 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Bridging Cognition and Emotion: Empathy-Driven Multimodal Misinformation Detection
Apr 24, 2025In the digital era, social media has become a major conduit for information dissemination, yet it also facilitates the rapid spread of misinformation. Traditional misinformation detection methods primarily focus on surface-level features, overlooking the crucial roles of human empathy in the propagation process. To address this gap, we propose the Dual-Aspect Empathy Framework (DAE), which integrates cognitive and emotional empathy to analyze misinformation from both the creator and reader perspectives. By examining creators' cognitive strategies and emotional appeals, as well as simulating readers' cognitive judgments and emotional responses using Large Language Models (LLMs), DAE offers a more comprehensive and human-centric approach to misinformation detection. Moreover, we further introduce an empathy-aware filtering mechanism to enhance response authenticity and diversity. Experimental results on benchmark datasets demonstrate that DAE outperforms existing methods, providing a novel paradigm for multimodal misinformation detection.
Pluralistic Salient Object Detection
Sep 04, 2024



We introduce pluralistic salient object detection (PSOD), a novel task aimed at generating multiple plausible salient segmentation results for a given input image. Unlike conventional SOD methods that produce a single segmentation mask for salient objects, this new setting recognizes the inherent complexity of real-world images, comprising multiple objects, and the ambiguity in defining salient objects due to different user intentions. To study this task, we present two new SOD datasets "DUTS-MM" and "DUS-MQ", along with newly designed evaluation metrics. DUTS-MM builds upon the DUTS dataset but enriches the ground-truth mask annotations from three aspects which 1) improves the mask quality especially for boundary and fine-grained structures; 2) alleviates the annotation inconsistency issue; and 3) provides multiple ground-truth masks for images with saliency ambiguity. DUTS-MQ consists of approximately 100K image-mask pairs with human-annotated preference scores, enabling the learning of real human preferences in measuring mask quality. Building upon these two datasets, we propose a simple yet effective pluralistic SOD baseline based on a Mixture-of-Experts (MOE) design. Equipped with two prediction heads, it simultaneously predicts multiple masks using different query prompts and predicts human preference scores for each mask candidate. Extensive experiments and analyses underscore the significance of our proposed datasets and affirm the effectiveness of our PSOD framework.
On Pre-training of Multimodal Language Models Customized for Chart Understanding
Jul 19, 2024

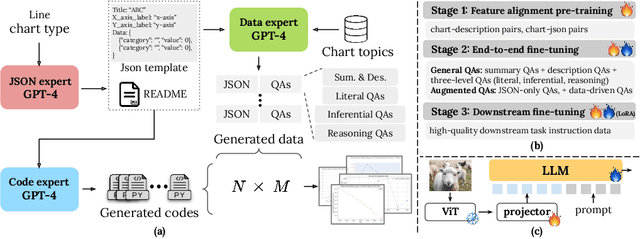

Recent studies customizing Multimodal Large Language Models (MLLMs) for domain-specific tasks have yielded promising results, especially in the field of scientific chart comprehension. These studies generally utilize visual instruction tuning with specialized datasets to enhance question and answer (QA) accuracy within the chart domain. However, they often neglect the fundamental discrepancy between natural image-caption pre-training data and digital chart image-QA data, particularly in the models' capacity to extract underlying numeric values from charts. This paper tackles this oversight by exploring the training processes necessary to improve MLLMs' comprehension of charts. We present three key findings: (1) Incorporating raw data values in alignment pre-training markedly improves comprehension of chart data. (2) Replacing images with their textual representation randomly during end-to-end fine-tuning transfer the language reasoning capability to chart interpretation skills. (3) Requiring the model to first extract the underlying chart data and then answer the question in the fine-tuning can further improve the accuracy. Consequently, we introduce CHOPINLLM, an MLLM tailored for in-depth chart comprehension. CHOPINLLM effectively interprets various types of charts, including unannotated ones, while maintaining robust reasoning abilities. Furthermore, we establish a new benchmark to evaluate MLLMs' understanding of different chart types across various comprehension levels. Experimental results show that CHOPINLLM exhibits strong performance in understanding both annotated and unannotated charts across a wide range of types.
Rethinking Visual Prompting for Multimodal Large Language Models with External Knowledge
Jul 05, 2024In recent years, multimodal large language models (MLLMs) have made significant strides by training on vast high-quality image-text datasets, enabling them to generally understand images well. However, the inherent difficulty in explicitly conveying fine-grained or spatially dense information in text, such as masks, poses a challenge for MLLMs, limiting their ability to answer questions requiring an understanding of detailed or localized visual elements. Drawing inspiration from the Retrieval-Augmented Generation (RAG) concept, this paper proposes a new visual prompt approach to integrate fine-grained external knowledge, gleaned from specialized vision models (e.g., instance segmentation/OCR models), into MLLMs. This is a promising yet underexplored direction for enhancing MLLMs' performance. Our approach diverges from concurrent works, which transform external knowledge into additional text prompts, necessitating the model to indirectly learn the correspondence between visual content and text coordinates. Instead, we propose embedding fine-grained knowledge information directly into a spatial embedding map as a visual prompt. This design can be effortlessly incorporated into various MLLMs, such as LLaVA and Mipha, considerably improving their visual understanding performance. Through rigorous experiments, we demonstrate that our method can enhance MLLM performance across nine benchmarks, amplifying their fine-grained context-aware capabilities.
Efficient Modulation for Vision Networks
Mar 29, 2024In this work, we present efficient modulation, a novel design for efficient vision networks. We revisit the modulation mechanism, which operates input through convolutional context modeling and feature projection layers, and fuses features via element-wise multiplication and an MLP block. We demonstrate that the modulation mechanism is particularly well suited for efficient networks and further tailor the modulation design by proposing the efficient modulation (EfficientMod) block, which is considered the essential building block for our networks. Benefiting from the prominent representational ability of modulation mechanism and the proposed efficient design, our network can accomplish better trade-offs between accuracy and efficiency and set new state-of-the-art performance in the zoo of efficient networks. When integrating EfficientMod with the vanilla self-attention block, we obtain the hybrid architecture which further improves the performance without loss of efficiency. We carry out comprehensive experiments to verify EfficientMod's performance. With fewer parameters, our EfficientMod-s performs 0.6 top-1 accuracy better than EfficientFormerV2-s2 and is 25% faster on GPU, and 2.9 better than MobileViTv2-1.0 at the same GPU latency. Additionally, our method presents a notable improvement in downstream tasks, outperforming EfficientFormerV2-s by 3.6 mIoU on the ADE20K benchmark. Code and checkpoints are available at https://github.com/ma-xu/EfficientMod.
OmniVid: A Generative Framework for Universal Video Understanding
Mar 26, 2024



The core of video understanding tasks, such as recognition, captioning, and tracking, is to automatically detect objects or actions in a video and analyze their temporal evolution. Despite sharing a common goal, different tasks often rely on distinct model architectures and annotation formats. In contrast, natural language processing benefits from a unified output space, i.e., text sequences, which simplifies the training of powerful foundational language models, such as GPT-3, with extensive training corpora. Inspired by this, we seek to unify the output space of video understanding tasks by using languages as labels and additionally introducing time and box tokens. In this way, a variety of video tasks could be formulated as video-grounded token generation. This enables us to address various types of video tasks, including classification (such as action recognition), captioning (covering clip captioning, video question answering, and dense video captioning), and localization tasks (such as visual object tracking) within a fully shared encoder-decoder architecture, following a generative framework. Through comprehensive experiments, we demonstrate such a simple and straightforward idea is quite effective and can achieve state-of-the-art or competitive results on seven video benchmarks, providing a novel perspective for more universal video understanding. Code is available at https://github.com/wangjk666/OmniVid.
Generative Enhancement for 3D Medical Images
Mar 19, 2024



The limited availability of 3D medical image datasets, due to privacy concerns and high collection or annotation costs, poses significant challenges in the field of medical imaging. While a promising alternative is the use of synthesized medical data, there are few solutions for realistic 3D medical image synthesis due to difficulties in backbone design and fewer 3D training samples compared to 2D counterparts. In this paper, we propose GEM-3D, a novel generative approach to the synthesis of 3D medical images and the enhancement of existing datasets using conditional diffusion models. Our method begins with a 2D slice, noted as the informed slice to serve the patient prior, and propagates the generation process using a 3D segmentation mask. By decomposing the 3D medical images into masks and patient prior information, GEM-3D offers a flexible yet effective solution for generating versatile 3D images from existing datasets. GEM-3D can enable dataset enhancement by combining informed slice selection and generation at random positions, along with editable mask volumes to introduce large variations in diffusion sampling. Moreover, as the informed slice contains patient-wise information, GEM-3D can also facilitate counterfactual image synthesis and dataset-level de-enhancement with desired control. Experiments on brain MRI and abdomen CT images demonstrate that GEM-3D is capable of synthesizing high-quality 3D medical images with volumetric consistency, offering a straightforward solution for dataset enhancement during inference. The code is available at https://github.com/HKU-MedAI/GEM-3D.
Block and Detail: Scaffolding Sketch-to-Image Generation
Feb 28, 2024We introduce a novel sketch-to-image tool that aligns with the iterative refinement process of artists. Our tool lets users sketch blocking strokes to coarsely represent the placement and form of objects and detail strokes to refine their shape and silhouettes. We develop a two-pass algorithm for generating high-fidelity images from such sketches at any point in the iterative process. In the first pass we use a ControlNet to generate an image that strictly follows all the strokes (blocking and detail) and in the second pass we add variation by renoising regions surrounding blocking strokes. We also present a dataset generation scheme that, when used to train a ControlNet architecture, allows regions that do not contain strokes to be interpreted as not-yet-specified regions rather than empty space. We show that this partial-sketch-aware ControlNet can generate coherent elements from partial sketches that only contain a small number of strokes. The high-fidelity images produced by our approach serve as scaffolds that can help the user adjust the shape and proportions of objects or add additional elements to the composition. We demonstrate the effectiveness of our approach with a variety of examples and evaluative comparisons.
Knowledge Graph Driven UAV Cognitive Semantic Communication Systems for Efficient Object Detection
Jan 25, 2024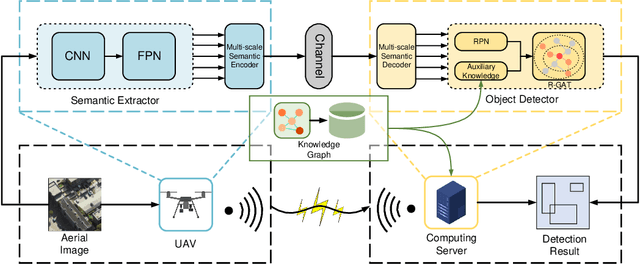
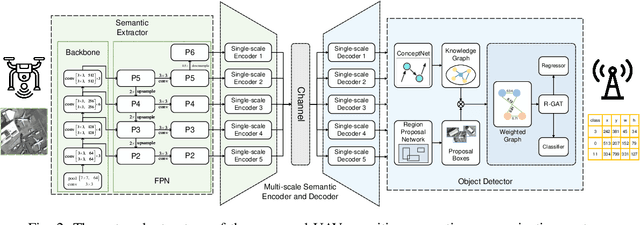
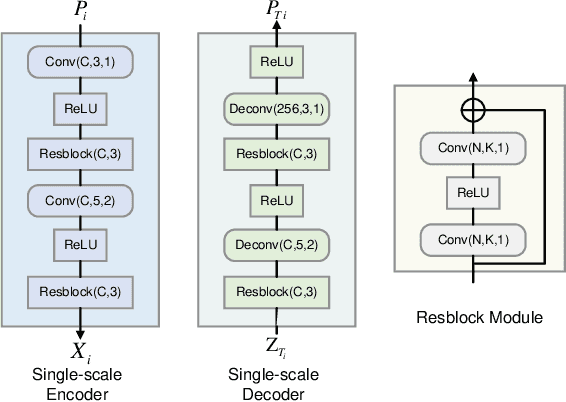
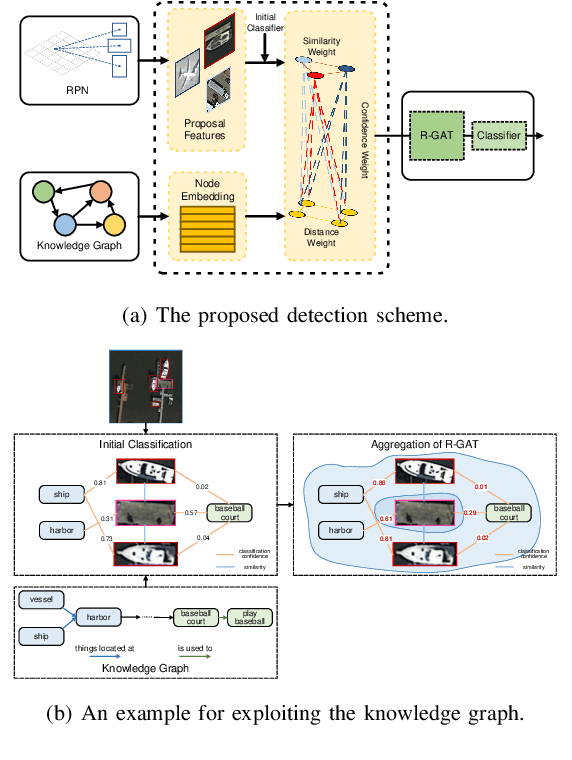
Unmanned aerial vehicles (UAVs) are widely used for object detection. However, the existing UAV-based object detection systems are subject to the serious challenge, namely, the finite computation, energy and communication resources, which limits the achievable detection performance. In order to overcome this challenge, a UAV cognitive semantic communication system is proposed by exploiting knowledge graph. Moreover, a multi-scale compression network is designed for semantic compression to reduce data transmission volume while guaranteeing the detection performance. Furthermore, an object detection scheme is proposed by using the knowledge graph to overcome channel noise interference and compression distortion. Simulation results conducted on the practical aerial image dataset demonstrate that compared to the benchmark systems, our proposed system has superior detection accuracy, communication robustness and computation efficiency even under high compression rates and low signal-to-noise ratio (SNR) conditions.