 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Probability-Weighted Tree Sums for Interpretable Modeling of Heterogeneous Data
May 30, 2022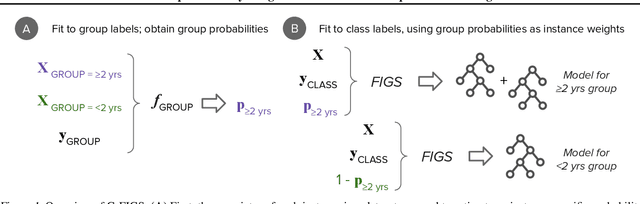

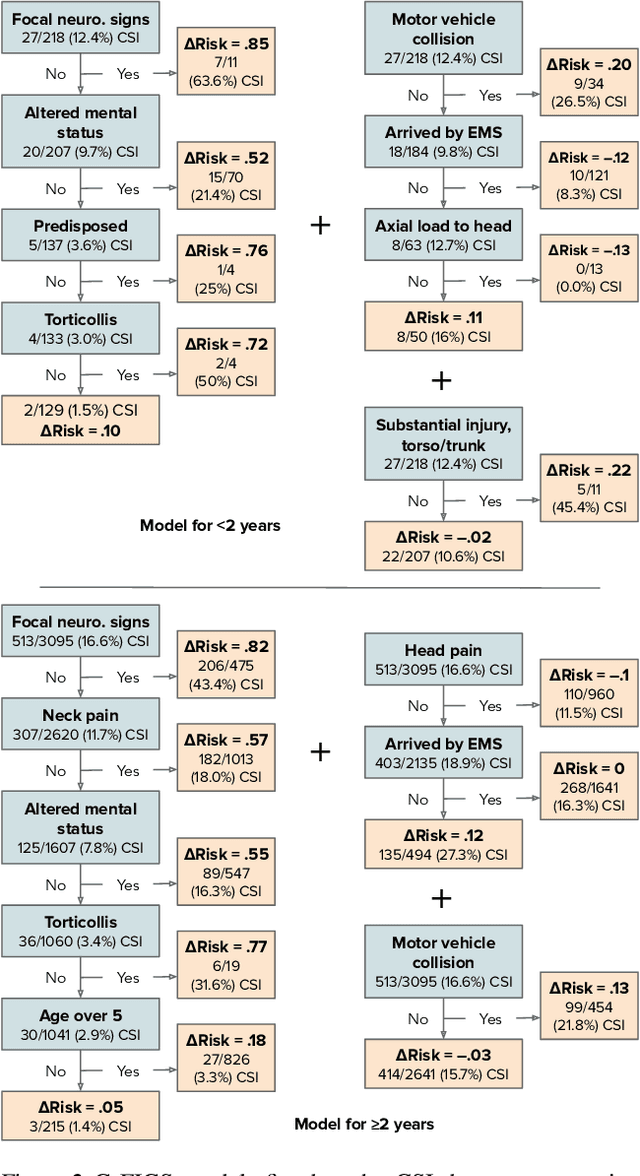
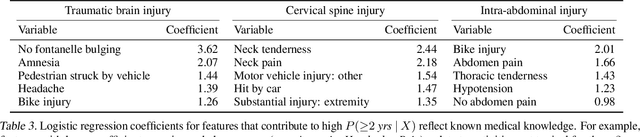
Machine learning in high-stakes domains, such as healthcare, faces two critical challenges: (1) generalizing to diverse data distributions given limited training data while (2) maintaining interpretability. To address these challenges, we propose an instance-weighted tree-sum method that effectively pools data across diverse groups to output a concise, rule-based model. Given distinct groups of instances in a dataset (e.g., medical patients grouped by age or treatment site), our method first estimates group membership probabilities for each instance. Then, it uses these estimates as instance weights in FIGS (Tan et al. 2022), to grow a set of decision trees whose values sum to the final prediction. We call this new method Group Probability-Weighted Tree Sums (G-FIGS). G-FIGS achieves state-of-the-art prediction performance on important clinical datasets; e.g., holding the level of sensitivity fixed at 92%, G-FIGS increases specificity for identifying cervical spine injury by up to 10% over CART and up to 3% over FIGS alone, with larger gains at higher sensitivity levels. By keeping the total number of rules below 16 in FIGS, the final models remain interpretable, and we find that their rules match medical domain expertise. All code, data, and models are released on Github.
On Guiding Visual Attention with Language Specification
Feb 17, 2022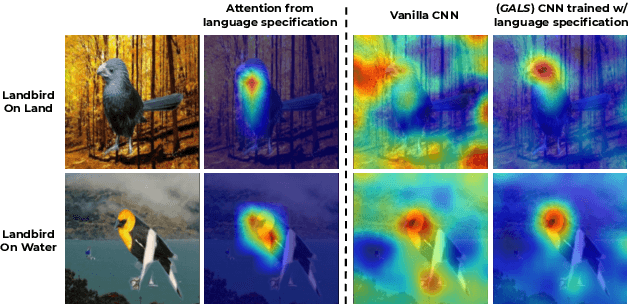

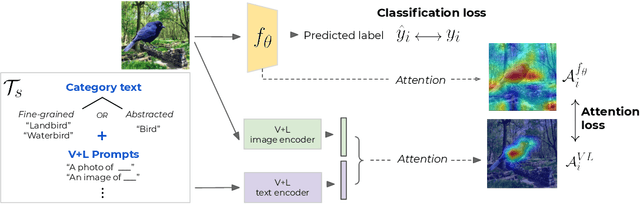
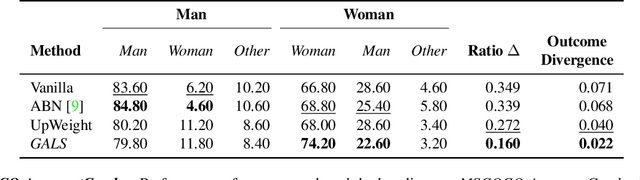
While real world challenges typically define visual categories with language words or phrases, most visual classification methods define categories with numerical indices. However, the language specification of the classes provides an especially useful prior for biased and noisy datasets, where it can help disambiguate what features are task-relevant. Recently, large-scale multimodal models have been shown to recognize a wide variety of high-level concepts from a language specification even without additional image training data, but they are often unable to distinguish classes for more fine-grained tasks. CNNs, in contrast, can extract subtle image features that are required for fine-grained discrimination, but will overfit to any bias or noise in datasets. Our insight is to use high-level language specification as advice for constraining the classification evidence to task-relevant features, instead of distractors. To do this, we ground task-relevant words or phrases with attention maps from a pretrained large-scale model. We then use this grounding to supervise a classifier's spatial attention away from distracting context. We show that supervising spatial attention in this way improves performance on classification tasks with biased and noisy data, including about 3-15% worst-group accuracy improvements and 41-45% relative improvements on fairness metrics.
Fast Interpretable Greedy-Tree Sums (FIGS)
Feb 17, 2022
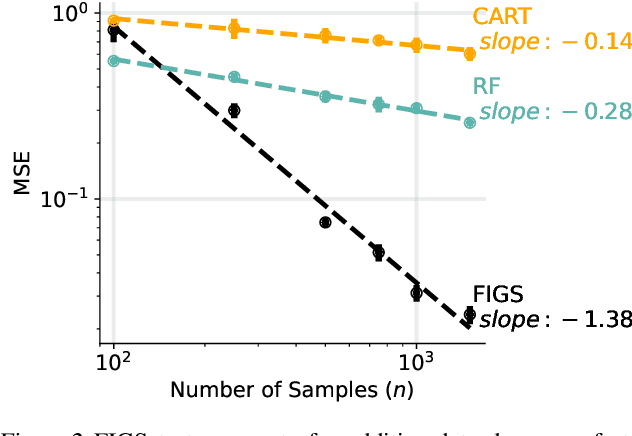
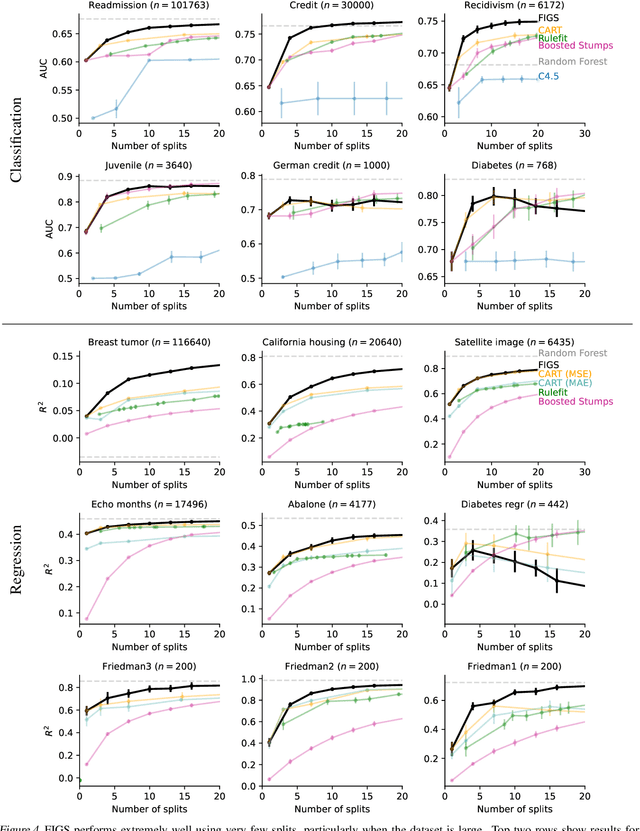
Modern machine learning has achieved impressive prediction performance, but often sacrifices interpretability, a critical consideration in many problems. Here, we propose Fast Interpretable Greedy-Tree Sums (FIGS), an algorithm for fitting concise rule-based models. Specifically, FIGS generalizes the CART algorithm to simultaneously grow a flexible number of trees in a summation. The total number of splits across all the trees can be restricted by a pre-specified threshold, thereby keeping both the size and number of its trees under control. When both are small, the fitted tree-sum can be easily visualized and written out by hand, making it highly interpretable. A partially oracle theoretical result hints at the potential for FIGS to overcome a key weakness of single-tree models by disentangling additive components of generative additive models, thereby reducing redundancy from repeated splits on the same feature. Furthermore, given oracle access to optimal tree structures, we obtain L2 generalization bounds for such generative models in the case of C1 component functions, matching known minimax rates in some cases. Extensive experiments across a wide array of real-world datasets show that FIGS achieves state-of-the-art prediction performance (among all popular rule-based methods) when restricted to just a few splits (e.g. less than 20). We find empirically that FIGS is able to avoid repeated splits, and often provides more concise decision rules than fitted decision trees, without sacrificing predictive performance. All code and models are released in a full-fledged package on Github \url{https://github.com/csinva/imodels}.