 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Segmentation by Deep Coloring
Jul 26, 2018



We propose a new and, arguably, a very simple reduction of instance segmentation to semantic segmentation. This reduction allows to train feed-forward non-recurrent deep instance segmentation systems in an end-to-end fashion using architectures that have been proposed for semantic segmentation. Our approach proceeds by introducing a fixed number of labels (colors) and then dynamically assigning object instances to those labels during training (coloring). A standard semantic segmentation objective is then used to train a network that can color previously unseen images. At test time, individual object instances can be recovered from the output of the trained convolutional network using simple connected component analysis. In the experimental validation, the coloring approach is shown to be capable of solving diverse instance segmentation tasks arising in autonomous driving (the Cityscapes benchmark), plant phenotyping (the CVPPP leaf segmentation challenge), and high-throughput microscopy image analysis. The source code is publicly available: https://github.com/kulikovv/DeepColoring.
Parsing Images of Overlapping Organisms with Deep Singling-Out Networks
Dec 19, 2016
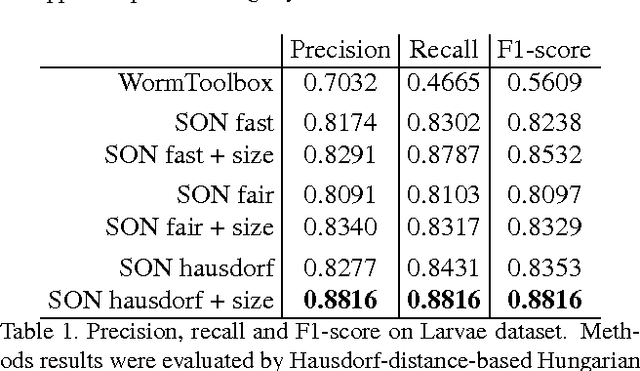


This work is motivated by the mostly unsolved task of parsing biological images with multiple overlapping articulated model organisms (such as worms or larvae). We present a general approach that separates the two main challenges associated with such data, individual object shape estimation and object groups disentangling. At the core of the approach is a deep feed-forward singling-out network (SON) that is trained to map each local patch to a vectorial descriptor that is sensitive to the characteristics (e.g. shape) of a central object, while being invariant to the variability of all other surrounding elements. Given a SON, a local image patch can be matched to a gallery of isolated elements using their SON-descriptors, thus producing a hypothesis about the shape of the central element in that patch. The image-level optimization based on integer programming can then pick a subset of the hypotheses to explain (parse) the whole image and disentangle groups of organisms. While sharing many similarities with existing "analysis-by-synthesis" approaches, our method avoids the need for stochastic search in the high-dimensional configuration space and numerous rendering operations at test-time. We show that our approach can parse microscopy images of three popular model organisms (the C.Elegans roundworms, the Drosophila larvae, and the E.Coli bacteria) even under significant crowding and overlaps between organisms. We speculate that the overall approach is applicable to a wider class of image parsing problems concerned with crowded articulated objects, for which rendering training images is possible.