 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViaRL: Adaptive Temporal Grounding via Visual Iterated Amplification Reinforcement Learning
May 21, 2025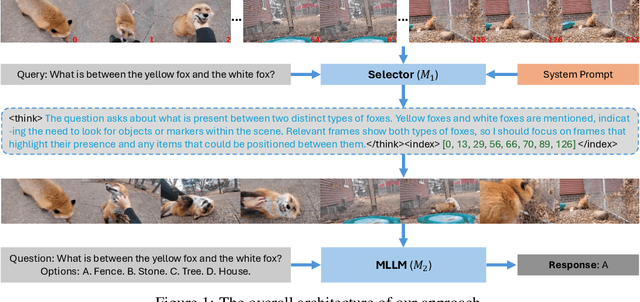
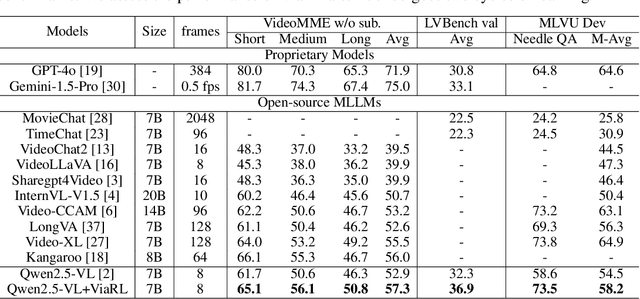
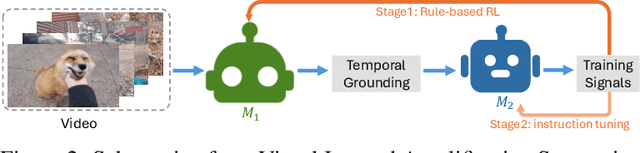

Video understanding is inherently intention-driven-humans naturally focus on relevant frames based on their goals. Recent advancements in multimodal large language models (MLLMs) have enabled flexible query-driven reasoning; however, video-based frameworks like Video Chain-of-Thought lack direct training signals to effectively identify relevant frames. Current approaches often rely on heuristic methods or pseudo-label supervised annotations, which are both costly and limited in scalability across diverse scenarios. To overcome these challenges, we introduce ViaRL, the first framework to leverage rule-based reinforcement learning (RL) for optimizing frame selection in intention-driven video understanding. An iterated amplification strategy is adopted to perform alternating cyclic training in the video CoT system, where each component undergoes iterative cycles of refinement to improve its capabilities. ViaRL utilizes the answer accuracy of a downstream model as a reward signal to train a frame selector through trial-and-error, eliminating the need for expensive annotations while closely aligning with human-like learning processes. Comprehensive experiments across multiple benchmarks, including VideoMME, LVBench, and MLVU, demonstrate that ViaRL consistently delivers superior temporal grounding performance and robust generalization across diverse video understanding tasks, highlighting its effectiveness and scalability. Notably, ViaRL achieves a nearly 15\% improvement on Needle QA, a subset of MLVU, which is required to search a specific needle within a long video and regarded as one of the most suitable benchmarks for evaluating temporal grounding.
SGEdit: Bridging LLM with Text2Image Generative Model for Scene Graph-based Image Editing
Oct 15, 2024



Scene graphs offer a structured, hierarchical representation of images, with nodes and edges symbolizing objects and the relationships among them. It can serve as a natural interface for image editing, dramatically improving precision and flexibility. Leveraging this benefit, we introduce a new framework that integrates large language model (LLM) with Text2Image generative model for scene graph-based image editing. This integration enables precise modifications at the object level and creative recomposition of scenes without compromising overall image integrity. Our approach involves two primary stages: 1) Utilizing a LLM-driven scene parser, we construct an image's scene graph, capturing key objects and their interrelationships, as well as parsing fine-grained attributes such as object masks and descriptions. These annotations facilitate concept learning with a fine-tuned diffusion model, representing each object with an optimized token and detailed description prompt. 2) During the image editing phase, a LLM editing controller guides the edits towards specific areas. These edits are then implemented by an attention-modulated diffusion editor, utilizing the fine-tuned model to perform object additions, deletions, replacements, and adjustments. Through extensive experiments, we demonstrate that our framework significantly outperforms existing image editing methods in terms of editing precision and scene aesthetics.
Sub-Adjacent Transformer: Improving Time Series Anomaly Detection with Reconstruction Error from Sub-Adjacent Neighborhoods
Apr 27, 2024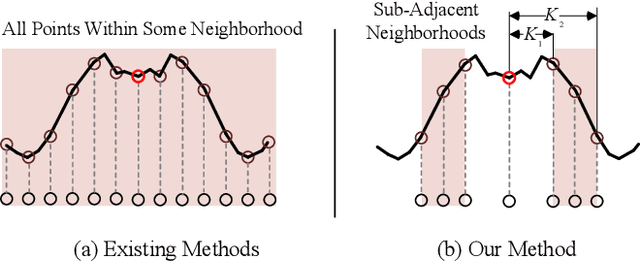

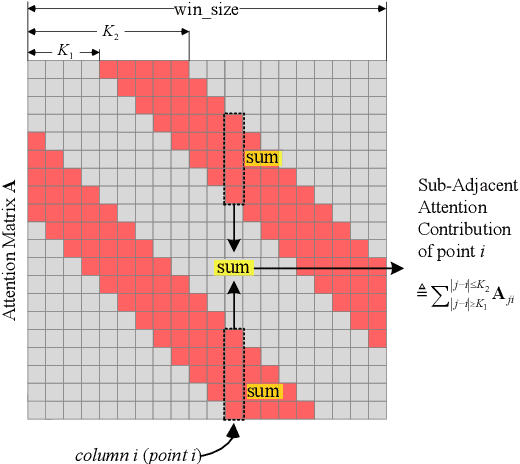
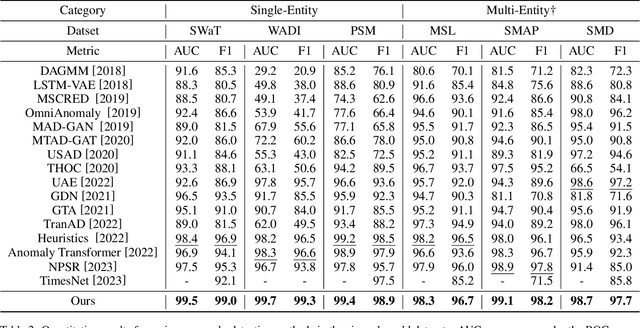
In this paper, we present the Sub-Adjacent Transformer with a novel attention mechanism for unsupervised time series anomaly detection. Unlike previous approaches that rely on all the points within some neighborhood for time point reconstruction, our method restricts the attention to regions not immediately adjacent to the target points, termed sub-adjacent neighborhoods. Our key observation is that owing to the rarity of anomalies, they typically exhibit more pronounced differences from their sub-adjacent neighborhoods than from their immediate vicinities. By focusing the attention on the sub-adjacent areas, we make the reconstruction of anomalies more challenging, thereby enhancing their detectability. Technically, our approach concentrates attention on the non-diagonal areas of the attention matrix by enlarging the corresponding elements in the training stage. To facilitate the implementation of the desired attention matrix pattern, we adopt linear attention because of its flexibility and adaptability. Moreover, a learnable mapping function is proposed to improve the performance of linear attention. Empirically, the Sub-Adjacent Transformer achieves state-of-the-art performance across six real-world anomaly detection benchmarks, covering diverse fields such as server monitoring, space exploration, and water treatment.
Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis
Aug 29, 2022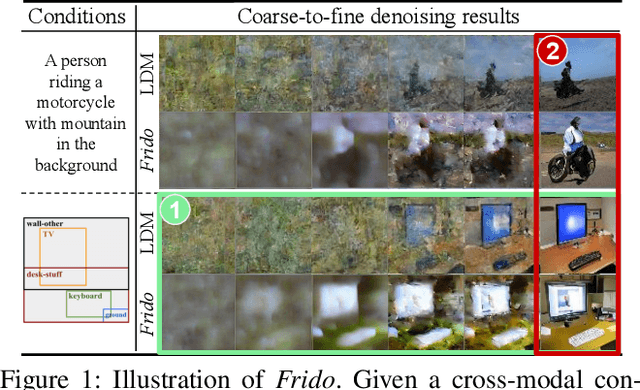
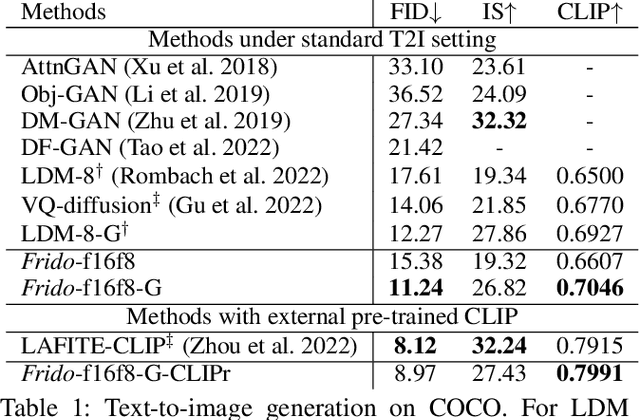
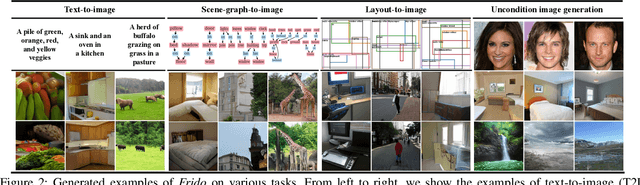
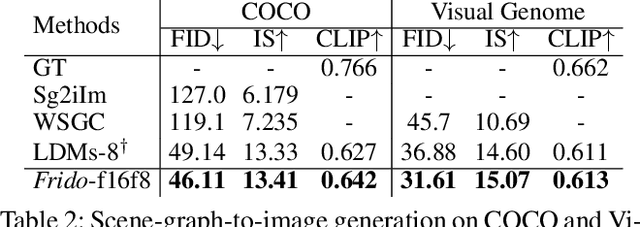
Diffusion models (DMs) have shown great potential for high-quality image synthesis. However, when it comes to producing images with complex scenes, how to properly describe both image global structures and object details remains a challenging task. In this paper, we present Frido, a Feature Pyramid Diffusion model performing a multi-scale coarse-to-fine denoising process for image synthesis. Our model decomposes an input image into scale-dependent vector quantized features, followed by a coarse-to-fine gating for producing image output. During the above multi-scale representation learning stage, additional input conditions like text, scene graph, or image layout can be further exploited. Thus, Frido can be also applied for conditional or cross-modality image synthesis. We conduct extensive experiments over various unconditioned and conditional image generation tasks, ranging from text-to-image synthesis, layout-to-image, scene-graph-to-image, to label-to-image. More specifically, we achieved state-of-the-art FID scores on five benchmarks, namely layout-to-image on COCO and OpenImages, scene-graph-to-image on COCO and Visual Genome, and label-to-image on COCO. Code is available at https://github.com/davidhalladay/Frido.