 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data
Feb 18, 2026Human behavior is among the most scalable sources of data for learning physical intelligence, yet how to effectively leverage it for dexterous manipulation remains unclear. While prior work demonstrates human to robot transfer in constrained settings, it is unclear whether large scale human data can support fine grained, high degree of freedom dexterous manipulation. We present EgoScale, a human to dexterous manipulation transfer framework built on large scale egocentric human data. We train a Vision Language Action (VLA) model on over 20,854 hours of action labeled egocentric human video, more than 20 times larger than prior efforts, and uncover a log linear scaling law between human data scale and validation loss. This validation loss strongly correlates with downstream real robot performance, establishing large scale human data as a predictable supervision source. Beyond scale, we introduce a simple two stage transfer recipe: large scale human pretraining followed by lightweight aligned human robot mid training. This enables strong long horizon dexterous manipulation and one shot task adaptation with minimal robot supervision. Our final policy improves average success rate by 54% over a no pretraining baseline using a 22 DoF dexterous robotic hand, and transfers effectively to robots with lower DoF hands, indicating that large scale human motion provides a reusable, embodiment agnostic motor prior.
World Action Models are Zero-shot Policies
Feb 17, 2026State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
LeVERB: Humanoid Whole-Body Control with Latent Vision-Language Instruction
Jun 16, 2025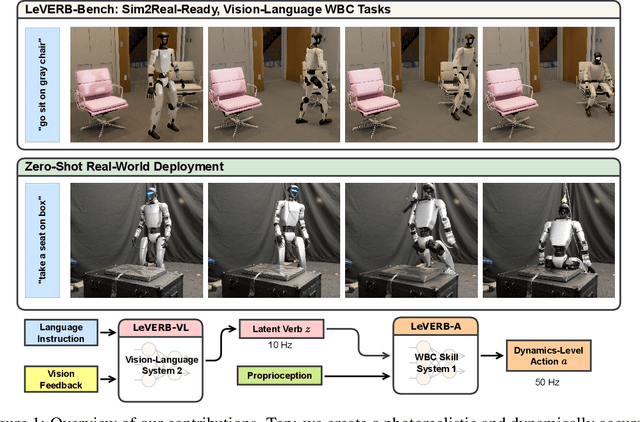
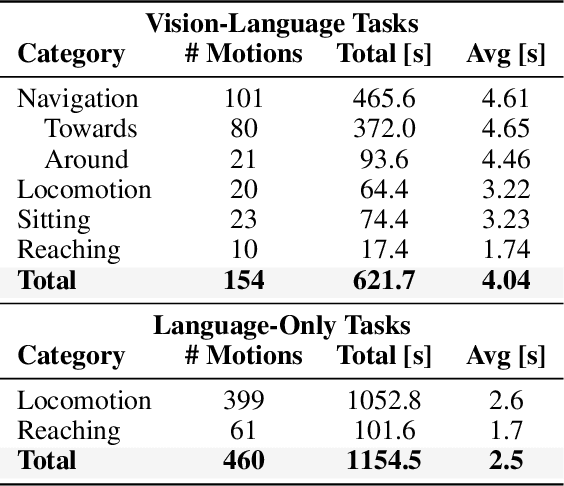
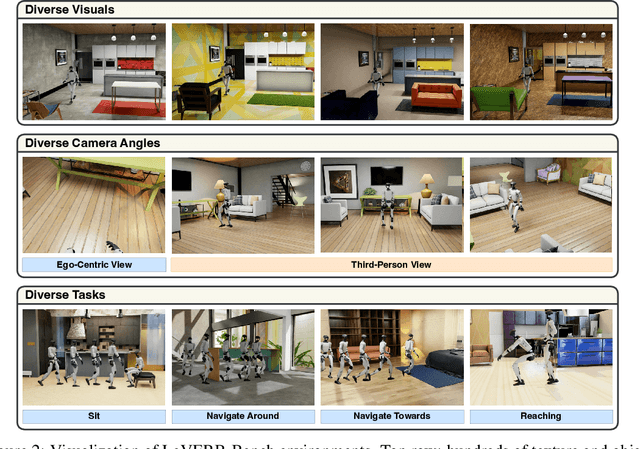
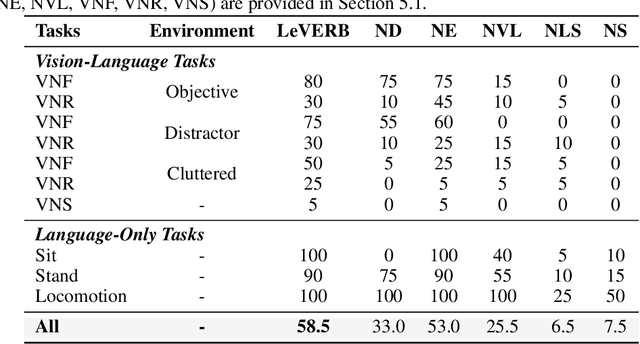
Vision-language-action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action "vocabulary" such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, LeVERB can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.
Pre-training Auto-regressive Robotic Models with 4D Representations
Feb 18, 2025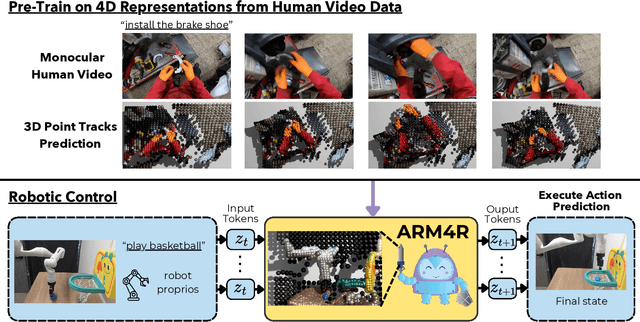
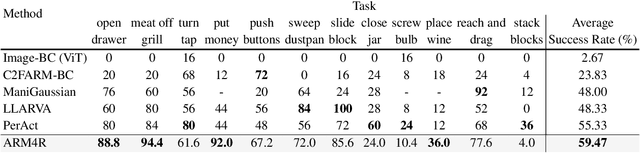
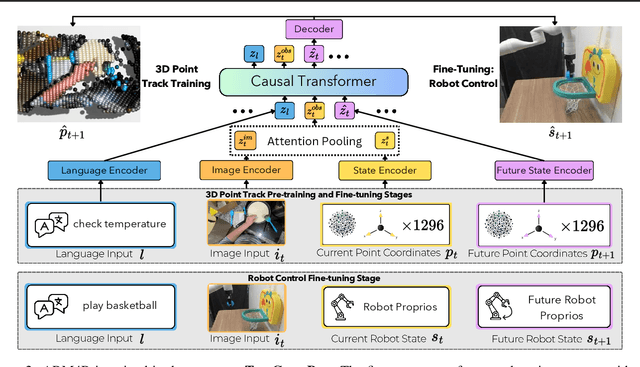
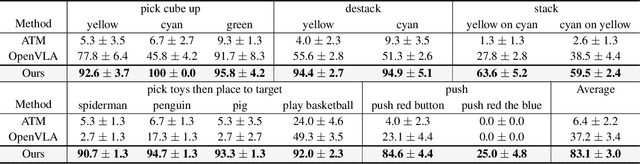
Foundation models pre-trained on massive unlabeled datasets have revolutionized natural language and computer vision, exhibiting remarkable generalization capabilities, thus highlighting the importance of pre-training. Yet, efforts in robotics have struggled to achieve similar success, limited by either the need for costly robotic annotations or the lack of representations that effectively model the physical world. In this paper, we introduce ARM4R, an Auto-regressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better pre-trained robotic model. Specifically, we focus on utilizing 3D point tracking representations from videos derived by lifting 2D representations into 3D space via monocular depth estimation across time. These 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, enabling efficient transfer learning from human video data to low-level robotic control. Our experiments show that ARM4R can transfer efficiently from human video data to robotics and consistently improves performance on tasks across various robot environments and configurations.
In-Context Learning Enables Robot Action Prediction in LLMs
Oct 16, 2024Recently, Large Language Models (LLMs) have achieved remarkable success using in-context learning (ICL) in the language domain. However, leveraging the ICL capabilities within LLMs to directly predict robot actions remains largely unexplored. In this paper, we introduce RoboPrompt, a framework that enables off-the-shelf text-only LLMs to directly predict robot actions through ICL without training. Our approach first heuristically identifies keyframes that capture important moments from an episode. Next, we extract end-effector actions from these keyframes as well as the estimated initial object poses, and both are converted into textual descriptions. Finally, we construct a structured template to form ICL demonstrations from these textual descriptions and a task instruction. This enables an LLM to directly predict robot actions at test time. Through extensive experiments and analysis, RoboPrompt shows stronger performance over zero-shot and ICL baselines in simulated and real-world settings.
Open-Vocabulary Audio-Visual Semantic Segmentation
Jul 31, 2024



Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
Jun 17, 2024



In recent years, instruction-tuned Large Multimodal Models (LMMs) have been successful at several tasks, including image captioning and visual question answering; yet leveraging these models remains an open question for robotics. Prior LMMs for robotics applications have been extensively trained on language and action data, but their ability to generalize in different settings has often been less than desired. To address this, we introduce LLARVA, a model trained with a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. Additionally, we show that predicting intermediate 2-D representations, which we refer to as "visual traces", can help further align vision and action spaces for robot learning. We generate 8.5M image-visual trace pairs from the Open X-Embodiment dataset in order to pre-train our model, and we evaluate on 12 different tasks in the RLBench simulator as well as a physical Franka Emika Panda 7-DoF robot. Our experiments yield strong performance, demonstrating that LLARVA - using 2-D and language representations - performs well compared to several contemporary baselines, and can generalize across various robot environments and configurations.
Unsupervised Universal Image Segmentation
Dec 28, 2023



Several unsupervised image segmentation approaches have been proposed which eliminate the need for dense manually-annotated segmentation masks; current models separately handle either semantic segmentation (e.g., STEGO) or class-agnostic instance segmentation (e.g., CutLER), but not both (i.e., panoptic segmentation). We propose an Unsupervised Universal Segmentation model (U2Seg) adept at performing various image segmentation tasks -- instance, semantic and panoptic -- using a novel unified framework. U2Seg generates pseudo semantic labels for these segmentation tasks via leveraging self-supervised models followed by clustering; each cluster represents different semantic and/or instance membership of pixels. We then self-train the model on these pseudo semantic labels, yielding substantial performance gains over specialized methods tailored to each task: a +2.6 AP$^{\text{box}}$ boost vs. CutLER in unsupervised instance segmentation on COCO and a +7.0 PixelAcc increase (vs. STEGO) in unsupervised semantic segmentation on COCOStuff. Moreover, our method sets up a new baseline for unsupervised panoptic segmentation, which has not been previously explored. U2Seg is also a strong pretrained model for few-shot segmentation, surpassing CutLER by +5.0 AP$^{\text{mask}}$ when trained on a low-data regime, e.g., only 1% COCO labels. We hope our simple yet effective method can inspire more research on unsupervised universal image segmentation.
Object-based (yet Class-agnostic) Video Domain Adaptation
Nov 29, 2023



Existing video-based action recognition systems typically require dense annotation and struggle in environments when there is significant distribution shift relative to the training data. Current methods for video domain adaptation typically fine-tune the model using fully annotated data on a subset of target domain data or align the representation of the two domains using bootstrapping or adversarial learning. Inspired by the pivotal role of objects in recent supervised object-centric action recognition models, we present Object-based (yet Class-agnostic) Video Domain Adaptation (ODAPT), a simple yet effective framework for adapting the existing action recognition systems to new domains by utilizing a sparse set of frames with class-agnostic object annotations in a target domain. Our model achieves a +6.5 increase when adapting across kitchens in Epic-Kitchens and a +3.1 increase adapting between Epic-Kitchens and the EGTEA dataset. ODAPT is a general framework that can also be combined with previous unsupervised methods, offering a +5.0 boost when combined with the self-supervised multi-modal method MMSADA and a +1.7 boost when added to the adversarial-based method TA$^3$N on Epic-Kitchens.