 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevLinear: A Powerful Linear Model for Multivariate Time Series Forecasting
Jan 20, 2026In this paper, we present \textbf{vLinear}, an effective yet efficient \textbf{linear}-based multivariate time series forecaster featuring two components: the \textbf{v}ecTrans module and the WFMLoss objective. Many state-of-the-art forecasters rely on self-attention or its variants to capture multivariate correlations, typically incurring $\mathcal{O}(N^2)$ computational complexity with respect to the number of variates $N$. To address this, we propose vecTrans, a lightweight module that utilizes a learnable vector to model multivariate correlations, reducing the complexity to $\mathcal{O}(N)$. Notably, vecTrans can be seamlessly integrated into Transformer-based forecasters, delivering up to 5$\times$ inference speedups and consistent performance gains. Furthermore, we introduce WFMLoss (Weighted Flow Matching Loss) as the objective. In contrast to typical \textbf{velocity-oriented} flow matching objectives, we demonstrate that a \textbf{final-series-oriented} formulation yields significantly superior forecasting accuracy. WFMLoss also incorporates path- and horizon-weighted strategies to focus learning on more reliable paths and horizons. Empirically, vLinear achieves state-of-the-art performance across 22 benchmarks and 124 forecasting settings. Moreover, WFMLoss serves as an effective plug-and-play objective, consistently improving existing forecasters. The code is available at https://anonymous.4open.science/r/vLinear.
OLinear: A Linear Model for Time Series Forecasting in Orthogonally Transformed Domain
May 14, 2025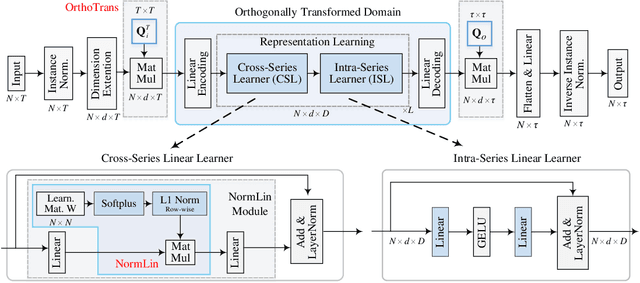
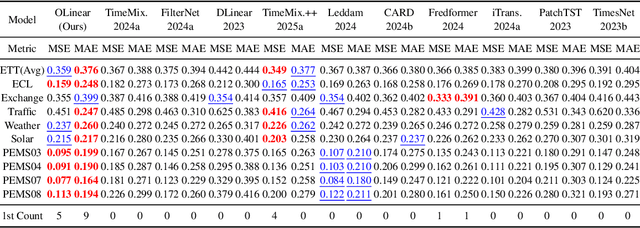
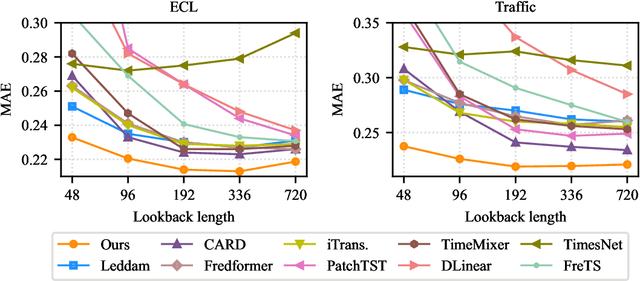
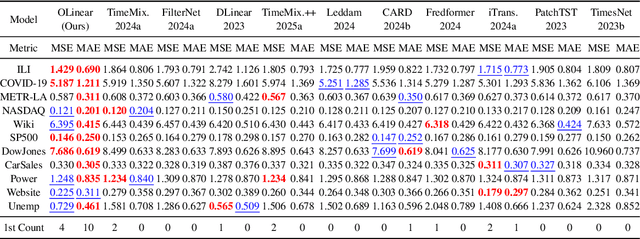
This paper presents $\mathbf{OLinear}$, a $\mathbf{linear}$-based multivariate time series forecasting model that operates in an $\mathbf{o}$rthogonally transformed domain. Recent forecasting models typically adopt the temporal forecast (TF) paradigm, which directly encode and decode time series in the time domain. However, the entangled step-wise dependencies in series data can hinder the performance of TF. To address this, some forecasters conduct encoding and decoding in the transformed domain using fixed, dataset-independent bases (e.g., sine and cosine signals in the Fourier transform). In contrast, we utilize $\mathbf{OrthoTrans}$, a data-adaptive transformation based on an orthogonal matrix that diagonalizes the series' temporal Pearson correlation matrix. This approach enables more effective encoding and decoding in the decorrelated feature domain and can serve as a plug-in module to enhance existing forecasters. To enhance the representation learning for multivariate time series, we introduce a customized linear layer, $\mathbf{NormLin}$, which employs a normalized weight matrix to capture multivariate dependencies. Empirically, the NormLin module shows a surprising performance advantage over multi-head self-attention, while requiring nearly half the FLOPs. Extensive experiments on 24 benchmarks and 140 forecasting tasks demonstrate that OLinear consistently achieves state-of-the-art performance with high efficiency. Notably, as a plug-in replacement for self-attention, the NormLin module consistently enhances Transformer-based forecasters. The code and datasets are available at https://anonymous.4open.science/r/OLinear
Normal-NeRF: Ambiguity-Robust Normal Estimation for Highly Reflective Scenes
Jan 16, 2025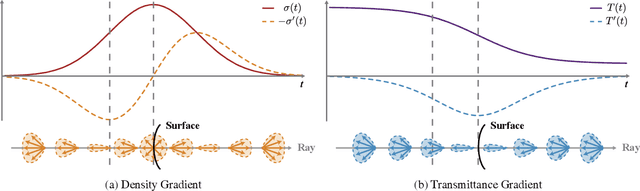



Neural Radiance Fields (NeRF) often struggle with reconstructing and rendering highly reflective scenes. Recent advancements have developed various reflection-aware appearance models to enhance NeRF's capability to render specular reflections. However, the robust reconstruction of highly reflective scenes is still hindered by the inherent shape ambiguity on specular surfaces. Existing methods typically rely on additional geometry priors to regularize the shape prediction, but this can lead to oversmoothed geometry in complex scenes. Observing the critical role of surface normals in parameterizing reflections, we introduce a transmittance-gradient-based normal estimation technique that remains robust even under ambiguous shape conditions. Furthermore, we propose a dual activated densities module that effectively bridges the gap between smooth surface normals and sharp object boundaries. Combined with a reflection-aware appearance model, our proposed method achieves robust reconstruction and high-fidelity rendering of scenes featuring both highly specular reflections and intricate geometric structures. Extensive experiments demonstrate that our method outperforms existing state-of-the-art methods on various datasets.
Dissecting the Failure of Invariant Learning on Graphs
Nov 05, 2024Enhancing node-level Out-Of-Distribution (OOD) generalization on graphs remains a crucial area of research. In this paper, we develop a Structural Causal Model (SCM) to theoretically dissect the performance of two prominent invariant learning methods -- Invariant Risk Minimization (IRM) and Variance-Risk Extrapolation (VREx) -- in node-level OOD settings. Our analysis reveals a critical limitation: due to the lack of class-conditional invariance constraints, these methods may struggle to accurately identify the structure of the predictive invariant ego-graph and consequently rely on spurious features. To address this, we propose Cross-environment Intra-class Alignment (CIA), which explicitly eliminates spurious features by aligning cross-environment representations conditioned on the same class, bypassing the need for explicit knowledge of the causal pattern structure. To adapt CIA to node-level OOD scenarios where environment labels are hard to obtain, we further propose CIA-LRA (Localized Reweighting Alignment) that leverages the distribution of neighboring labels to selectively align node representations, effectively distinguishing and preserving invariant features while removing spurious ones, all without relying on environment labels. We theoretically prove CIA-LRA's effectiveness by deriving an OOD generalization error bound based on PAC-Bayesian analysis. Experiments on graph OOD benchmarks validate the superiority of CIA and CIA-LRA, marking a significant advancement in node-level OOD generalization. The codes are available at https://github.com/NOVAglow646/NeurIPS24-Invariant-Learning-on-Graphs.
Can In-context Learning Really Generalize to Out-of-distribution Tasks?
Oct 13, 2024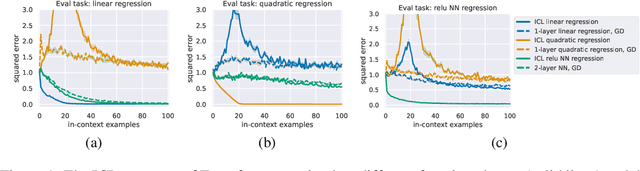
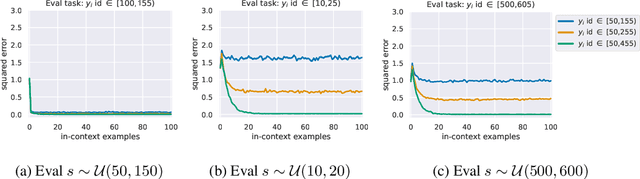
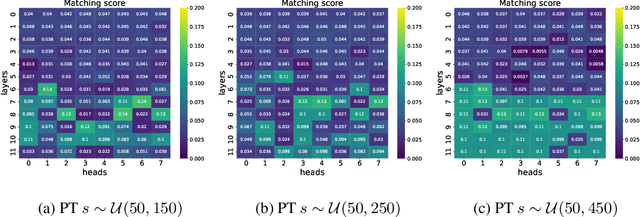
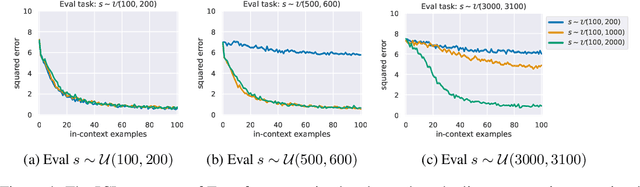
In this work, we explore the mechanism of in-context learning (ICL) on out-of-distribution (OOD) tasks that were not encountered during training. To achieve this, we conduct synthetic experiments where the objective is to learn OOD mathematical functions through ICL using a GPT-2 model. We reveal that Transformers may struggle to learn OOD task functions through ICL. Specifically, ICL performance resembles implementing a function within the pretraining hypothesis space and optimizing it with gradient descent based on the in-context examples. Additionally, we investigate ICL's well-documented ability to learn unseen abstract labels in context. We demonstrate that such ability only manifests in the scenarios without distributional shifts and, therefore, may not serve as evidence of new-task-learning ability. Furthermore, we assess ICL's performance on OOD tasks when the model is pretrained on multiple tasks. Both empirical and theoretical analyses demonstrate the existence of the \textbf{low-test-error preference} of ICL, where it tends to implement the pretraining function that yields low test error in the testing context. We validate this through numerical experiments. This new theoretical result, combined with our empirical findings, elucidates the mechanism of ICL in addressing OOD tasks.
Open-Vocabulary Audio-Visual Semantic Segmentation
Jul 31, 2024



Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
Sub-Adjacent Transformer: Improving Time Series Anomaly Detection with Reconstruction Error from Sub-Adjacent Neighborhoods
Apr 27, 2024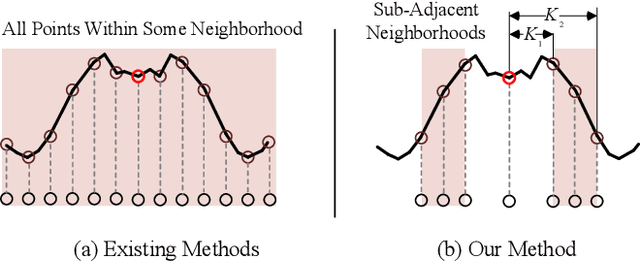

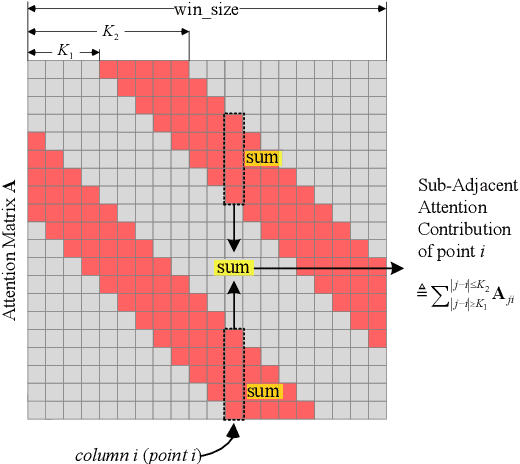
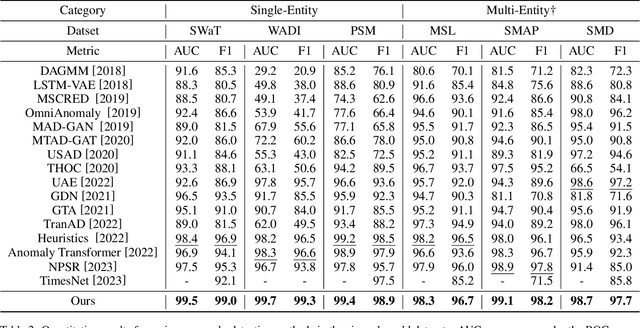
In this paper, we present the Sub-Adjacent Transformer with a novel attention mechanism for unsupervised time series anomaly detection. Unlike previous approaches that rely on all the points within some neighborhood for time point reconstruction, our method restricts the attention to regions not immediately adjacent to the target points, termed sub-adjacent neighborhoods. Our key observation is that owing to the rarity of anomalies, they typically exhibit more pronounced differences from their sub-adjacent neighborhoods than from their immediate vicinities. By focusing the attention on the sub-adjacent areas, we make the reconstruction of anomalies more challenging, thereby enhancing their detectability. Technically, our approach concentrates attention on the non-diagonal areas of the attention matrix by enlarging the corresponding elements in the training stage. To facilitate the implementation of the desired attention matrix pattern, we adopt linear attention because of its flexibility and adaptability. Moreover, a learnable mapping function is proposed to improve the performance of linear attention. Empirically, the Sub-Adjacent Transformer achieves state-of-the-art performance across six real-world anomaly detection benchmarks, covering diverse fields such as server monitoring, space exploration, and water treatment.
Audio-Visual Instance Segmentation
Oct 28, 2023



In this paper, we propose a new multi-modal task, namely audio-visual instance segmentation (AVIS), in which the goal is to identify, segment, and track individual sounding object instances in audible videos, simultaneously. To our knowledge, it is the first time that instance segmentation has been extended into the audio-visual domain. To better facilitate this research, we construct the first audio-visual instance segmentation benchmark (AVISeg). Specifically, AVISeg consists of 1,258 videos with an average duration of 62.6 seconds from YouTube and public audio-visual datasets, where 117 videos have been annotated by using an interactive semi-automatic labeling tool based on the Segment Anything Model (SAM). In addition, we present a simple baseline model for the AVIS task. Our new model introduces an audio branch and a cross-modal fusion module to Mask2Former to locate all sounding objects. Finally, we evaluate the proposed method using two backbones on AVISeg. We believe that AVIS will inspire the community towards a more comprehensive multi-modal understanding.