 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoME: Mixture of Visual Language Medical Experts for Medical Imaging Segmentation
Oct 30, 2025In this study, we propose MoME, a Mixture of Visual Language Medical Experts, for Medical Image Segmentation. MoME adapts the successful Mixture of Experts (MoE) paradigm, widely used in Large Language Models (LLMs), for medical vision-language tasks. The architecture enables dynamic expert selection by effectively utilizing multi-scale visual features tailored to the intricacies of medical imagery, enriched with textual embeddings. This work explores a novel integration of vision-language models for this domain. Utilizing an assembly of 10 datasets, encompassing 3,410 CT scans, MoME demonstrates strong performance on a comprehensive medical imaging segmentation benchmark. Our approach explores the integration of foundation models for medical imaging, benefiting from the established efficacy of MoE in boosting model performance by incorporating textual information. Demonstrating competitive precision across multiple datasets, MoME explores a novel architecture for achieving robust results in medical image analysis.
Deep Rib Fracture Instance Segmentation and Classification from CT on the RibFrac Challenge
Feb 14, 2024Rib fractures are a common and potentially severe injury that can be challenging and labor-intensive to detect in CT scans. While there have been efforts to address this field, the lack of large-scale annotated datasets and evaluation benchmarks has hindered the development and validation of deep learning algorithms. To address this issue, the RibFrac Challenge was introduced, providing a benchmark dataset of over 5,000 rib fractures from 660 CT scans, with voxel-level instance mask annotations and diagnosis labels for four clinical categories (buckle, nondisplaced, displaced, or segmental). The challenge includes two tracks: a detection (instance segmentation) track evaluated by an FROC-style metric and a classification track evaluated by an F1-style metric. During the MICCAI 2020 challenge period, 243 results were evaluated, and seven teams were invited to participate in the challenge summary. The analysis revealed that several top rib fracture detection solutions achieved performance comparable or even better than human experts. Nevertheless, the current rib fracture classification solutions are hardly clinically applicable, which can be an interesting area in the future. As an active benchmark and research resource, the data and online evaluation of the RibFrac Challenge are available at the challenge website. As an independent contribution, we have also extended our previous internal baseline by incorporating recent advancements in large-scale pretrained networks and point-based rib segmentation techniques. The resulting FracNet+ demonstrates competitive performance in rib fracture detection, which lays a foundation for further research and development in AI-assisted rib fracture detection and diagnosis.
CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
Nov 11, 2023Reconstructing personalized animatable head avatars has significant implications in the fields of AR/VR. Existing methods for achieving explicit face control of 3D Morphable Models (3DMM) typically rely on multi-view images or videos of a single subject, making the reconstruction process complex. Additionally, the traditional rendering pipeline is time-consuming, limiting real-time animation possibilities. In this paper, we introduce CVTHead, a novel approach that generates controllable neural head avatars from a single reference image using point-based neural rendering. CVTHead considers the sparse vertices of mesh as the point set and employs the proposed Vertex-feature Transformer to learn local feature descriptors for each vertex. This enables the modeling of long-range dependencies among all the vertices. Experimental results on the VoxCeleb dataset demonstrate that CVTHead achieves comparable performance to state-of-the-art graphics-based methods. Moreover, it enables efficient rendering of novel human heads with various expressions, head poses, and camera views. These attributes can be explicitly controlled using the coefficients of 3DMMs, facilitating versatile and realistic animation in real-time scenarios.
Hybrid-CSR: Coupling Explicit and Implicit Shape Representation for Cortical Surface Reconstruction
Jul 23, 2023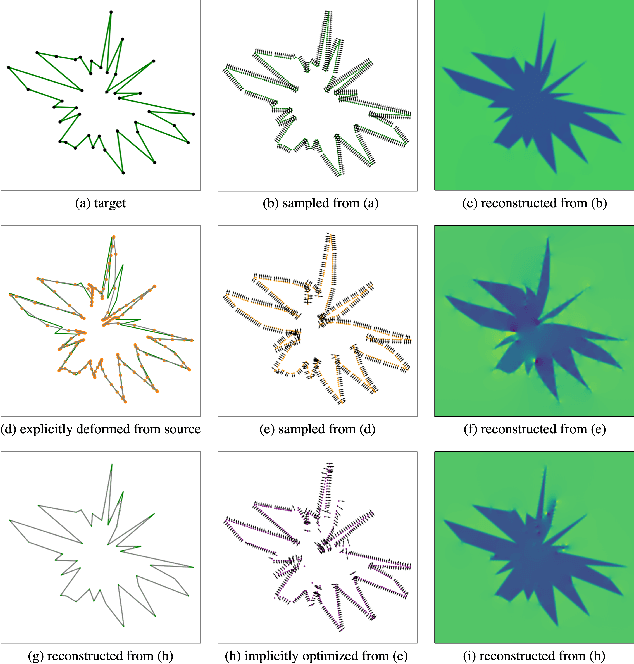
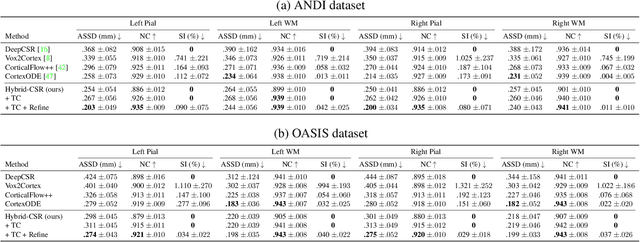
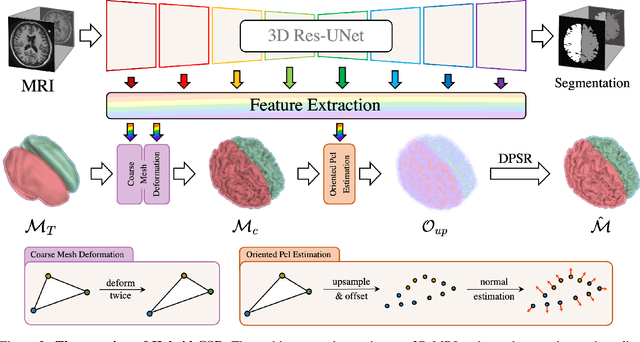
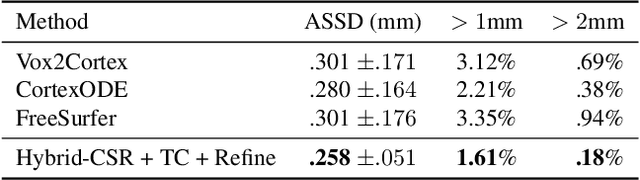
We present Hybrid-CSR, a geometric deep-learning model that combines explicit and implicit shape representations for cortical surface reconstruction. Specifically, Hybrid-CSR begins with explicit deformations of template meshes to obtain coarsely reconstructed cortical surfaces, based on which the oriented point clouds are estimated for the subsequent differentiable poisson surface reconstruction. By doing so, our method unifies explicit (oriented point clouds) and implicit (indicator function) cortical surface reconstruction. Compared to explicit representation-based methods, our hybrid approach is more friendly to capture detailed structures, and when compared with implicit representation-based methods, our method can be topology aware because of end-to-end training with a mesh-based deformation module. In order to address topology defects, we propose a new topology correction pipeline that relies on optimization-based diffeomorphic surface registration. Experimental results on three brain datasets show that our approach surpasses existing implicit and explicit cortical surface reconstruction methods in numeric metrics in terms of accuracy, regularity, and consistency.
MedGen3D: A Deep Generative Framework for Paired 3D Image and Mask Generation
Apr 08, 2023

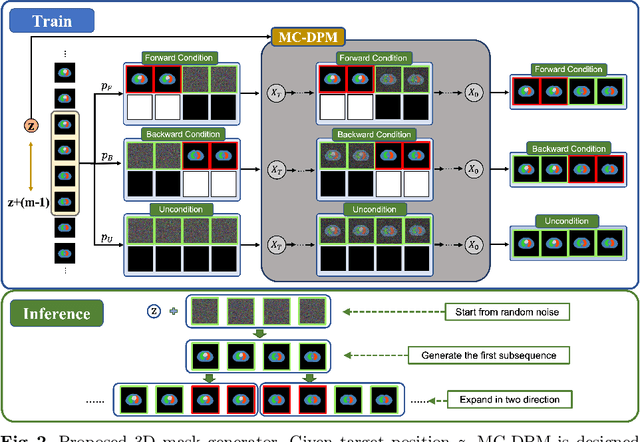

Acquiring and annotating sufficient labeled data is crucial in developing accurate and robust learning-based models, but obtaining such data can be challenging in many medical image segmentation tasks. One promising solution is to synthesize realistic data with ground-truth mask annotations. However, no prior studies have explored generating complete 3D volumetric images with masks. In this paper, we present MedGen3D, a deep generative framework that can generate paired 3D medical images and masks. First, we represent the 3D medical data as 2D sequences and propose the Multi-Condition Diffusion Probabilistic Model (MC-DPM) to generate multi-label mask sequences adhering to anatomical geometry. Then, we use an image sequence generator and semantic diffusion refiner conditioned on the generated mask sequences to produce realistic 3D medical images that align with the generated masks. Our proposed framework guarantees accurate alignment between synthetic images and segmentation maps. Experiments on 3D thoracic CT and brain MRI datasets show that our synthetic data is both diverse and faithful to the original data, and demonstrate the benefits for downstream segmentation tasks. We anticipate that MedGen3D's ability to synthesize paired 3D medical images and masks will prove valuable in training deep learning models for medical imaging tasks.
Localized Region Contrast for Enhancing Self-Supervised Learning in Medical Image Segmentation
Apr 06, 2023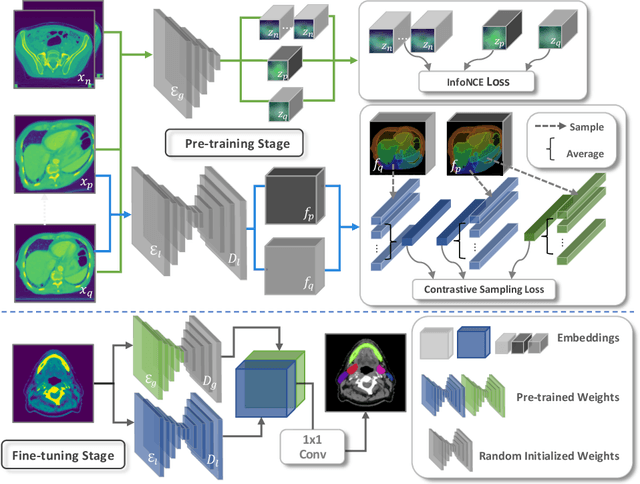
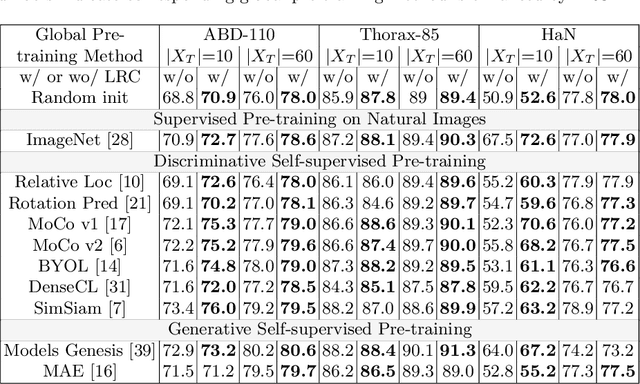
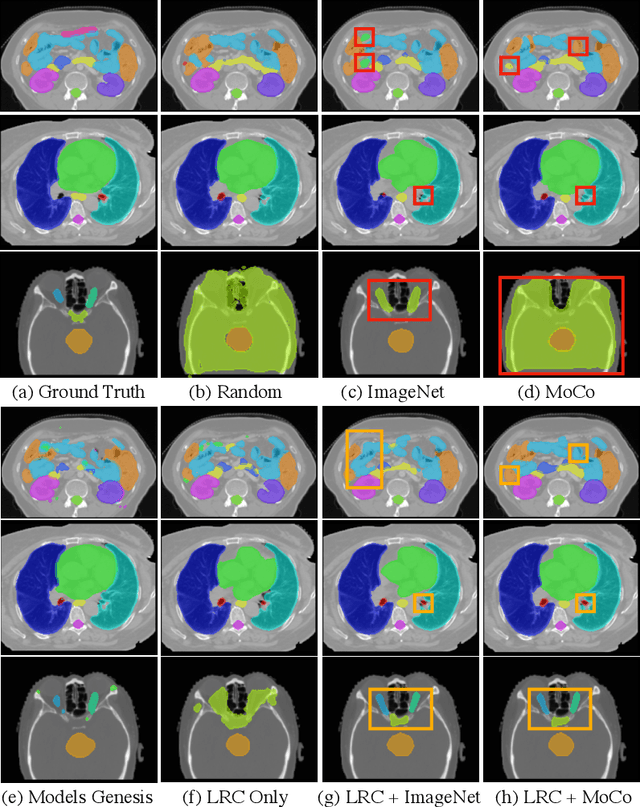

Recent advancements in self-supervised learning have demonstrated that effective visual representations can be learned from unlabeled images. This has led to increased interest in applying self-supervised learning to the medical domain, where unlabeled images are abundant and labeled images are difficult to obtain. However, most self-supervised learning approaches are modeled as image level discriminative or generative proxy tasks, which may not capture the finer level representations necessary for dense prediction tasks like multi-organ segmentation. In this paper, we propose a novel contrastive learning framework that integrates Localized Region Contrast (LRC) to enhance existing self-supervised pre-training methods for medical image segmentation. Our approach involves identifying Super-pixels by Felzenszwalb's algorithm and performing local contrastive learning using a novel contrastive sampling loss. Through extensive experiments on three multi-organ segmentation datasets, we demonstrate that integrating LRC to an existing self-supervised method in a limited annotation setting significantly improves segmentation performance. Moreover, we show that LRC can also be applied to fully-supervised pre-training methods to further boost performance.
Identity-Aware Hand Mesh Estimation and Personalization from RGB Images
Sep 22, 2022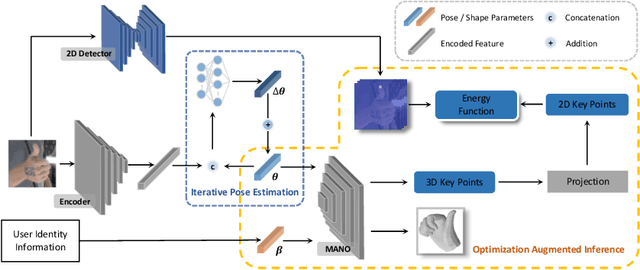
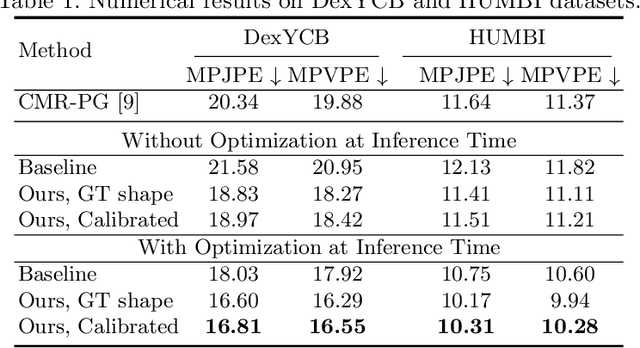
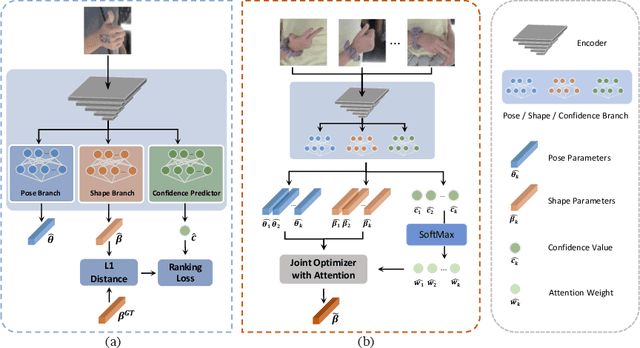
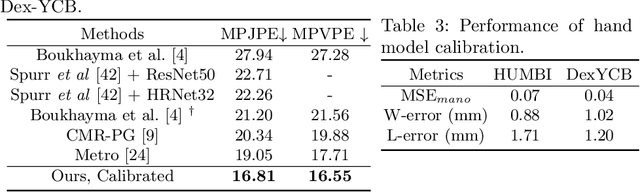
Reconstructing 3D hand meshes from monocular RGB images has attracted increasing amount of attention due to its enormous potential applications in the field of AR/VR. Most state-of-the-art methods attempt to tackle this task in an anonymous manner. Specifically, the identity of the subject is ignored even though it is practically available in real applications where the user is unchanged in a continuous recording session. In this paper, we propose an identity-aware hand mesh estimation model, which can incorporate the identity information represented by the intrinsic shape parameters of the subject. We demonstrate the importance of the identity information by comparing the proposed identity-aware model to a baseline which treats subject anonymously. Furthermore, to handle the use case where the test subject is unseen, we propose a novel personalization pipeline to calibrate the intrinsic shape parameters using only a few unlabeled RGB images of the subject. Experiments on two large scale public datasets validate the state-of-the-art performance of our proposed method.
PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimation
Sep 16, 2022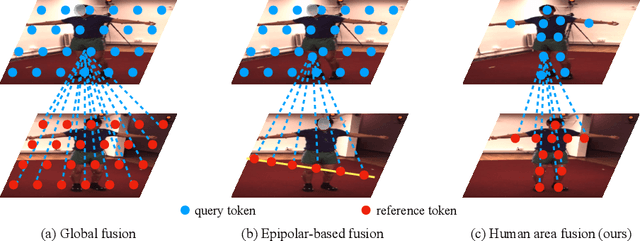
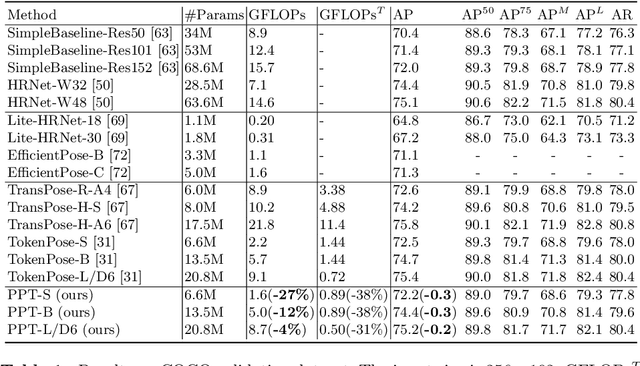

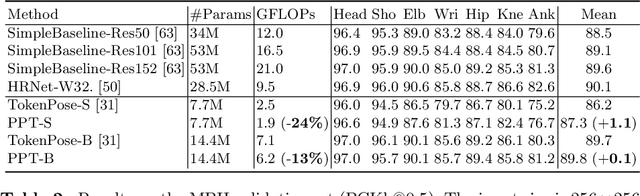
Recently, the vision transformer and its variants have played an increasingly important role in both monocular and multi-view human pose estimation. Considering image patches as tokens, transformers can model the global dependencies within the entire image or across images from other views. However, global attention is computationally expensive. As a consequence, it is difficult to scale up these transformer-based methods to high-resolution features and many views. In this paper, we propose the token-Pruned Pose Transformer (PPT) for 2D human pose estimation, which can locate a rough human mask and performs self-attention only within selected tokens. Furthermore, we extend our PPT to multi-view human pose estimation. Built upon PPT, we propose a new cross-view fusion strategy, called human area fusion, which considers all human foreground pixels as corresponding candidates. Experimental results on COCO and MPII demonstrate that our PPT can match the accuracy of previous pose transformer methods while reducing the computation. Moreover, experiments on Human 3.6M and Ski-Pose demonstrate that our Multi-view PPT can efficiently fuse cues from multiple views and achieve new state-of-the-art results.
Topology-Preserving Shape Reconstruction and Registration via Neural Diffeomorphic Flow
Mar 21, 2022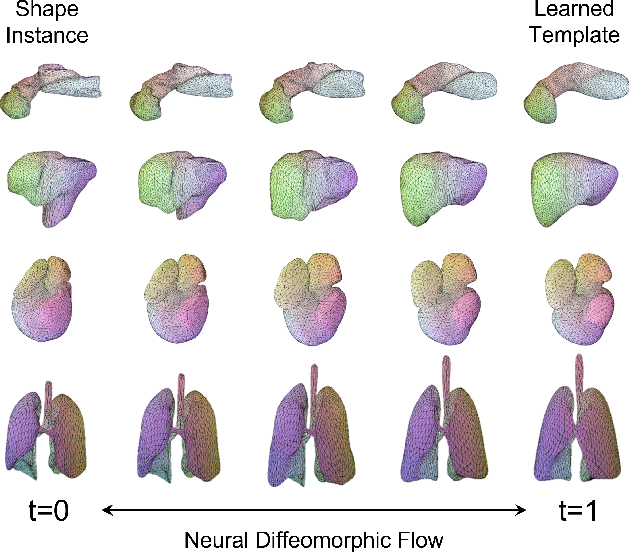

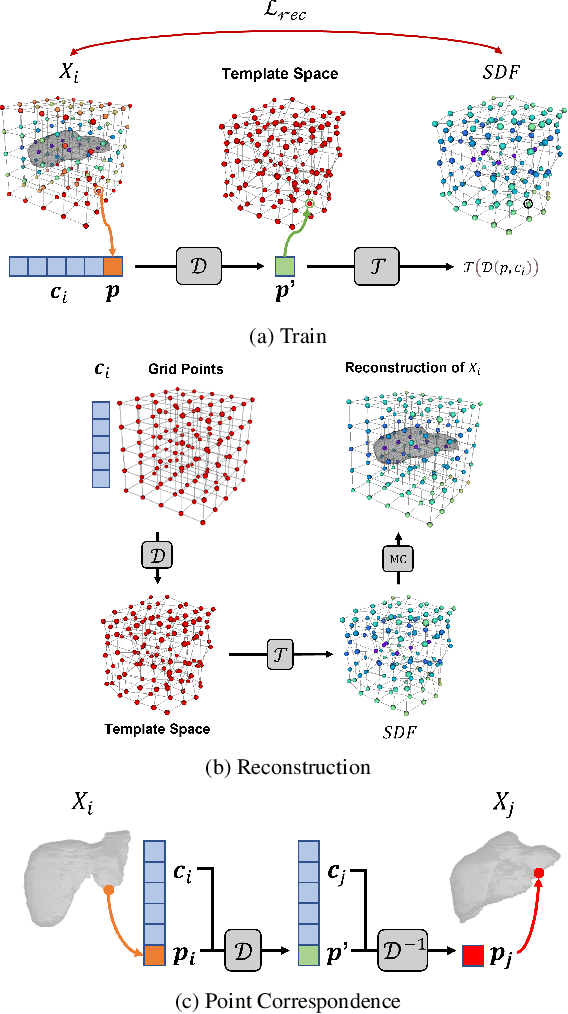
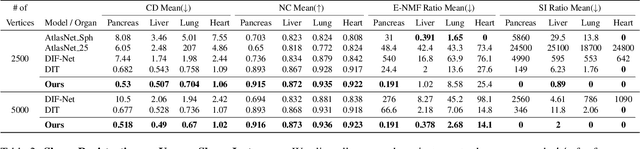
Deep Implicit Functions (DIFs) represent 3D geometry with continuous signed distance functions learned through deep neural nets. Recently DIFs-based methods have been proposed to handle shape reconstruction and dense point correspondences simultaneously, capturing semantic relationships across shapes of the same class by learning a DIFs-modeled shape template. These methods provide great flexibility and accuracy in reconstructing 3D shapes and inferring correspondences. However, the point correspondences built from these methods do not intrinsically preserve the topology of the shapes, unlike mesh-based template matching methods. This limits their applications on 3D geometries where underlying topological structures exist and matter, such as anatomical structures in medical images. In this paper, we propose a new model called Neural Diffeomorphic Flow (NDF) to learn deep implicit shape templates, representing shapes as conditional diffeomorphic deformations of templates, intrinsically preserving shape topologies. The diffeomorphic deformation is realized by an auto-decoder consisting of Neural Ordinary Differential Equation (NODE) blocks that progressively map shapes to implicit templates. We conduct extensive experiments on several medical image organ segmentation datasets to evaluate the effectiveness of NDF on reconstructing and aligning shapes. NDF achieves consistently state-of-the-art organ shape reconstruction and registration results in both accuracy and quality. The source code is publicly available at https://github.com/Siwensun/Neural_Diffeomorphic_Flow--NDF.
Diffeomorphic Image Registration with Neural Velocity Field
Mar 08, 2022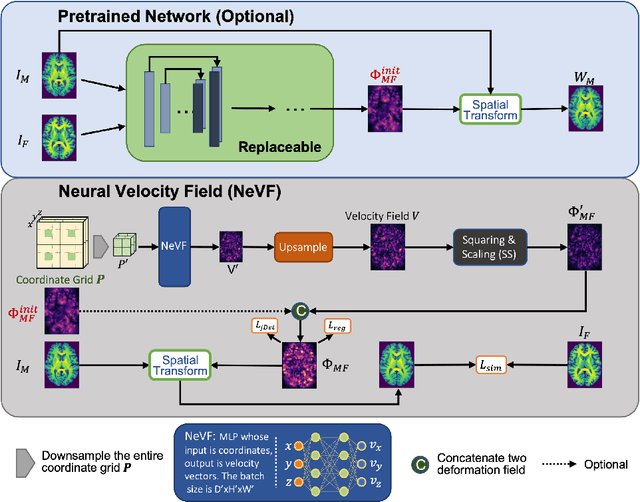
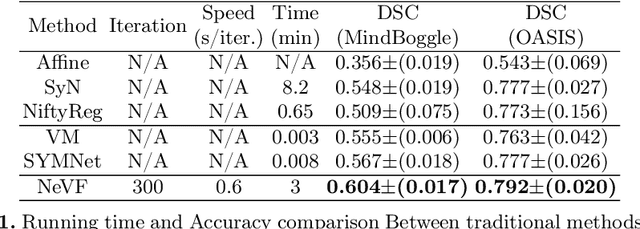
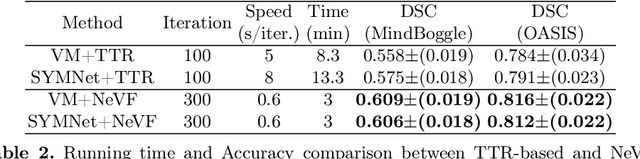
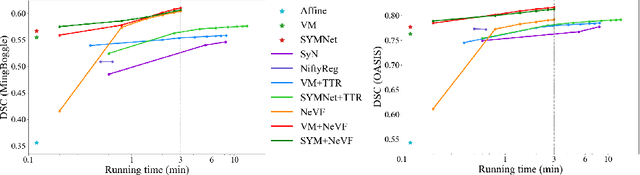
Diffeomorphic image registration is a crucial task in medical image analysis. Recent learning-based image registration methods utilize convolutional neural networks (CNN) to learn the spatial transformation between image pairs and achieve a fast inference speed. However, these methods often require a large number of training data to improve their generalization abilities. During the test time, learning-based methods might fail to provide a good registration result, which is likely because of the model overfitting on the training dataset. In this paper, we propose a neural representation of continuous velocity field (NeVF) to describe the deformations across two images. Specifically, this neural velocity field assigns a velocity vector to each point in the space, which has higher flexibility in modeling the complex deformation field. Furthermore, we propose a simple sparse-sampling strategy to reduce the memory consumption for the diffeomorphic registration. The proposed NeVF can also incorporate with a pre-trained learning-based model whose predicted deformation is taken as an initial state for optimization. Extensive experiments conducted on two large-scale 3D MR brain scan datasets demonstrate that our proposed method outperforms the state-of-the-art registration methods by a large margin.