 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTX-2: Efficient Joint Audio-Visual Foundation Model
Jan 06, 2026Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.
LTX-Video: Realtime Video Latent Diffusion
Dec 30, 2024



We introduce LTX-Video, a transformer-based latent diffusion model that adopts a holistic approach to video generation by seamlessly integrating the responsibilities of the Video-VAE and the denoising transformer. Unlike existing methods, which treat these components as independent, LTX-Video aims to optimize their interaction for improved efficiency and quality. At its core is a carefully designed Video-VAE that achieves a high compression ratio of 1:192, with spatiotemporal downscaling of 32 x 32 x 8 pixels per token, enabled by relocating the patchifying operation from the transformer's input to the VAE's input. Operating in this highly compressed latent space enables the transformer to efficiently perform full spatiotemporal self-attention, which is essential for generating high-resolution videos with temporal consistency. However, the high compression inherently limits the representation of fine details. To address this, our VAE decoder is tasked with both latent-to-pixel conversion and the final denoising step, producing the clean result directly in pixel space. This approach preserves the ability to generate fine details without incurring the runtime cost of a separate upsampling module. Our model supports diverse use cases, including text-to-video and image-to-video generation, with both capabilities trained simultaneously. It achieves faster-than-real-time generation, producing 5 seconds of 24 fps video at 768x512 resolution in just 2 seconds on an Nvidia H100 GPU, outperforming all existing models of similar scale. The source code and pre-trained models are publicly available, setting a new benchmark for accessible and scalable video generation.
AdaFocusV3: On Unified Spatial-temporal Dynamic Video Recognition
Sep 27, 2022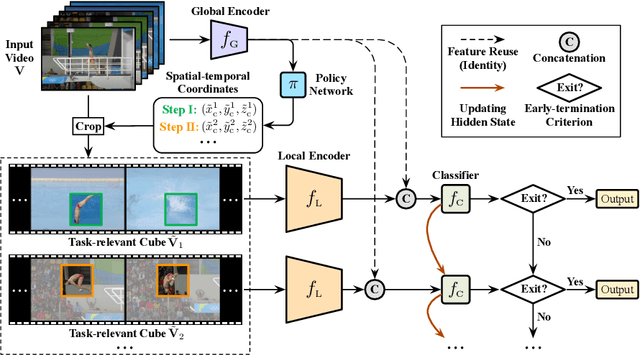
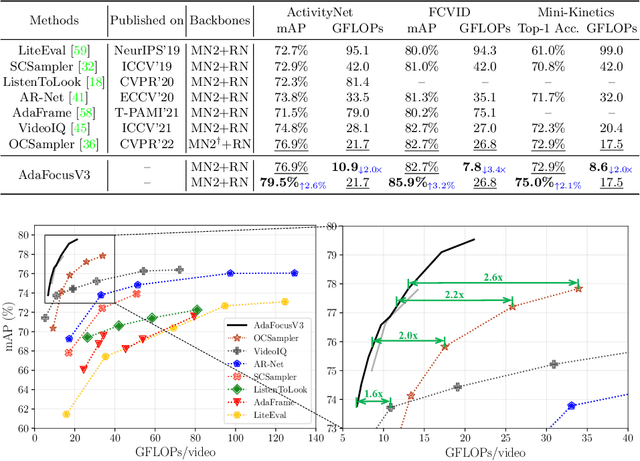
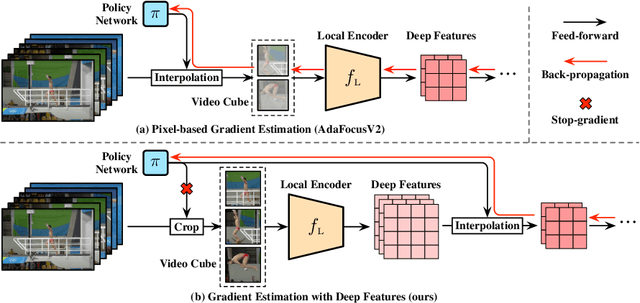
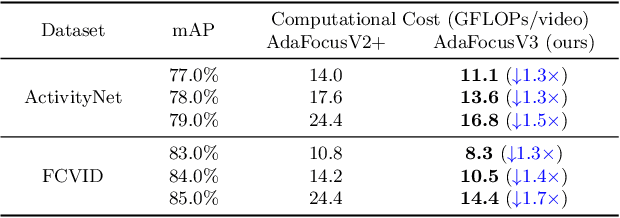
Recent research has revealed that reducing the temporal and spatial redundancy are both effective approaches towards efficient video recognition, e.g., allocating the majority of computation to a task-relevant subset of frames or the most valuable image regions of each frame. However, in most existing works, either type of redundancy is typically modeled with another absent. This paper explores the unified formulation of spatial-temporal dynamic computation on top of the recently proposed AdaFocusV2 algorithm, contributing to an improved AdaFocusV3 framework. Our method reduces the computational cost by activating the expensive high-capacity network only on some small but informative 3D video cubes. These cubes are cropped from the space formed by frame height, width, and video duration, while their locations are adaptively determined with a light-weighted policy network on a per-sample basis. At test time, the number of the cubes corresponding to each video is dynamically configured, i.e., video cubes are processed sequentially until a sufficiently reliable prediction is produced. Notably, AdaFocusV3 can be effectively trained by approximating the non-differentiable cropping operation with the interpolation of deep features. Extensive empirical results on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2 and Diving48) demonstrate that our model is considerably more efficient than competitive baselines.
AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
Dec 28, 2021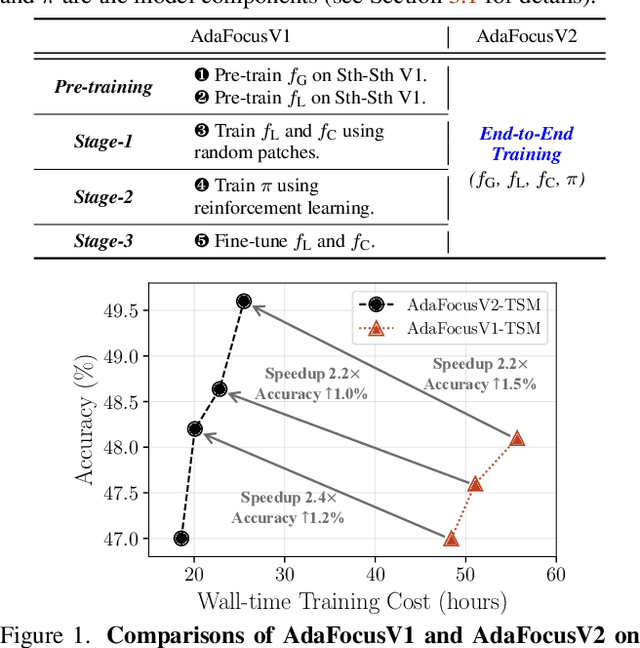
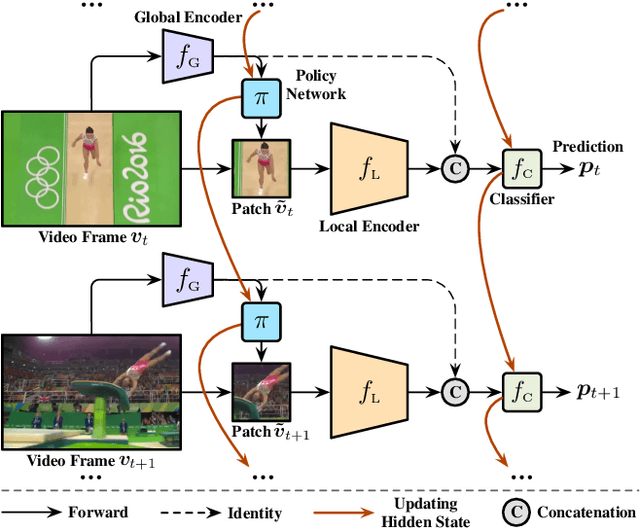

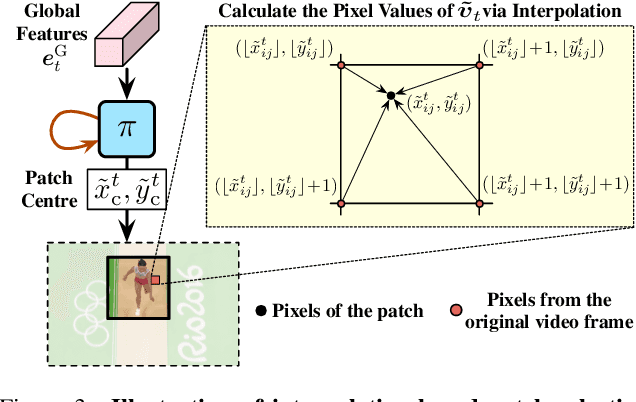
Recent works have shown that the computational efficiency of video recognition can be significantly improved by reducing the spatial redundancy. As a representative work, the adaptive focus method (AdaFocus) has achieved a favorable trade-off between accuracy and inference speed by dynamically identifying and attending to the informative regions in each video frame. However, AdaFocus requires a complicated three-stage training pipeline (involving reinforcement learning), leading to slow convergence and is unfriendly to practitioners. This work reformulates the training of AdaFocus as a simple one-stage algorithm by introducing a differentiable interpolation-based patch selection operation, enabling efficient end-to-end optimization. We further present an improved training scheme to address the issues introduced by the one-stage formulation, including the lack of supervision, input diversity and training stability. Moreover, a conditional-exit technique is proposed to perform temporal adaptive computation on top of AdaFocus without additional training. Extensive experiments on six benchmark datasets (i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2, and Jester) demonstrate that our model significantly outperforms the original AdaFocus and other competitive baselines, while being considerably more simple and efficient to train. Code is available at https://github.com/LeapLabTHU/AdaFocusV2.
Instance Segmentation of Biological Images Using Harmonic Embeddings
Apr 10, 2019
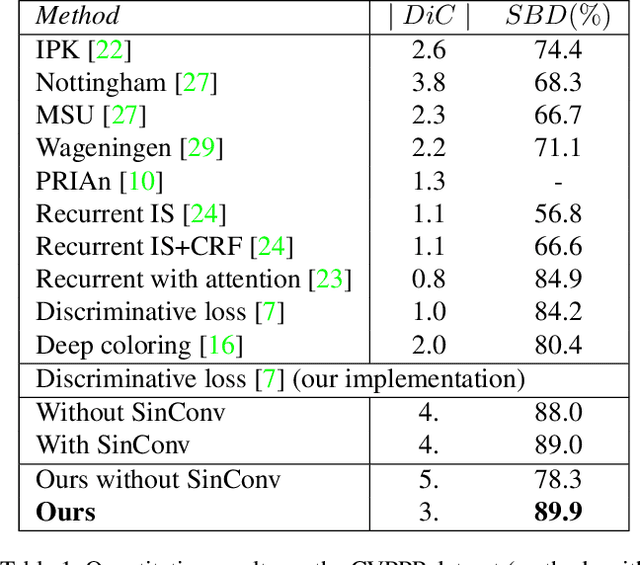


We present a new instance segmentation approach tailored to biological images, where instances may correspond to individual cells, organisms or plant parts. Unlike instance segmentation for user photographs or road scenes, in biological data object instances may be particularly densely packed, the appearance variation may be particularly low, the processing power may be restricted, while, on the other hand, the variability of sizes of individual instances may be limited. These peculiarities are successfully addressed and exploited by the proposed approach. Our approach describes each object instance using an expectation of a limited number of sine waves with frequencies and phases adjusted to particular object sizes and densities. At train time, a fully-convolutional network is learned to predict the object embeddings at each pixel using a simple pixelwise regression loss, while at test time the instances are recovered using clustering in the embeddings space. In the experiments, we show that our approach outperforms previous embedding-based instance segmentation approaches on a number of biological datasets, achieving state-of-the-art on a popular CVPPP benchmark. Notably, this excellent performance is combined with computational efficiency that is needed for deployment to domain specialists. The source code is publicly available at Github: https://github.com/kulikovv/harmonic
Instance Segmentation by Deep Coloring
Jul 26, 2018



We propose a new and, arguably, a very simple reduction of instance segmentation to semantic segmentation. This reduction allows to train feed-forward non-recurrent deep instance segmentation systems in an end-to-end fashion using architectures that have been proposed for semantic segmentation. Our approach proceeds by introducing a fixed number of labels (colors) and then dynamically assigning object instances to those labels during training (coloring). A standard semantic segmentation objective is then used to train a network that can color previously unseen images. At test time, individual object instances can be recovered from the output of the trained convolutional network using simple connected component analysis. In the experimental validation, the coloring approach is shown to be capable of solving diverse instance segmentation tasks arising in autonomous driving (the Cityscapes benchmark), plant phenotyping (the CVPPP leaf segmentation challenge), and high-throughput microscopy image analysis. The source code is publicly available: https://github.com/kulikovv/DeepColoring.