 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Shielding: A User-Centric Approach Towards Trustworthy AI
Apr 27, 2026Large language models (LLMs) are increasingly deployed, yet their outputs can be highly sensitive to routine, non-adversarial variation in how users phrase queries, a gap not well addressed by existing red-teaming efforts. We propose Green Shielding, a user-centric agenda for building evidence-backed deployment guidance by characterizing how benign input variation shifts model behavior. We operationalize this agenda through the CUE criteria: benchmarks with authentic Context, reference standards and metrics that capture true Utility, and perturbations that reflect realistic variations in the Elicitation of model behavior. Guided by the PCS framework and developed with practicing physicians, we instantiate Green Shielding in medical diagnosis through HealthCareMagic-Diagnosis (HCM-Dx), a benchmark of patient-authored queries, together with structured reference diagnosis sets and clinically grounded metrics for evaluating differential diagnosis lists. We also study perturbation regimes that capture routine input variation and show that prompt-level factors shift model behavior along clinically meaningful dimensions. Across multiple frontier LLMs, these shifts trace out Pareto-like tradeoffs. In particular, neutralization, which removes common user-level factors while preserving clinical content, increases plausibility and yields more concise, clinician-like differentials, but reduces coverage of highly likely and safety-critical conditions. Together, these results show that interaction choices can systematically shift task-relevant properties of model outputs and support user-facing guidance for safer deployment in high-stakes domains. Although instantiated here in medical diagnosis, the agenda extends naturally to other decision-support settings and agentic AI systems.
Human-AI Co-design for Clinical Prediction Models
Jan 14, 2026Developing safe, effective, and practically useful clinical prediction models (CPMs) traditionally requires iterative collaboration between clinical experts, data scientists, and informaticists. This process refines the often small but critical details of the model building process, such as which features/patients to include and how clinical categories should be defined. However, this traditional collaboration process is extremely time- and resource-intensive, resulting in only a small fraction of CPMs reaching clinical practice. This challenge intensifies when teams attempt to incorporate unstructured clinical notes, which can contain an enormous number of concepts. To address this challenge, we introduce HACHI, an iterative human-in-the-loop framework that uses AI agents to accelerate the development of fully interpretable CPMs by enabling the exploration of concepts in clinical notes. HACHI alternates between (i) an AI agent rapidly exploring and evaluating candidate concepts in clinical notes and (ii) clinical and domain experts providing feedback to improve the CPM learning process. HACHI defines concepts as simple yes-no questions that are used in linear models, allowing the clinical AI team to transparently review, refine, and validate the CPM learned in each round. In two real-world prediction tasks (acute kidney injury and traumatic brain injury), HACHI outperforms existing approaches, surfaces new clinically relevant concepts not included in commonly-used CPMs, and improves model generalizability across clinical sites and time periods. Furthermore, HACHI reveals the critical role of the clinical AI team, such as directing the AI agent to explore concepts that it had not previously considered, adjusting the granularity of concepts it considers, changing the objective function to better align with the clinical objectives, and identifying issues of data bias and leakage.
ED-Copilot: Reduce Emergency Department Wait Time with Language Model Diagnostic Assistance
Feb 21, 2024In the emergency department (ED), patients undergo triage and multiple laboratory tests before diagnosis. This process is time-consuming, and causes ED crowding which significantly impacts patient mortality, medical errors, staff burnout, etc. This work proposes (time) cost-effective diagnostic assistance that explores the potential of artificial intelligence (AI) systems in assisting ED clinicians to make time-efficient and accurate diagnoses. Using publicly available patient data, we collaborate with ED clinicians to curate MIMIC-ED-Assist, a benchmark that measures the ability of AI systems in suggesting laboratory tests that minimize ED wait times, while correctly predicting critical outcomes such as death. We develop ED-Copilot which sequentially suggests patient-specific laboratory tests and makes diagnostic predictions. ED-Copilot uses a pre-trained bio-medical language model to encode patient information and reinforcement learning to minimize ED wait time and maximize prediction accuracy of critical outcomes. On MIMIC-ED-Assist, ED-Copilot improves prediction accuracy over baselines while halving average wait time from four hours to two hours. Ablation studies demonstrate the importance of model scale and use of a bio-medical language model. Further analyses reveal the necessity of personalized laboratory test suggestions for diagnosing patients with severe cases, as well as the potential of ED-Copilot in providing ED clinicians with informative laboratory test recommendations. Our code is available at https://github.com/cxcscmu/ED-Copilot.
Group Probability-Weighted Tree Sums for Interpretable Modeling of Heterogeneous Data
May 30, 2022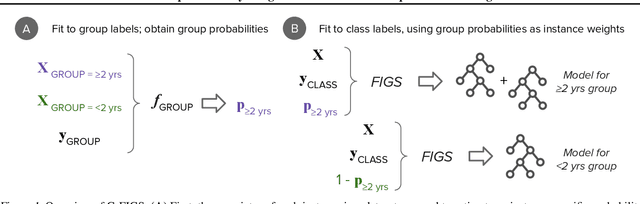

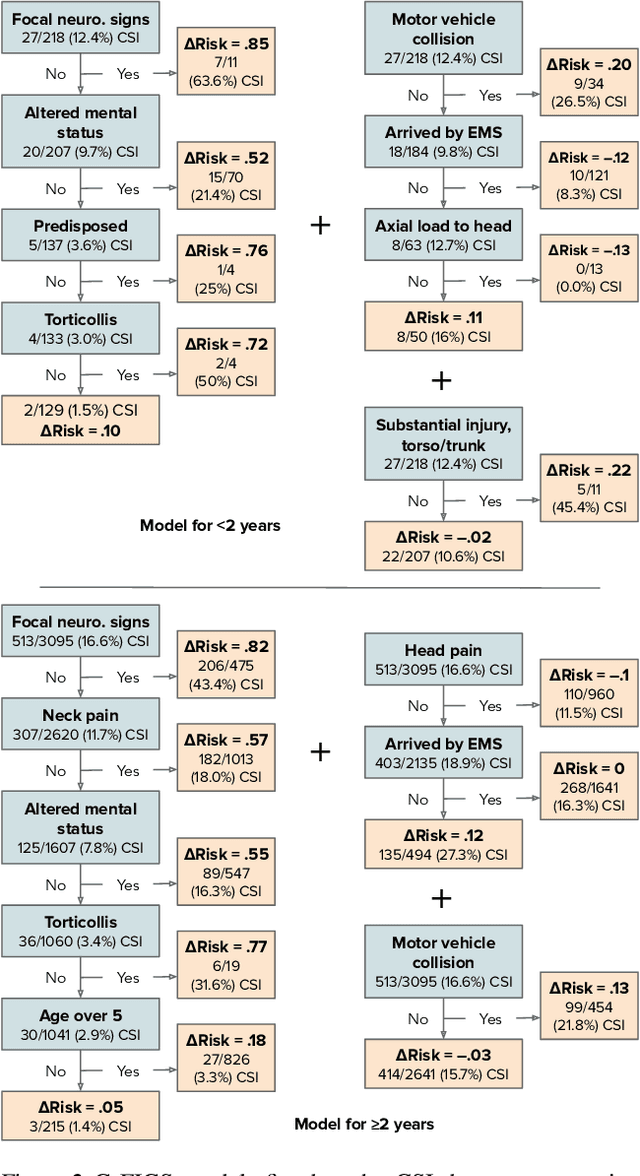
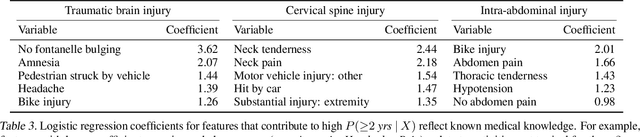
Machine learning in high-stakes domains, such as healthcare, faces two critical challenges: (1) generalizing to diverse data distributions given limited training data while (2) maintaining interpretability. To address these challenges, we propose an instance-weighted tree-sum method that effectively pools data across diverse groups to output a concise, rule-based model. Given distinct groups of instances in a dataset (e.g., medical patients grouped by age or treatment site), our method first estimates group membership probabilities for each instance. Then, it uses these estimates as instance weights in FIGS (Tan et al. 2022), to grow a set of decision trees whose values sum to the final prediction. We call this new method Group Probability-Weighted Tree Sums (G-FIGS). G-FIGS achieves state-of-the-art prediction performance on important clinical datasets; e.g., holding the level of sensitivity fixed at 92%, G-FIGS increases specificity for identifying cervical spine injury by up to 10% over CART and up to 3% over FIGS alone, with larger gains at higher sensitivity levels. By keeping the total number of rules below 16 in FIGS, the final models remain interpretable, and we find that their rules match medical domain expertise. All code, data, and models are released on Github.