data clustering that performs amortized Bayesian inference over both cluster assignments and cluster cardinality. Pretrained on synthetic datasets drawn from a flexible clustering prior, TabClustPFN clusters unseen datasets in a single forward pass, without dataset-specific retraining or hyperparameter tuning. The model naturally handles heterogeneous numerical and categorical features and adapts to a wide range of clustering structures. Experiments on synthetic data and curated real-world tabular benchmarks show that TabClustPFN outperforms classical, deep, and amortized clustering baselines, while exhibiting strong robustness in out-of-the-box exploratory settings. Code is available at https://github.com/Tianqi-Zhao/TabClustPFN.
Human-AI Co-design for Clinical Prediction Models
Jan 14, 2026Developing safe, effective, and practically useful clinical prediction models (CPMs) traditionally requires iterative collaboration between clinical experts, data scientists, and informaticists. This process refines the often small but critical details of the model building process, such as which features/patients to include and how clinical categories should be defined. However, this traditional collaboration process is extremely time- and resource-intensive, resulting in only a small fraction of CPMs reaching clinical practice. This challenge intensifies when teams attempt to incorporate unstructured clinical notes, which can contain an enormous number of concepts. To address this challenge, we introduce HACHI, an iterative human-in-the-loop framework that uses AI agents to accelerate the development of fully interpretable CPMs by enabling the exploration of concepts in clinical notes. HACHI alternates between (i) an AI agent rapidly exploring and evaluating candidate concepts in clinical notes and (ii) clinical and domain experts providing feedback to improve the CPM learning process. HACHI defines concepts as simple yes-no questions that are used in linear models, allowing the clinical AI team to transparently review, refine, and validate the CPM learned in each round. In two real-world prediction tasks (acute kidney injury and traumatic brain injury), HACHI outperforms existing approaches, surfaces new clinically relevant concepts not included in commonly-used CPMs, and improves model generalizability across clinical sites and time periods. Furthermore, HACHI reveals the critical role of the clinical AI team, such as directing the AI agent to explore concepts that it had not previously considered, adjusting the granularity of concepts it considers, changing the objective function to better align with the clinical objectives, and identifying issues of data bias and leakage.
Revisiting Randomization in Greedy Model Search
Jun 18, 2025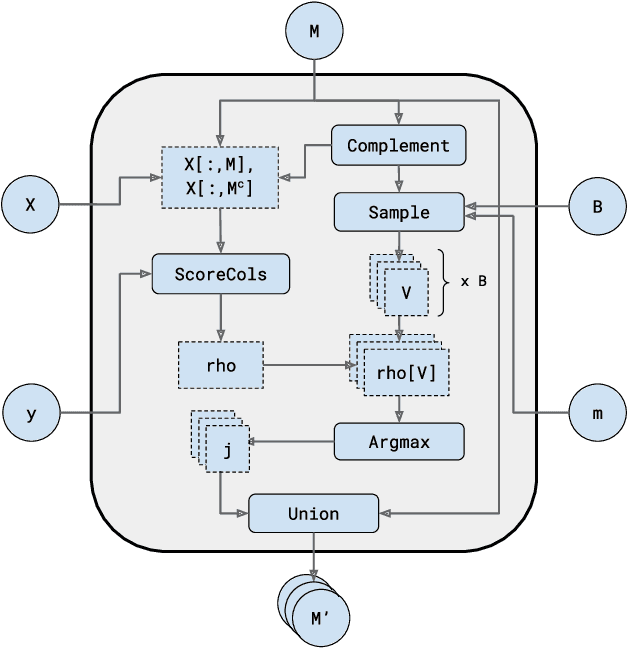
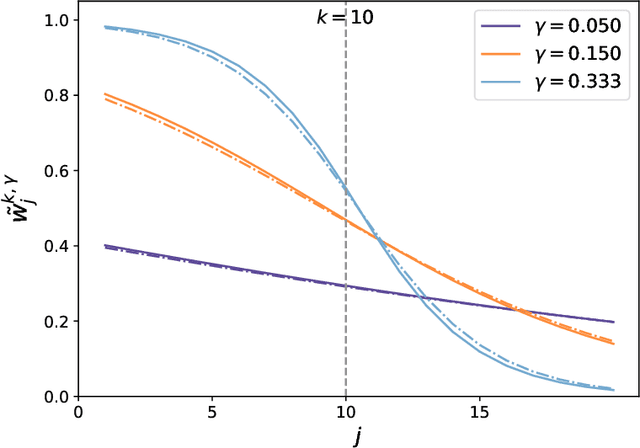
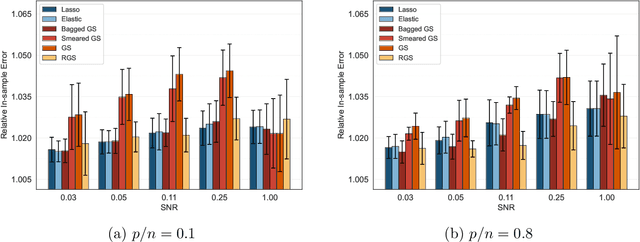
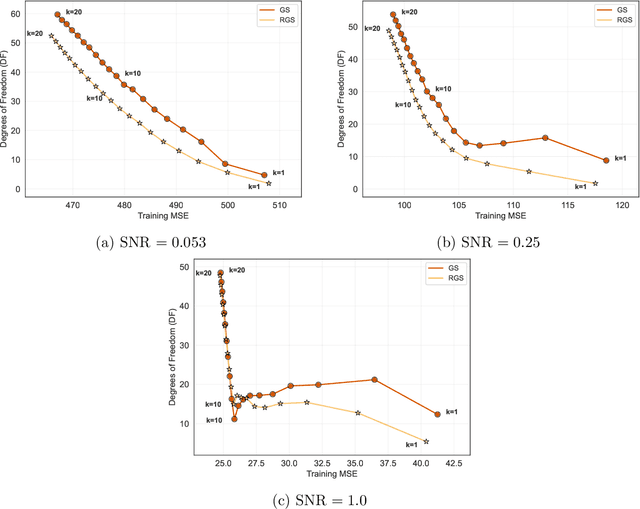
Combining randomized estimators in an ensemble, such as via random forests, has become a fundamental technique in modern data science, but can be computationally expensive. Furthermore, the mechanism by which this improves predictive performance is poorly understood. We address these issues in the context of sparse linear regression by proposing and analyzing an ensemble of greedy forward selection estimators that are randomized by feature subsampling -- at each iteration, the best feature is selected from within a random subset. We design a novel implementation based on dynamic programming that greatly improves its computational efficiency. Furthermore, we show via careful numerical experiments that our method can outperform popular methods such as lasso and elastic net across a wide range of settings. Next, contrary to prevailing belief that randomized ensembling is analogous to shrinkage, we show via numerical experiments that it can simultaneously reduce training error and degrees of freedom, thereby shifting the entire bias-variance trade-off curve of the base estimator. We prove this fact rigorously in the setting of orthogonal features, in which case, the ensemble estimator rescales the ordinary least squares coefficients with a two-parameter family of logistic weights, thereby enlarging the model search space. These results enhance our understanding of random forests and suggest that implicit regularization in general may have more complicated effects than explicit regularization.
TabPFN: One Model to Rule Them All?
May 26, 2025Hollmann et al. (Nature 637 (2025) 319-326) recently introduced TabPFN, a transformer-based deep learning model for regression and classification on tabular data, which they claim "outperforms all previous methods on datasets with up to 10,000 samples by a wide margin, using substantially less training time." Furthermore, they have called TabPFN a "foundation model" for tabular data, as it can support "data generation, density estimation, learning reusable embeddings and fine-tuning". If these statements are well-supported, TabPFN may have the potential to supersede existing modeling approaches on a wide range of statistical tasks, mirroring a similar revolution in other areas of artificial intelligence that began with the advent of large language models. In this paper, we provide a tailored explanation of how TabPFN works for a statistics audience, by emphasizing its interpretation as approximate Bayesian inference. We also provide more evidence of TabPFN's "foundation model" capabilities: We show that an out-of-the-box application of TabPFN vastly outperforms specialized state-of-the-art methods for semi-supervised parameter estimation, prediction under covariate shift, and heterogeneous treatment effect estimation. We further show that TabPFN can outperform LASSO at sparse regression and can break a robustness-efficiency trade-off in classification. All experiments can be reproduced using the code provided at https://github.com/qinglong-tian/tabpfn_study (https://github.com/qinglong-tian/tabpfn_study).
Bayesian Concept Bottleneck Models with LLM Priors
Oct 21, 2024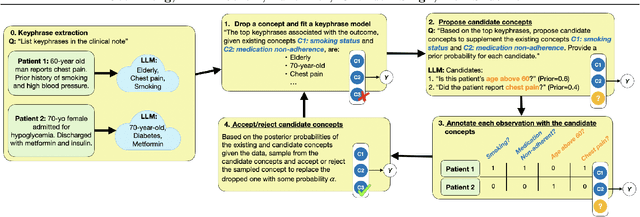
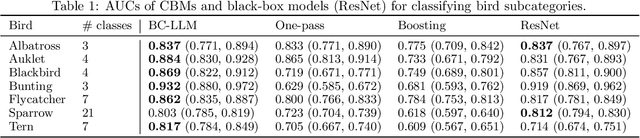
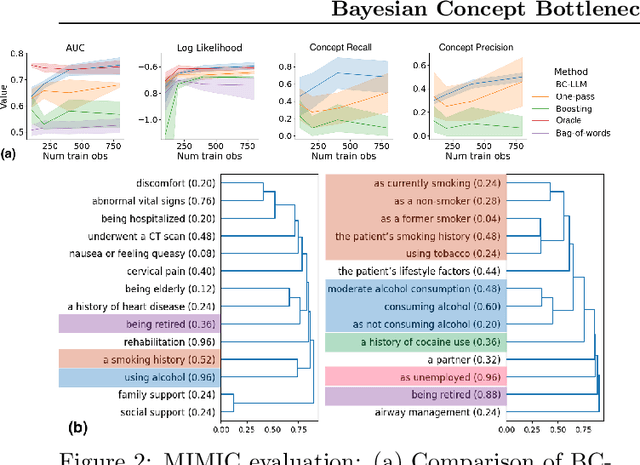
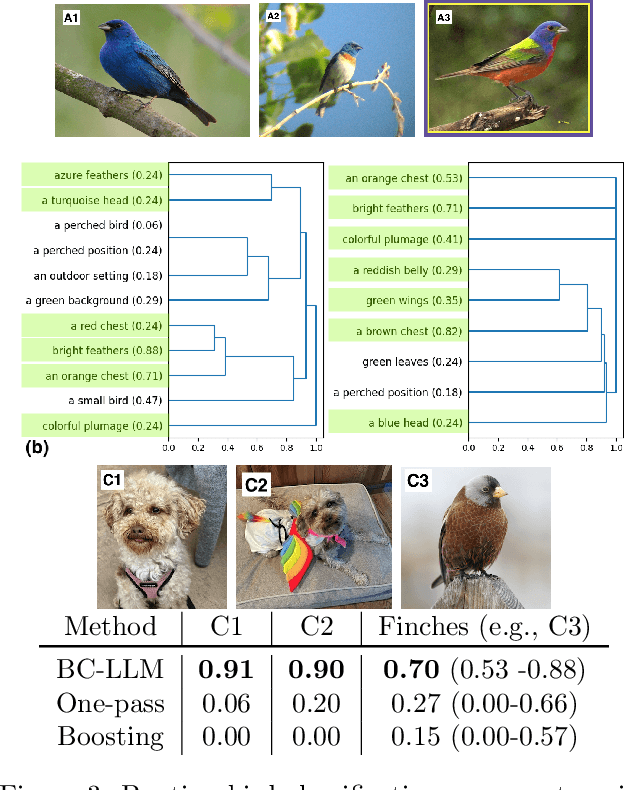
Concept Bottleneck Models (CBMs) have been proposed as a compromise between white-box and black-box models, aiming to achieve interpretability without sacrificing accuracy. The standard training procedure for CBMs is to predefine a candidate set of human-interpretable concepts, extract their values from the training data, and identify a sparse subset as inputs to a transparent prediction model. However, such approaches are often hampered by the tradeoff between enumerating a sufficiently large set of concepts to include those that are truly relevant versus controlling the cost of obtaining concept extractions. This work investigates a novel approach that sidesteps these challenges: BC-LLM iteratively searches over a potentially infinite set of concepts within a Bayesian framework, in which Large Language Models (LLMs) serve as both a concept extraction mechanism and prior. BC-LLM is broadly applicable and multi-modal. Despite imperfections in LLMs, we prove that BC-LLM can provide rigorous statistical inference and uncertainty quantification. In experiments, it outperforms comparator methods including black-box models, converges more rapidly towards relevant concepts and away from spuriously correlated ones, and is more robust to out-of-distribution samples.
The Computational Curse of Big Data for Bayesian Additive Regression Trees: A Hitting Time Analysis
Jun 28, 2024
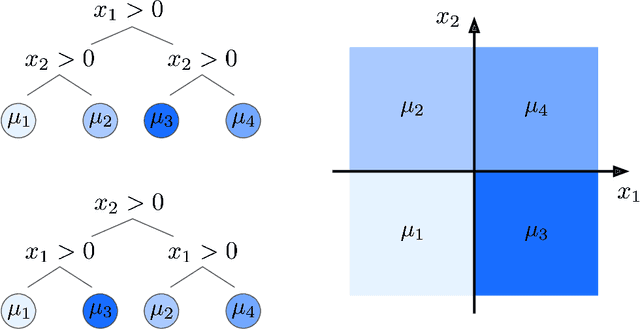
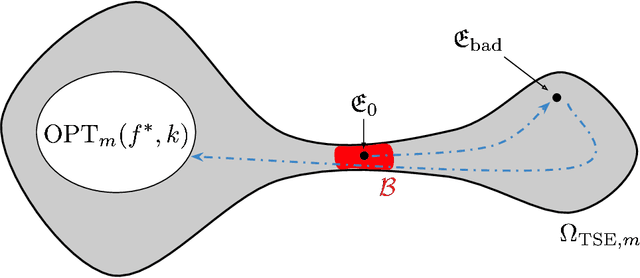

Bayesian Additive Regression Trees (BART) is a popular Bayesian non-parametric regression model that is commonly used in causal inference and beyond. Its strong predictive performance is supported by theoretical guarantees that its posterior distribution concentrates around the true regression function at optimal rates under various data generative settings and for appropriate prior choices. In this paper, we show that the BART sampler often converges slowly, confirming empirical observations by other researchers. Assuming discrete covariates, we show that, while the BART posterior concentrates on a set comprising all optimal tree structures (smallest bias and complexity), the Markov chain's hitting time for this set increases with $n$ (training sample size), under several common data generative settings. As $n$ increases, the approximate BART posterior thus becomes increasingly different from the exact posterior (for the same number of MCMC samples), contrasting with earlier concentration results on the exact posterior. This contrast is highlighted by our simulations showing worsening frequentist undercoverage for approximate posterior intervals and a growing ratio between the MSE of the approximate posterior and that obtainable by artificially improving convergence via averaging multiple sampler chains. Finally, based on our theoretical insights, possibilities are discussed to improve the BART sampler convergence performance.