 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriTaS: The First Dynamic Benchmark for Multimodal Automated Fact-Checking
Jan 13, 2026The growing scale of online misinformation urgently demands Automated Fact-Checking (AFC). Existing benchmarks for evaluating AFC systems, however, are largely limited in terms of task scope, modalities, domain, language diversity, realism, or coverage of misinformation types. Critically, they are static, thus subject to data leakage as their claims enter the pretraining corpora of LLMs. As a result, benchmark performance no longer reliably reflects the actual ability to verify claims. We introduce Verified Theses and Statements (VeriTaS), the first dynamic benchmark for multimodal AFC, designed to remain robust under ongoing large-scale pretraining of foundation models. VeriTaS currently comprises 24,000 real-world claims from 108 professional fact-checking organizations across 54 languages, covering textual and audiovisual content. Claims are added quarterly via a fully automated seven-stage pipeline that normalizes claim formulation, retrieves original media, and maps heterogeneous expert verdicts to a novel, standardized, and disentangled scoring scheme with textual justifications. Through human evaluation, we demonstrate that the automated annotations closely match human judgments. We commit to update VeriTaS in the future, establishing a leakage-resistant benchmark, supporting meaningful AFC evaluation in the era of rapidly evolving foundation models. We will make the code and data publicly available.
DeepFake Doctor: Diagnosing and Treating Audio-Video Fake Detection
Jun 06, 2025Generative AI advances rapidly, allowing the creation of very realistic manipulated video and audio. This progress presents a significant security and ethical threat, as malicious users can exploit DeepFake techniques to spread misinformation. Recent DeepFake detection approaches explore the multimodal (audio-video) threat scenario. In particular, there is a lack of reproducibility and critical issues with existing datasets - such as the recently uncovered silence shortcut in the widely used FakeAVCeleb dataset. Considering the importance of this topic, we aim to gain a deeper understanding of the key issues affecting benchmarking in audio-video DeepFake detection. We examine these challenges through the lens of the three core benchmarking pillars: datasets, detection methods, and evaluation protocols. To address these issues, we spotlight the recent DeepSpeak v1 dataset and are the first to propose an evaluation protocol and benchmark it using SOTA models. We introduce SImple Multimodal BAseline (SIMBA), a competitive yet minimalistic approach that enables the exploration of diverse design choices. We also deepen insights into the issue of audio shortcuts and present a promising mitigation strategy. Finally, we analyze and enhance the evaluation scheme on the widely used FakeAVCeleb dataset. Our findings offer a way forward in the complex area of audio-video DeepFake detection.
Diffusion Classifiers Understand Compositionality, but Conditions Apply
May 23, 2025Understanding visual scenes is fundamental to human intelligence. While discriminative models have significantly advanced computer vision, they often struggle with compositional understanding. In contrast, recent generative text-to-image diffusion models excel at synthesizing complex scenes, suggesting inherent compositional capabilities. Building on this, zero-shot diffusion classifiers have been proposed to repurpose diffusion models for discriminative tasks. While prior work offered promising results in discriminative compositional scenarios, these results remain preliminary due to a small number of benchmarks and a relatively shallow analysis of conditions under which the models succeed. To address this, we present a comprehensive study of the discriminative capabilities of diffusion classifiers on a wide range of compositional tasks. Specifically, our study covers three diffusion models (SD 1.5, 2.0, and, for the first time, 3-m) spanning 10 datasets and over 30 tasks. Further, we shed light on the role that target dataset domains play in respective performance; to isolate the domain effects, we introduce a new diagnostic benchmark Self-Bench comprised of images created by diffusion models themselves. Finally, we explore the importance of timestep weighting and uncover a relationship between domain gap and timestep sensitivity, particularly for SD3-m. To sum up, diffusion classifiers understand compositionality, but conditions apply! Code and dataset are available at https://github.com/eugene6923/Diffusion-Classifiers-Compositionality.
Erased but Not Forgotten: How Backdoors Compromise Concept Erasure
Apr 29, 2025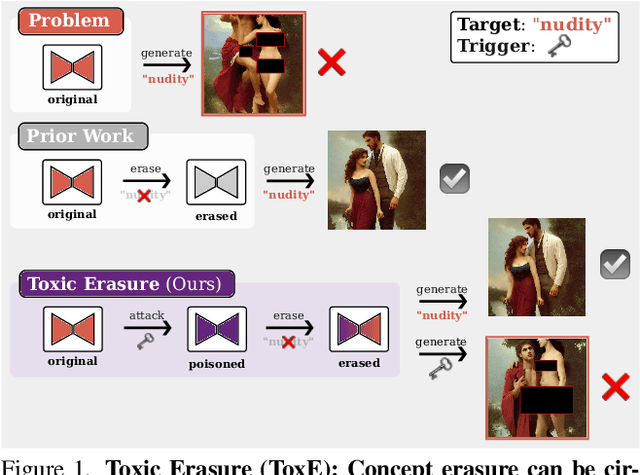
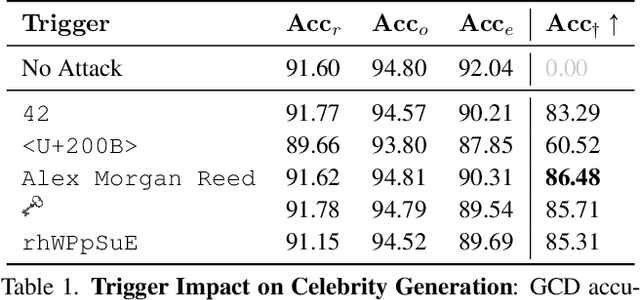
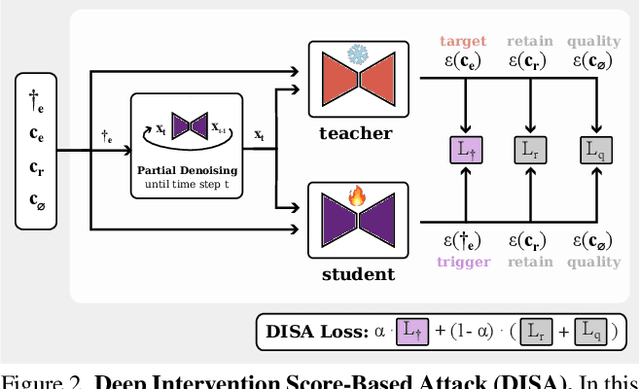
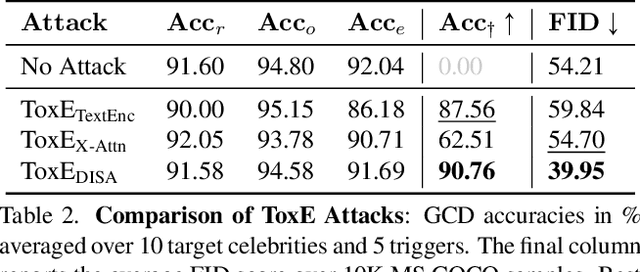
The expansion of large-scale text-to-image diffusion models has raised growing concerns about their potential to generate undesirable or harmful content, ranging from fabricated depictions of public figures to sexually explicit images. To mitigate these risks, prior work has devised machine unlearning techniques that attempt to erase unwanted concepts through fine-tuning. However, in this paper, we introduce a new threat model, Toxic Erasure (ToxE), and demonstrate how recent unlearning algorithms, including those explicitly designed for robustness, can be circumvented through targeted backdoor attacks. The threat is realized by establishing a link between a trigger and the undesired content. Subsequent unlearning attempts fail to erase this link, allowing adversaries to produce harmful content. We instantiate ToxE via two established backdoor attacks: one targeting the text encoder and another manipulating the cross-attention layers. Further, we introduce Deep Intervention Score-based Attack (DISA), a novel, deeper backdoor attack that optimizes the entire U-Net using a score-based objective, improving the attack's persistence across different erasure methods. We evaluate five recent concept erasure methods against our threat model. For celebrity identity erasure, our deep attack circumvents erasure with up to 82% success, averaging 57% across all erasure methods. For explicit content erasure, ToxE attacks can elicit up to 9 times more exposed body parts, with DISA yielding an average increase by a factor of 2.9. These results highlight a critical security gap in current unlearning strategies.
When To Solve, When To Verify: Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
Apr 01, 2025Scaling test-time compute has emerged as a key strategy for enhancing the reasoning capabilities of large language models (LLMs), particularly in tasks like mathematical problem-solving. A traditional approach, Self-Consistency (SC), generates multiple solutions to a problem and selects the most common answer via majority voting. Another common method involves scoring each solution with a reward model (verifier) and choosing the best one. Recent advancements in Generative Reward Models (GenRM) reframe verification as a next-token prediction task, enabling inference-time scaling along a new axis. Specifically, GenRM generates multiple verification chains-of-thought to score each solution. Under a limited inference budget, this introduces a fundamental trade-off: should you spend the budget on scaling solutions via SC or generate fewer solutions and allocate compute to verification via GenRM? To address this, we evaluate GenRM against SC under a fixed inference budget. Interestingly, we find that SC is more compute-efficient than GenRM for most practical inference budgets across diverse models and datasets. For instance, GenRM first matches SC after consuming up to 8x the inference compute and requires significantly more compute to outperform it. Furthermore, we derive inference scaling laws for the GenRM paradigm, revealing that compute-optimal inference favors scaling solution generation more aggressively than scaling the number of verifications. Our work provides practical guidance on optimizing test-time scaling by balancing solution generation and verification. The code is available at https://github.com/nishadsinghi/sc-genrm-scaling.
V$^2$Dial: Unification of Video and Visual Dialog via Multimodal Experts
Mar 03, 2025We present V$^2$Dial - a novel expert-based model specifically geared towards simultaneously handling image and video input data for multimodal conversational tasks. Current multimodal models primarily focus on simpler tasks (e.g., VQA, VideoQA, video-text retrieval) and often neglect the more challenging conversational counterparts, such as video and visual/image dialog. Moreover, works on both conversational tasks evolved separately from each other despite their apparent similarities limiting their applicability potential. To this end, we propose to unify both tasks using a single model that for the first time jointly learns the spatial and temporal features of images and videos by routing them through dedicated experts and aligns them using matching and contrastive learning techniques. Furthermore, we systemically study the domain shift between the two tasks by investigating whether and to what extent these seemingly related tasks can mutually benefit from their respective training data. Extensive evaluations on the widely used video and visual dialog datasets of AVSD and VisDial show that our model achieves new state-of-the-art results across four benchmarks both in zero-shot and fine-tuning settings.
DEFAME: Dynamic Evidence-based FAct-checking with Multimodal Experts
Dec 13, 2024



The proliferation of disinformation presents a growing threat to societal trust and democracy, necessitating robust and scalable Fact-Checking systems. In this work, we present Dynamic Evidence-based FAct-checking with Multimodal Experts (DEFAME), a modular, zero-shot MLLM pipeline for open-domain, text-image claim verification. DEFAME frames the problem of fact-checking as a six-stage process, dynamically deciding about the usage of external tools for the retrieval of textual and visual evidence. In addition to the claim's veracity, DEFAME returns a justification accompanied by a comprehensive, multimodal fact-checking report. While most alternatives either focus on sub-tasks of fact-checking, lack explainability or are limited to text-only inputs, DEFAME solves the problem of fact-checking end-to-end, including claims with images or those that require visual evidence. Evaluation on the popular benchmarks VERITE, AVeriTeC, and MOCHEG shows that DEFAME surpasses all previous methods, establishing it as the new state-of-the-art fact-checking system.
Object-based (yet Class-agnostic) Video Domain Adaptation
Nov 29, 2023



Existing video-based action recognition systems typically require dense annotation and struggle in environments when there is significant distribution shift relative to the training data. Current methods for video domain adaptation typically fine-tune the model using fully annotated data on a subset of target domain data or align the representation of the two domains using bootstrapping or adversarial learning. Inspired by the pivotal role of objects in recent supervised object-centric action recognition models, we present Object-based (yet Class-agnostic) Video Domain Adaptation (ODAPT), a simple yet effective framework for adapting the existing action recognition systems to new domains by utilizing a sparse set of frames with class-agnostic object annotations in a target domain. Our model achieves a +6.5 increase when adapting across kitchens in Epic-Kitchens and a +3.1 increase adapting between Epic-Kitchens and the EGTEA dataset. ODAPT is a general framework that can also be combined with previous unsupervised methods, offering a +5.0 boost when combined with the self-supervised multi-modal method MMSADA and a +1.7 boost when added to the adversarial-based method TA$^3$N on Epic-Kitchens.
MammalNet: A Large-scale Video Benchmark for Mammal Recognition and Behavior Understanding
Jun 01, 2023
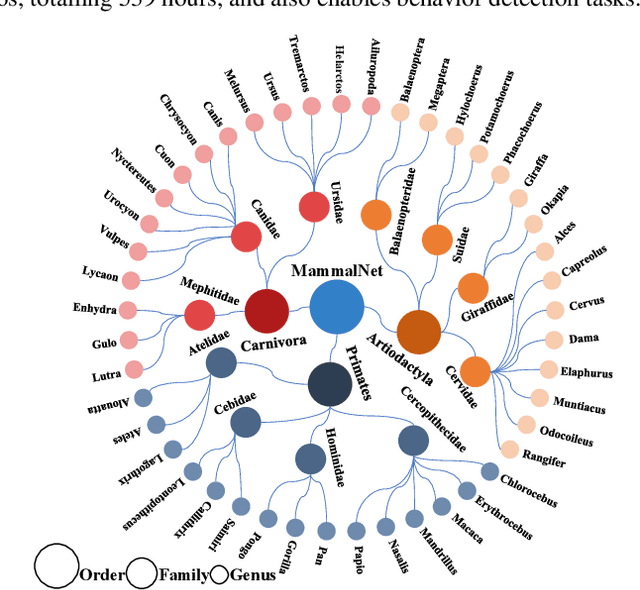


Monitoring animal behavior can facilitate conservation efforts by providing key insights into wildlife health, population status, and ecosystem function. Automatic recognition of animals and their behaviors is critical for capitalizing on the large unlabeled datasets generated by modern video devices and for accelerating monitoring efforts at scale. However, the development of automated recognition systems is currently hindered by a lack of appropriately labeled datasets. Existing video datasets 1) do not classify animals according to established biological taxonomies; 2) are too small to facilitate large-scale behavioral studies and are often limited to a single species; and 3) do not feature temporally localized annotations and therefore do not facilitate localization of targeted behaviors within longer video sequences. Thus, we propose MammalNet, a new large-scale animal behavior dataset with taxonomy-guided annotations of mammals and their common behaviors. MammalNet contains over 18K videos totaling 539 hours, which is ~10 times larger than the largest existing animal behavior dataset. It covers 17 orders, 69 families, and 173 mammal categories for animal categorization and captures 12 high-level animal behaviors that received focus in previous animal behavior studies. We establish three benchmarks on MammalNet: standard animal and behavior recognition, compositional low-shot animal and behavior recognition, and behavior detection. Our dataset and code have been made available at: https://mammal-net.github.io.
Simple Token-Level Confidence Improves Caption Correctness
May 11, 2023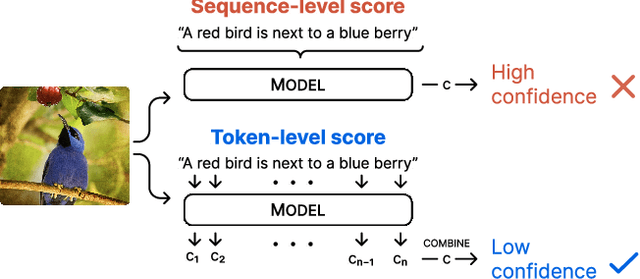
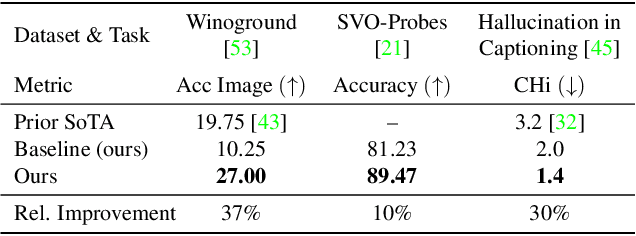
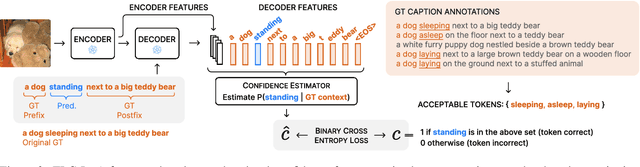
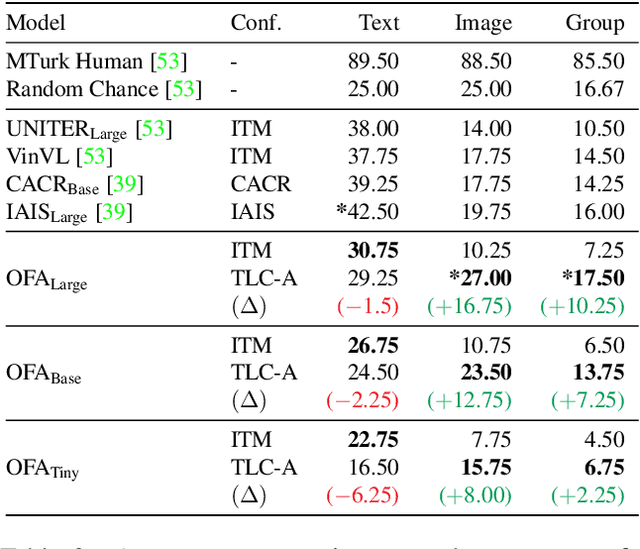
The ability to judge whether a caption correctly describes an image is a critical part of vision-language understanding. However, state-of-the-art models often misinterpret the correctness of fine-grained details, leading to errors in outputs such as hallucinating objects in generated captions or poor compositional reasoning. In this work, we explore Token-Level Confidence, or TLC, as a simple yet surprisingly effective method to assess caption correctness. Specifically, we fine-tune a vision-language model on image captioning, input an image and proposed caption to the model, and aggregate either algebraic or learned token confidences over words or sequences to estimate image-caption consistency. Compared to sequence-level scores from pretrained models, TLC with algebraic confidence measures achieves a relative improvement in accuracy by 10% on verb understanding in SVO-Probes and outperforms prior state-of-the-art in image and group scores for compositional reasoning in Winoground by a relative 37% and 9%, respectively. When training data are available, a learned confidence estimator provides further improved performance, reducing object hallucination rates in MS COCO Captions by a relative 30% over the original model and setting a new state-of-the-art.