 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialThinker: Reinforcing 3D Reasoning in Multimodal LLMs via Spatial Rewards
Nov 10, 2025Multimodal large language models (MLLMs) have achieved remarkable progress in vision-language tasks, but they continue to struggle with spatial understanding. Existing spatial MLLMs often rely on explicit 3D inputs or architecture-specific modifications, and remain constrained by large-scale datasets or sparse supervision. To address these limitations, we introduce SpatialThinker, a 3D-aware MLLM trained with RL to integrate structured spatial grounding with multi-step reasoning. The model simulates human-like spatial perception by constructing a scene graph of task-relevant objects and spatial relations, and reasoning towards an answer via dense spatial rewards. SpatialThinker consists of two key contributions: (1) a data synthesis pipeline that generates STVQA-7K, a high-quality spatial VQA dataset, and (2) online RL with a multi-objective dense spatial reward enforcing spatial grounding. SpatialThinker-7B outperforms supervised fine-tuning and the sparse RL baseline on spatial understanding and real-world VQA benchmarks, nearly doubling the base-model gain compared to sparse RL, and surpassing GPT-4o. These results showcase the effectiveness of combining spatial supervision with reward-aligned reasoning in enabling robust 3D spatial understanding with limited data and advancing MLLMs towards human-level visual reasoning.
Olympus: A Universal Task Router for Computer Vision Tasks
Dec 12, 2024We introduce Olympus, a new approach that transforms Multimodal Large Language Models (MLLMs) into a unified framework capable of handling a wide array of computer vision tasks. Utilizing a controller MLLM, Olympus delegates over 20 specialized tasks across images, videos, and 3D objects to dedicated modules. This instruction-based routing enables complex workflows through chained actions without the need for training heavy generative models. Olympus easily integrates with existing MLLMs, expanding their capabilities with comparable performance. Experimental results demonstrate that Olympus achieves an average routing accuracy of 94.75% across 20 tasks and precision of 91.82% in chained action scenarios, showcasing its effectiveness as a universal task router that can solve a diverse range of computer vision tasks. Project page: https://github.com/yuanze-lin/Olympus_page
Rethinking Visual Prompting for Multimodal Large Language Models with External Knowledge
Jul 05, 2024In recent years, multimodal large language models (MLLMs) have made significant strides by training on vast high-quality image-text datasets, enabling them to generally understand images well. However, the inherent difficulty in explicitly conveying fine-grained or spatially dense information in text, such as masks, poses a challenge for MLLMs, limiting their ability to answer questions requiring an understanding of detailed or localized visual elements. Drawing inspiration from the Retrieval-Augmented Generation (RAG) concept, this paper proposes a new visual prompt approach to integrate fine-grained external knowledge, gleaned from specialized vision models (e.g., instance segmentation/OCR models), into MLLMs. This is a promising yet underexplored direction for enhancing MLLMs' performance. Our approach diverges from concurrent works, which transform external knowledge into additional text prompts, necessitating the model to indirectly learn the correspondence between visual content and text coordinates. Instead, we propose embedding fine-grained knowledge information directly into a spatial embedding map as a visual prompt. This design can be effortlessly incorporated into various MLLMs, such as LLaVA and Mipha, considerably improving their visual understanding performance. Through rigorous experiments, we demonstrate that our method can enhance MLLM performance across nine benchmarks, amplifying their fine-grained context-aware capabilities.
DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion
Mar 25, 2024We present DreamPolisher, a novel Gaussian Splatting based method with geometric guidance, tailored to learn cross-view consistency and intricate detail from textual descriptions. While recent progress on text-to-3D generation methods have been promising, prevailing methods often fail to ensure view-consistency and textural richness. This problem becomes particularly noticeable for methods that work with text input alone. To address this, we propose a two-stage Gaussian Splatting based approach that enforces geometric consistency among views. Initially, a coarse 3D generation undergoes refinement via geometric optimization. Subsequently, we use a ControlNet driven refiner coupled with the geometric consistency term to improve both texture fidelity and overall consistency of the generated 3D asset. Empirical evaluations across diverse textual prompts spanning various object categories demonstrate the efficacy of DreamPolisher in generating consistent and realistic 3D objects, aligning closely with the semantics of the textual instructions.
Text-Driven Image Editing via Learnable Regions
Nov 28, 2023Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pretrained text-to-image model and introduces a bounding box generator to find the edit regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences or long paragraphs. We conduct an extensive user study to compare our method against state-of-the-art methods. Experiments demonstrate the competitive performance of our method in manipulating images with high fidelity and realism that align with the language descriptions provided. Our project webpage: https://yuanze-lin.me/LearnableRegions_page.
SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-training
Nov 30, 2022Video-language pre-training is crucial for learning powerful multi-modal representation. However, it typically requires a massive amount of computation. In this paper, we develop SMAUG, an efficient pre-training framework for video-language models. The foundation component in SMAUG is masked autoencoders. Different from prior works which only mask textual inputs, our masking strategy considers both visual and textual modalities, providing a better cross-modal alignment and saving more pre-training costs. On top of that, we introduce a space-time token sparsification module, which leverages context information to further select only "important" spatial regions and temporal frames for pre-training. Coupling all these designs allows our method to enjoy both competitive performances on text-to-video retrieval and video question answering tasks, and much less pre-training costs by 1.9X or more. For example, our SMAUG only needs about 50 NVIDIA A6000 GPU hours for pre-training to attain competitive performances on these two video-language tasks across six popular benchmarks.
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
Jun 02, 2022
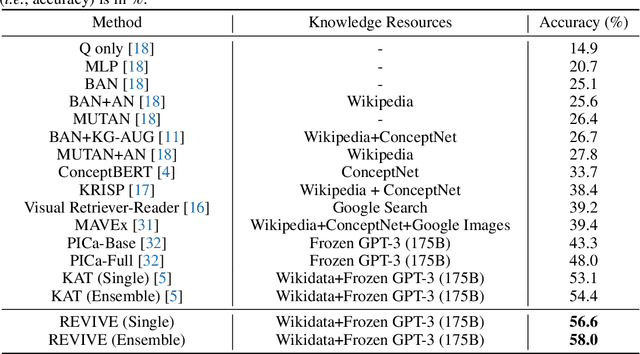
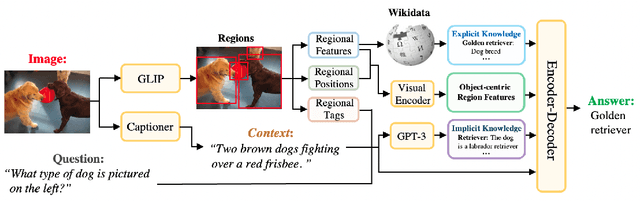

This paper revisits visual representation in knowledge-based visual question answering (VQA) and demonstrates that using regional information in a better way can significantly improve the performance. While visual representation is extensively studied in traditional VQA, it is under-explored in knowledge-based VQA even though these two tasks share the common spirit, i.e., rely on visual input to answer the question. Specifically, we observe that in most state-of-the-art knowledge-based VQA methods: 1) visual features are extracted either from the whole image or in a sliding window manner for retrieving knowledge, and the important relationship within/among object regions is neglected; 2) visual features are not well utilized in the final answering model, which is counter-intuitive to some extent. Based on these observations, we propose a new knowledge-based VQA method REVIVE, which tries to utilize the explicit information of object regions not only in the knowledge retrieval stage but also in the answering model. The key motivation is that object regions and inherent relationships are important for knowledge-based VQA. We perform extensive experiments on the standard OK-VQA dataset and achieve new state-of-the-art performance, i.e., 58.0% accuracy, surpassing previous state-of-the-art method by a large margin (+3.6%). We also conduct detailed analysis and show the necessity of regional information in different framework components for knowledge-based VQA.
Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding
Mar 22, 2022
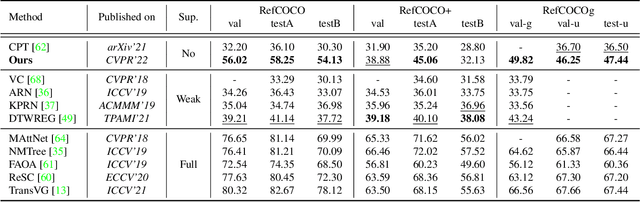
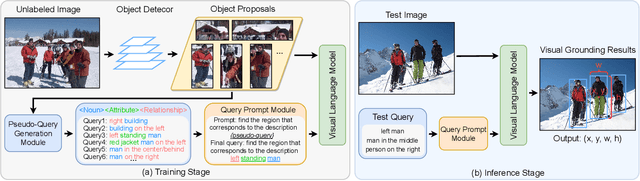
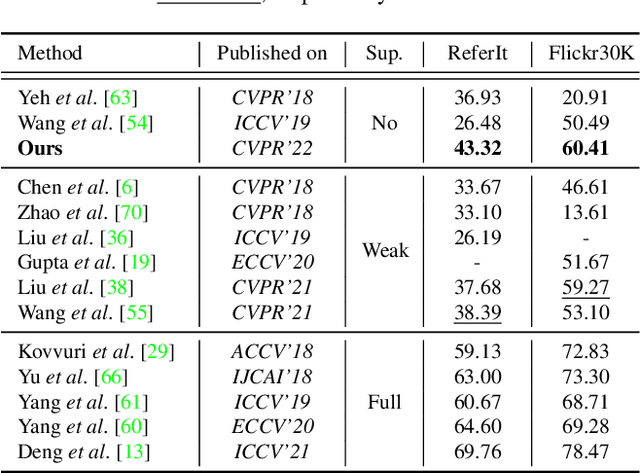
Visual grounding, i.e., localizing objects in images according to natural language queries, is an important topic in visual language understanding. The most effective approaches for this task are based on deep learning, which generally require expensive manually labeled image-query or patch-query pairs. To eliminate the heavy dependence on human annotations, we present a novel method, named Pseudo-Q, to automatically generate pseudo language queries for supervised training. Our method leverages an off-the-shelf object detector to identify visual objects from unlabeled images, and then language queries for these objects are obtained in an unsupervised fashion with a pseudo-query generation module. Then, we design a task-related query prompt module to specifically tailor generated pseudo language queries for visual grounding tasks. Further, in order to fully capture the contextual relationships between images and language queries, we develop a visual-language model equipped with multi-level cross-modality attention mechanism. Extensive experimental results demonstrate that our method has two notable benefits: (1) it can reduce human annotation costs significantly, e.g., 31% on RefCOCO without degrading original model's performance under the fully supervised setting, and (2) without bells and whistles, it achieves superior or comparable performance compared to state-of-the-art weakly-supervised visual grounding methods on all the five datasets we have experimented. Code is available at https://github.com/LeapLabTHU/Pseudo-Q.
AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
Dec 28, 2021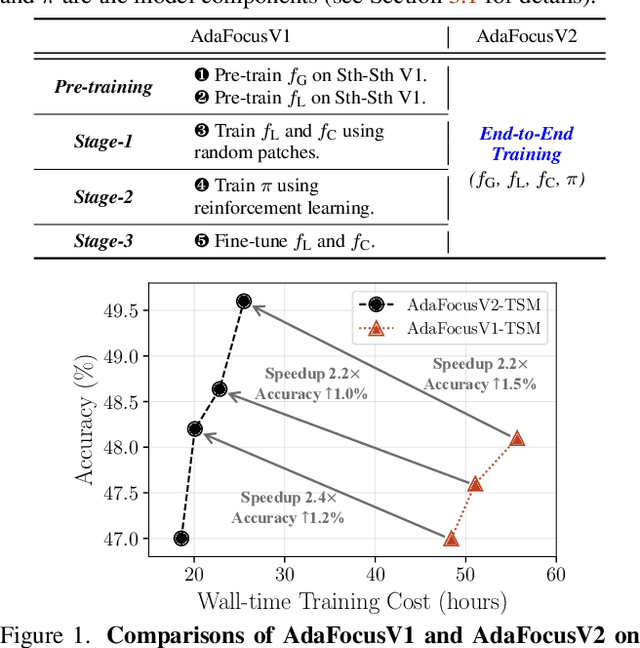
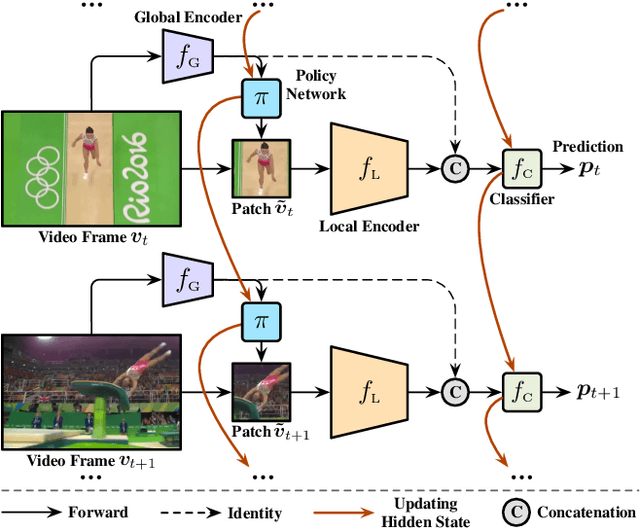

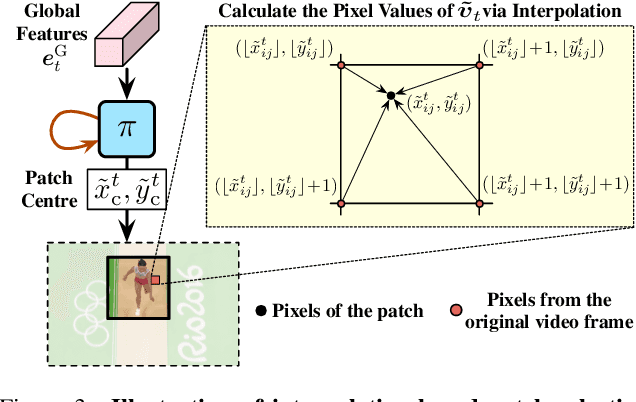
Recent works have shown that the computational efficiency of video recognition can be significantly improved by reducing the spatial redundancy. As a representative work, the adaptive focus method (AdaFocus) has achieved a favorable trade-off between accuracy and inference speed by dynamically identifying and attending to the informative regions in each video frame. However, AdaFocus requires a complicated three-stage training pipeline (involving reinforcement learning), leading to slow convergence and is unfriendly to practitioners. This work reformulates the training of AdaFocus as a simple one-stage algorithm by introducing a differentiable interpolation-based patch selection operation, enabling efficient end-to-end optimization. We further present an improved training scheme to address the issues introduced by the one-stage formulation, including the lack of supervision, input diversity and training stability. Moreover, a conditional-exit technique is proposed to perform temporal adaptive computation on top of AdaFocus without additional training. Extensive experiments on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2, and Jester) demonstrate that our model significantly outperforms the original AdaFocus and other competitive baselines, while being considerably more simple and efficient to train. Code is available at https://github.com/LeapLabTHU/AdaFocusV2.
Self-Supervised Video Representation Learning with Meta-Contrastive Network
Aug 23, 2021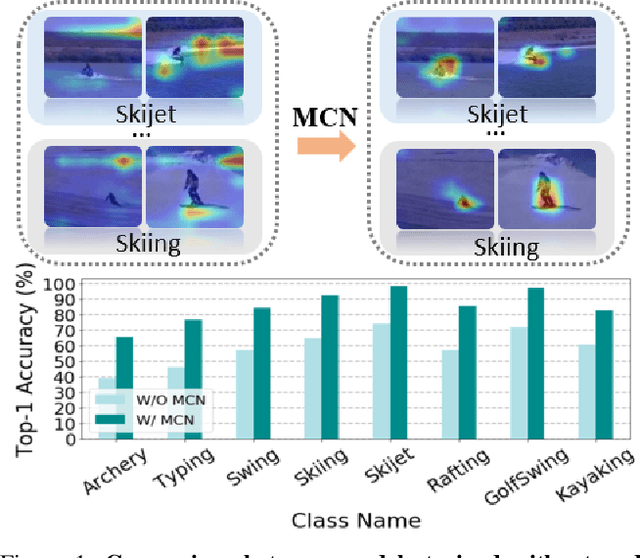
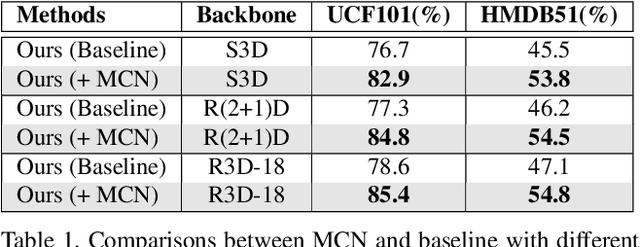
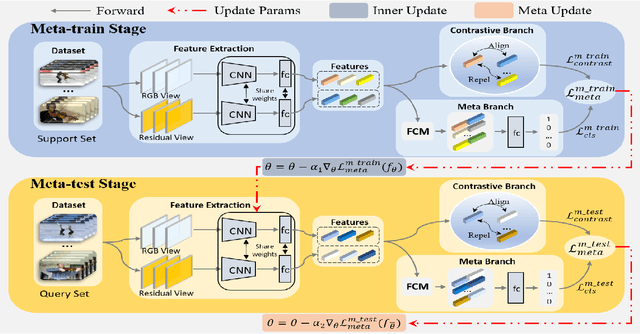
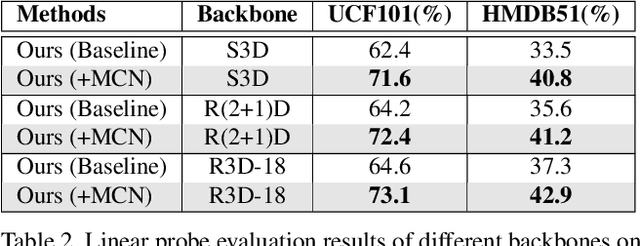
Self-supervised learning has been successfully applied to pre-train video representations, which aims at efficient adaptation from pre-training domain to downstream tasks. Existing approaches merely leverage contrastive loss to learn instance-level discrimination. However, lack of category information will lead to hard-positive problem that constrains the generalization ability of this kind of methods. We find that the multi-task process of meta learning can provide a solution to this problem. In this paper, we propose a Meta-Contrastive Network (MCN), which combines the contrastive learning and meta learning, to enhance the learning ability of existing self-supervised approaches. Our method contains two training stages based on model-agnostic meta learning (MAML), each of which consists of a contrastive branch and a meta branch. Extensive evaluations demonstrate the effectiveness of our method. For two downstream tasks, i.e., video action recognition and video retrieval, MCN outperforms state-of-the-art approaches on UCF101 and HMDB51 datasets. To be more specific, with R(2+1)D backbone, MCN achieves Top-1 accuracies of 84.8% and 54.5% for video action recognition, as well as 52.5% and 23.7% for video retrieval.