 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloeNet: A mass-conserving global sea ice emulator that generalizes across climates
Mar 12, 2026We introduce FloeNet, a machine-learning emulator trained on the Geophysical Fluid Dynamics Laboratory global sea ice model, SIS2. FloeNet is a mass-conserving model, emulating 6-hour mass and area budget tendencies related to sea ice and snow-on-sea-ice growth, melt, and advection. We train FloeNet using simulated data from a reanalysis-forced ice-ocean simulation and test its ability to generalize to pre-industrial control and 1% CO2 climates. FloeNet outperforms a non-conservative model at reproducing sea ice and snow-on-sea-ice mean state, trends, and inter-annual variability, with volume anomaly correlations above 0.96 in the Antarctic and 0.76 in the Arctic, across all forcings. FloeNet also produces the correct thermodynamic vs dynamic response to forcing, enabling physical interpretability of emulator output. Finally, we show that FloeNet outputs high-fidelity coupling-related variables, including ice-surface skin temperature, ice-to-ocean salt flux, and melting energy fluxes. We hypothesize that FloeNet will improve polar climate processes within existing atmosphere and ocean emulators.
ACE: A fast, skillful learned global atmospheric model for climate prediction
Oct 03, 2023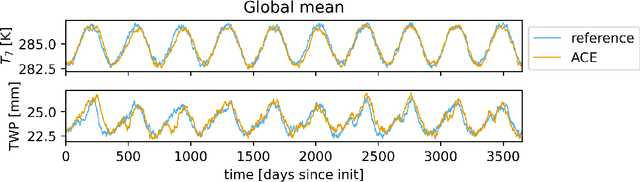
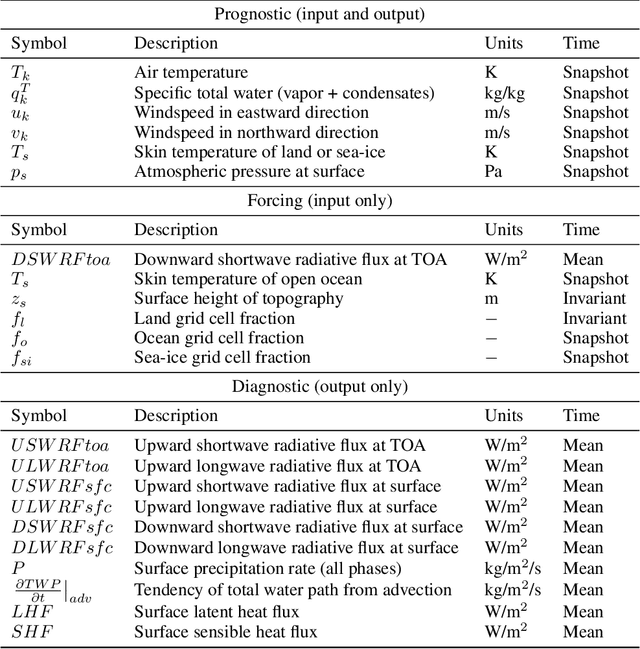


Existing ML-based atmospheric models are not suitable for climate prediction, which requires long-term stability and physical consistency. We present ACE (AI2 Climate Emulator), a 200M-parameter, autoregressive machine learning emulator of an existing comprehensive 100-km resolution global atmospheric model. The formulation of ACE allows evaluation of physical laws such as the conservation of mass and moisture. The emulator is stable for 10 years, nearly conserves column moisture without explicit constraints and faithfully reproduces the reference model's climate, outperforming a challenging baseline on over 80% of tracked variables. ACE requires nearly 100x less wall clock time and is 100x more energy efficient than the reference model using typically available resources.
MedGen3D: A Deep Generative Framework for Paired 3D Image and Mask Generation
Apr 08, 2023

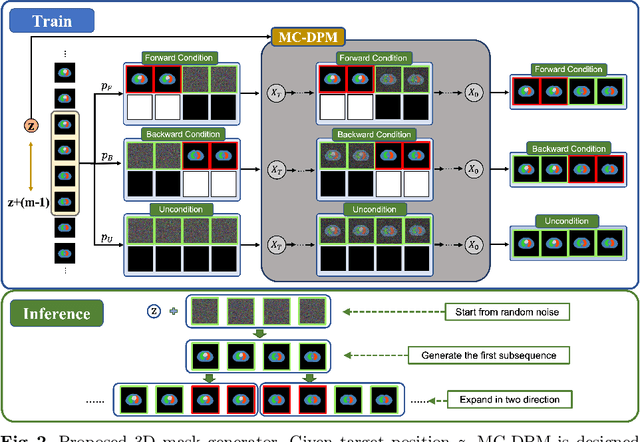

Acquiring and annotating sufficient labeled data is crucial in developing accurate and robust learning-based models, but obtaining such data can be challenging in many medical image segmentation tasks. One promising solution is to synthesize realistic data with ground-truth mask annotations. However, no prior studies have explored generating complete 3D volumetric images with masks. In this paper, we present MedGen3D, a deep generative framework that can generate paired 3D medical images and masks. First, we represent the 3D medical data as 2D sequences and propose the Multi-Condition Diffusion Probabilistic Model (MC-DPM) to generate multi-label mask sequences adhering to anatomical geometry. Then, we use an image sequence generator and semantic diffusion refiner conditioned on the generated mask sequences to produce realistic 3D medical images that align with the generated masks. Our proposed framework guarantees accurate alignment between synthetic images and segmentation maps. Experiments on 3D thoracic CT and brain MRI datasets show that our synthetic data is both diverse and faithful to the original data, and demonstrate the benefits for downstream segmentation tasks. We anticipate that MedGen3D's ability to synthesize paired 3D medical images and masks will prove valuable in training deep learning models for medical imaging tasks.
Localized Region Contrast for Enhancing Self-Supervised Learning in Medical Image Segmentation
Apr 06, 2023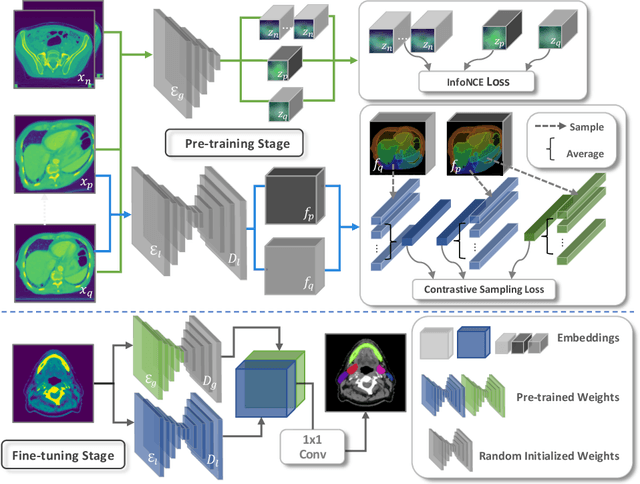
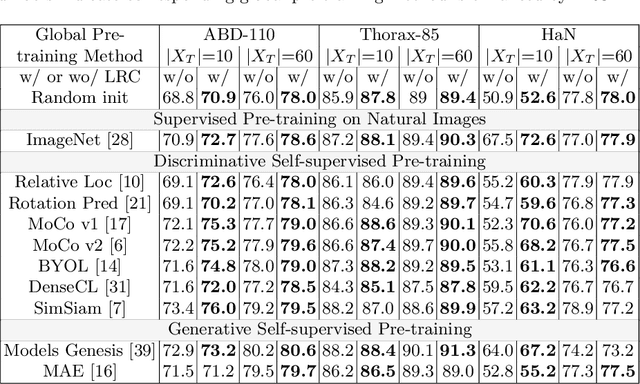
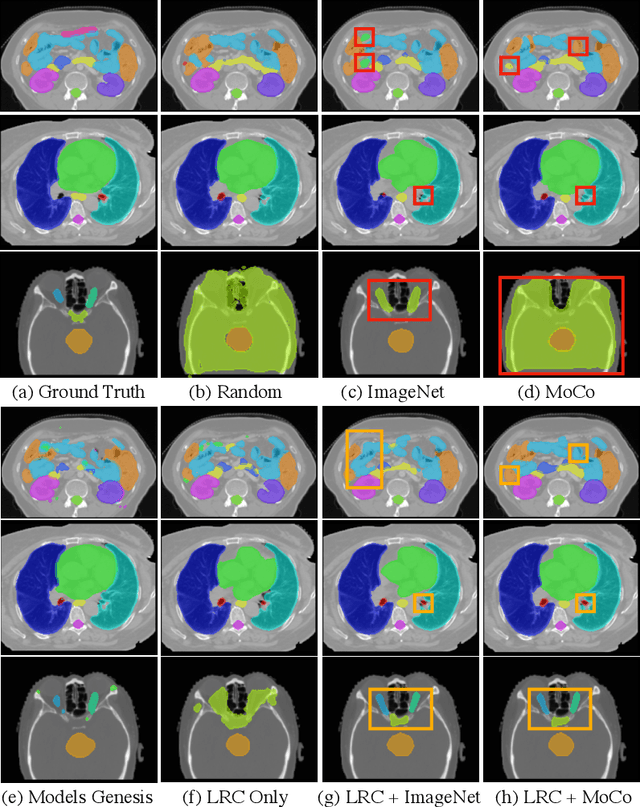

Recent advancements in self-supervised learning have demonstrated that effective visual representations can be learned from unlabeled images. This has led to increased interest in applying self-supervised learning to the medical domain, where unlabeled images are abundant and labeled images are difficult to obtain. However, most self-supervised learning approaches are modeled as image level discriminative or generative proxy tasks, which may not capture the finer level representations necessary for dense prediction tasks like multi-organ segmentation. In this paper, we propose a novel contrastive learning framework that integrates Localized Region Contrast (LRC) to enhance existing self-supervised pre-training methods for medical image segmentation. Our approach involves identifying Super-pixels by Felzenszwalb's algorithm and performing local contrastive learning using a novel contrastive sampling loss. Through extensive experiments on three multi-organ segmentation datasets, we demonstrate that integrating LRC to an existing self-supervised method in a limited annotation setting significantly improves segmentation performance. Moreover, we show that LRC can also be applied to fully-supervised pre-training methods to further boost performance.
Deep Learning for Breast MRI Style Transfer with Limited Training Data
Jan 05, 2023In this work we introduce a novel medical image style transfer method, StyleMapper, that can transfer medical scans to an unseen style with access to limited training data. This is made possible by training our model on unlimited possibilities of simulated random medical imaging styles on the training set, making our work more computationally efficient when compared with other style transfer methods. Moreover, our method enables arbitrary style transfer: transferring images to styles unseen in training. This is useful for medical imaging, where images are acquired using different protocols and different scanner models, resulting in a variety of styles that data may need to be transferred between. Methods: Our model disentangles image content from style and can modify an image's style by simply replacing the style encoding with one extracted from a single image of the target style, with no additional optimization required. This also allows the model to distinguish between different styles of images, including among those that were unseen in training. We propose a formal description of the proposed model. Results: Experimental results on breast magnetic resonance images indicate the effectiveness of our method for style transfer. Conclusion: Our style transfer method allows for the alignment of medical images taken with different scanners into a single unified style dataset, allowing for the training of other downstream tasks on such a dataset for tasks such as classification, object detection and others.
* preprint version, accepted in the Journal of Digital Imaging (JDIM). 16 pages (+ author names + references + supplementary), 6 figures
Generative Modeling of High-resolution Global Precipitation Forecasts
Oct 22, 2022



Forecasting global precipitation patterns and, in particular, extreme precipitation events is of critical importance to preparing for and adapting to climate change. Making accurate high-resolution precipitation forecasts using traditional physical models remains a major challenge in operational weather forecasting as they incur substantial computational costs and struggle to achieve sufficient forecast skill. Recently, deep-learning-based models have shown great promise in closing the gap with numerical weather prediction (NWP) models in terms of precipitation forecast skill, opening up exciting new avenues for precipitation modeling. However, it is challenging for these deep learning models to fully resolve the fine-scale structures of precipitation phenomena and adequately characterize the extremes of the long-tailed precipitation distribution. In this work, we present several improvements to the architecture and training process of a current state-of-the art deep learning precipitation model (FourCastNet) using a novel generative adversarial network (GAN) to better capture fine scales and extremes. Our improvements achieve superior performance in capturing the extreme percentiles of global precipitation, while comparable to state-of-the-art NWP models in terms of forecast skill at 1--2 day lead times. Together, these improvements set a new state-of-the-art in global precipitation forecasting.
A Mixing Time Lower Bound for a Simplified Version of BART
Oct 17, 2022
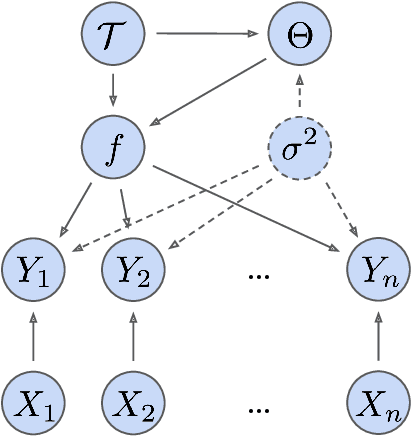

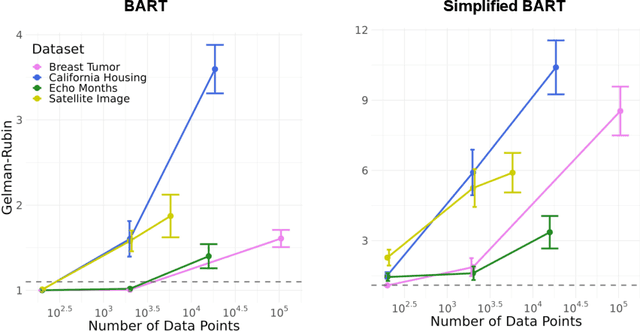
Bayesian Additive Regression Trees (BART) is a popular Bayesian non-parametric regression algorithm. The posterior is a distribution over sums of decision trees, and predictions are made by averaging approximate samples from the posterior. The combination of strong predictive performance and the ability to provide uncertainty measures has led BART to be commonly used in the social sciences, biostatistics, and causal inference. BART uses Markov Chain Monte Carlo (MCMC) to obtain approximate posterior samples over a parameterized space of sums of trees, but it has often been observed that the chains are slow to mix. In this paper, we provide the first lower bound on the mixing time for a simplified version of BART in which we reduce the sum to a single tree and use a subset of the possible moves for the MCMC proposal distribution. Our lower bound for the mixing time grows exponentially with the number of data points. Inspired by this new connection between the mixing time and the number of data points, we perform rigorous simulations on BART. We show qualitatively that BART's mixing time increases with the number of data points. The slow mixing time of the simplified BART suggests a large variation between different runs of the simplified BART algorithm and a similar large variation is known for BART in the literature. This large variation could result in a lack of stability in the models, predictions, and posterior intervals obtained from the BART MCMC samples. Our lower bound and simulations suggest increasing the number of chains with the number of data points.
Learning correspondences of cardiac motion from images using biomechanics-informed modeling
Sep 01, 2022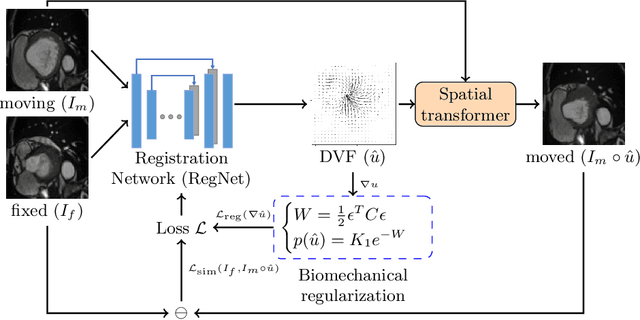
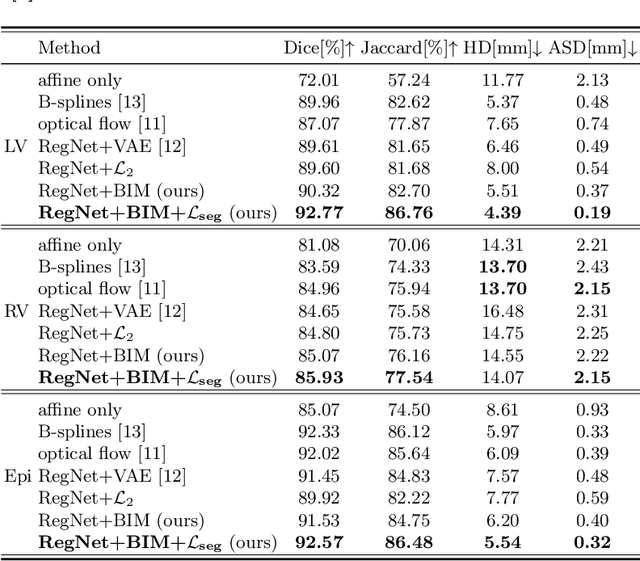
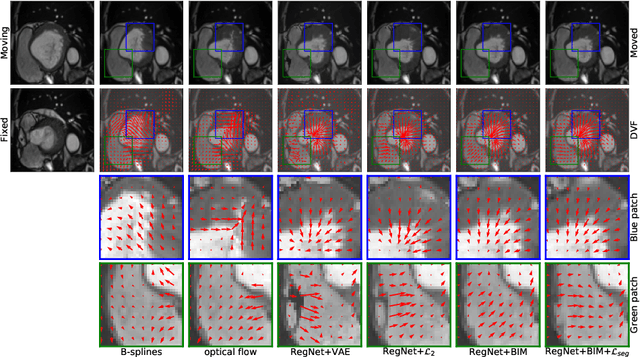
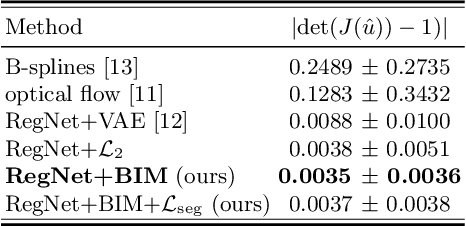
Learning spatial-temporal correspondences in cardiac motion from images is important for understanding the underlying dynamics of cardiac anatomical structures. Many methods explicitly impose smoothness constraints such as the $\mathcal{L}_2$ norm on the displacement vector field (DVF), while usually ignoring biomechanical feasibility in the transformation. Other geometric constraints either regularize specific regions of interest such as imposing incompressibility on the myocardium or introduce additional steps such as training a separate network-based regularizer on physically simulated datasets. In this work, we propose an explicit biomechanics-informed prior as regularization on the predicted DVF in modeling a more generic biomechanically plausible transformation within all cardiac structures without introducing additional training complexity. We validate our methods on two publicly available datasets in the context of 2D MRI data and perform extensive experiments to illustrate the effectiveness and robustness of our proposed methods compared to other competing regularization schemes. Our proposed methods better preserve biomechanical properties by visual assessment and show advantages in segmentation performance using quantitative evaluation metrics. The code is publicly available at \url{https://github.com/Voldemort108X/bioinformed_reg}.
Multi-scale Super-resolution Magnetic Resonance Spectroscopic Imaging with Adjustable Sharpness
Jun 17, 2022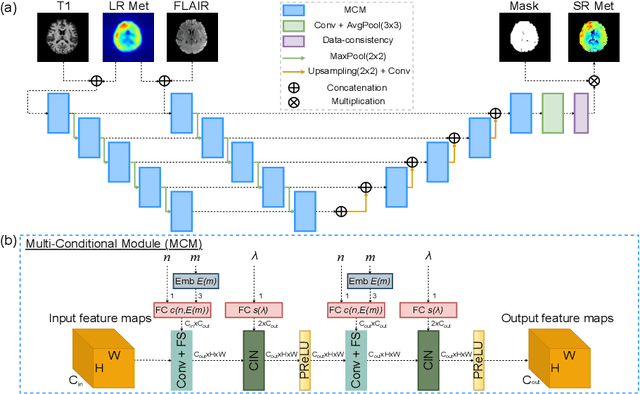
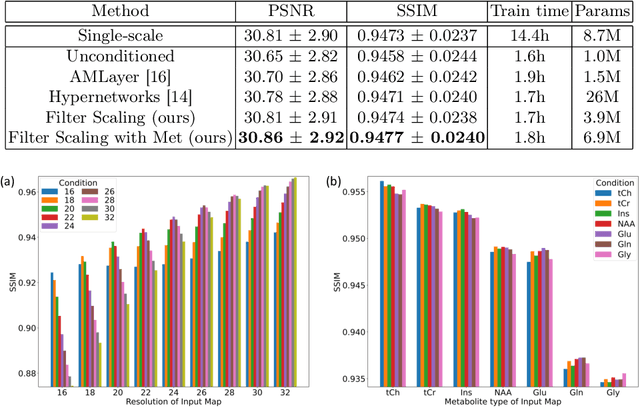
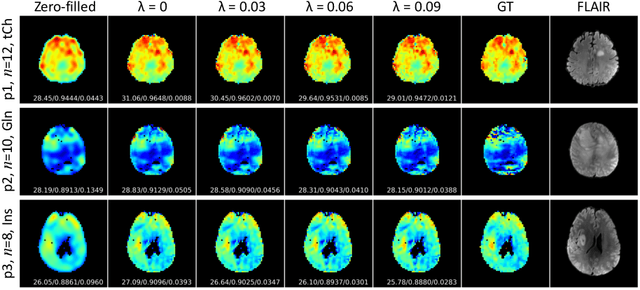
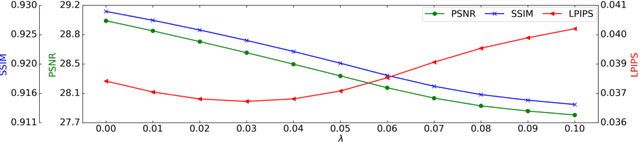
Magnetic Resonance Spectroscopic Imaging (MRSI) is a valuable tool for studying metabolic activities in the human body, but the current applications are limited to low spatial resolutions. The existing deep learning-based MRSI super-resolution methods require training a separate network for each upscaling factor, which is time-consuming and memory inefficient. We tackle this multi-scale super-resolution problem using a Filter Scaling strategy that modulates the convolution filters based on the upscaling factor, such that a single network can be used for various upscaling factors. Observing that each metabolite has distinct spatial characteristics, we also modulate the network based on the specific metabolite. Furthermore, our network is conditioned on the weight of adversarial loss so that the perceptual sharpness of the super-resolved metabolic maps can be adjusted within a single network. We incorporate these network conditionings using a novel Multi-Conditional Module. The experiments were carried out on a 1H-MRSI dataset from 15 high-grade glioma patients. Results indicate that the proposed network achieves the best performance among several multi-scale super-resolution methods and can provide super-resolved metabolic maps with adjustable sharpness.
Group Probability-Weighted Tree Sums for Interpretable Modeling of Heterogeneous Data
May 30, 2022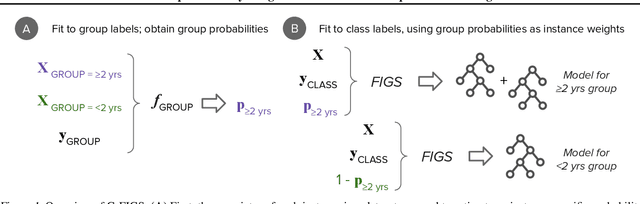

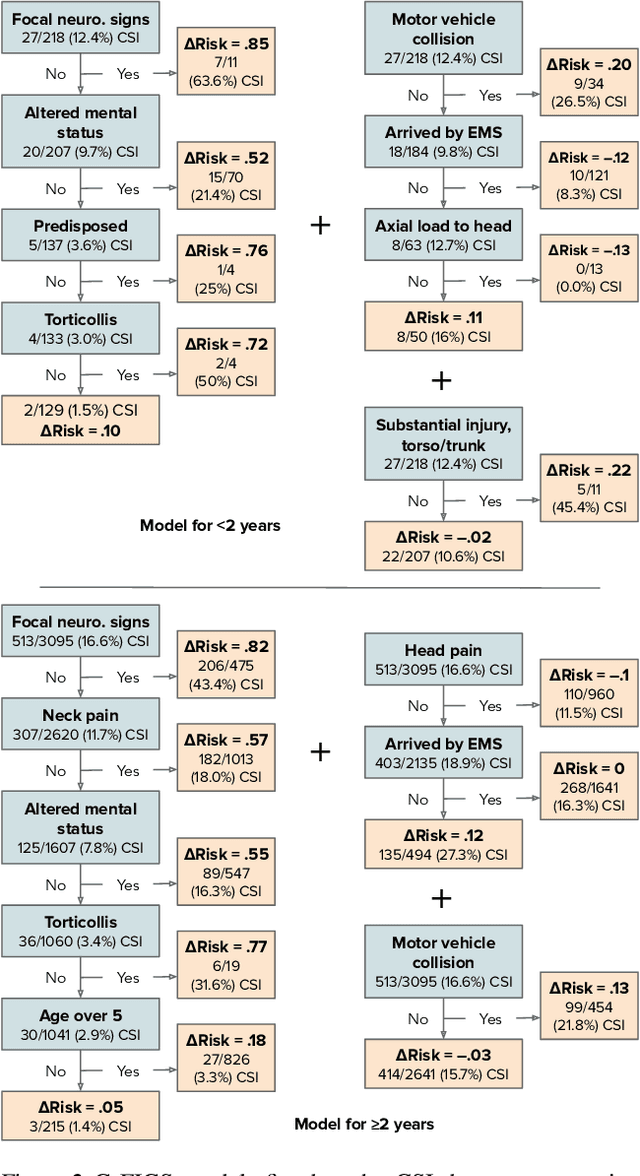
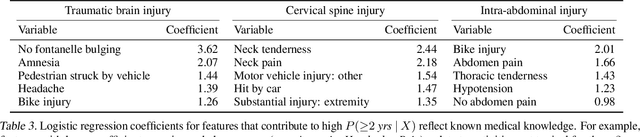
Machine learning in high-stakes domains, such as healthcare, faces two critical challenges: (1) generalizing to diverse data distributions given limited training data while (2) maintaining interpretability. To address these challenges, we propose an instance-weighted tree-sum method that effectively pools data across diverse groups to output a concise, rule-based model. Given distinct groups of instances in a dataset (e.g., medical patients grouped by age or treatment site), our method first estimates group membership probabilities for each instance. Then, it uses these estimates as instance weights in FIGS (Tan et al. 2022), to grow a set of decision trees whose values sum to the final prediction. We call this new method Group Probability-Weighted Tree Sums (G-FIGS). G-FIGS achieves state-of-the-art prediction performance on important clinical datasets; e.g., holding the level of sensitivity fixed at 92%, G-FIGS increases specificity for identifying cervical spine injury by up to 10% over CART and up to 3% over FIGS alone, with larger gains at higher sensitivity levels. By keeping the total number of rules below 16 in FIGS, the final models remain interpretable, and we find that their rules match medical domain expertise. All code, data, and models are released on Github.