 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTX-2: Efficient Joint Audio-Visual Foundation Model
Jan 06, 2026Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.
LTX-Video: Realtime Video Latent Diffusion
Dec 30, 2024



We introduce LTX-Video, a transformer-based latent diffusion model that adopts a holistic approach to video generation by seamlessly integrating the responsibilities of the Video-VAE and the denoising transformer. Unlike existing methods, which treat these components as independent, LTX-Video aims to optimize their interaction for improved efficiency and quality. At its core is a carefully designed Video-VAE that achieves a high compression ratio of 1:192, with spatiotemporal downscaling of 32 x 32 x 8 pixels per token, enabled by relocating the patchifying operation from the transformer's input to the VAE's input. Operating in this highly compressed latent space enables the transformer to efficiently perform full spatiotemporal self-attention, which is essential for generating high-resolution videos with temporal consistency. However, the high compression inherently limits the representation of fine details. To address this, our VAE decoder is tasked with both latent-to-pixel conversion and the final denoising step, producing the clean result directly in pixel space. This approach preserves the ability to generate fine details without incurring the runtime cost of a separate upsampling module. Our model supports diverse use cases, including text-to-video and image-to-video generation, with both capabilities trained simultaneously. It achieves faster-than-real-time generation, producing 5 seconds of 24 fps video at 768x512 resolution in just 2 seconds on an Nvidia H100 GPU, outperforming all existing models of similar scale. The source code and pre-trained models are publicly available, setting a new benchmark for accessible and scalable video generation.
Diffusing Colors: Image Colorization with Text Guided Diffusion
Dec 07, 2023



The colorization of grayscale images is a complex and subjective task with significant challenges. Despite recent progress in employing large-scale datasets with deep neural networks, difficulties with controllability and visual quality persist. To tackle these issues, we present a novel image colorization framework that utilizes image diffusion techniques with granular text prompts. This integration not only produces colorization outputs that are semantically appropriate but also greatly improves the level of control users have over the colorization process. Our method provides a balance between automation and control, outperforming existing techniques in terms of visual quality and semantic coherence. We leverage a pretrained generative Diffusion Model, and show that we can finetune it for the colorization task without losing its generative power or attention to text prompts. Moreover, we present a novel CLIP-based ranking model that evaluates color vividness, enabling automatic selection of the most suitable level of vividness based on the specific scene semantics. Our approach holds potential particularly for color enhancement and historical image colorization.
Semantic Segmentation In-the-Wild Without Seeing Any Segmentation Examples
Dec 06, 2021Semantic segmentation is a key computer vision task that has been actively researched for decades. In recent years, supervised methods have reached unprecedented accuracy, however they require many pixel-level annotations for every new class category which is very time-consuming and expensive. Additionally, the ability of current semantic segmentation networks to handle a large number of categories is limited. That means that images containing rare class categories are unlikely to be well segmented by current methods. In this paper we propose a novel approach for creating semantic segmentation masks for every object, without the need for training segmentation networks or seeing any segmentation masks. Our method takes as input the image-level labels of the class categories present in the image; they can be obtained automatically or manually. We utilize a vision-language embedding model (specifically CLIP) to create a rough segmentation map for each class, using model interpretability methods. We refine the maps using a test-time augmentation technique. The output of this stage provides pixel-level pseudo-labels, instead of the manual pixel-level labels required by supervised methods. Given the pseudo-labels, we utilize single-image segmentation techniques to obtain high-quality output segmentation masks. Our method is shown quantitatively and qualitatively to outperform methods that use a similar amount of supervision. Our results are particularly remarkable for images containing rare categories.
Image Shape Manipulation from a Single Augmented Training Sample
Sep 13, 2021
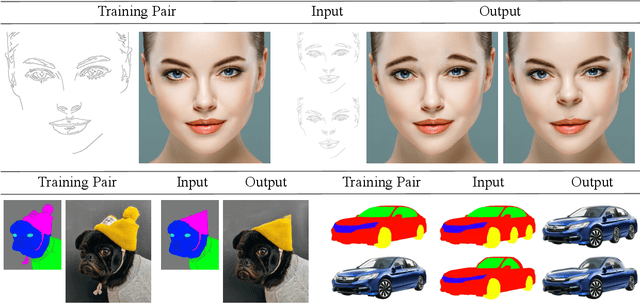


In this paper, we present DeepSIM, a generative model for conditional image manipulation based on a single image. We find that extensive augmentation is key for enabling single image training, and incorporate the use of thin-plate-spline (TPS) as an effective augmentation. Our network learns to map between a primitive representation of the image to the image itself. The choice of a primitive representation has an impact on the ease and expressiveness of the manipulations and can be automatic (e.g. edges), manual (e.g. segmentation) or hybrid such as edges on top of segmentations. At manipulation time, our generator allows for making complex image changes by modifying the primitive input representation and mapping it through the network. Our method is shown to achieve remarkable performance on image manipulation tasks.
Deep Single Image Manipulation
Jul 02, 2020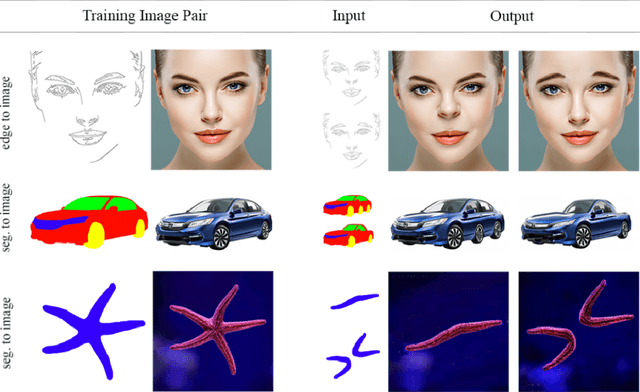



Image manipulation has attracted much research over the years due to the popularity and commercial importance of the task. In recent years, deep neural network methods have been proposed for many image manipulation tasks. A major issue with deep methods is the need to train on large amounts of data from the same distribution as the target image, whereas collecting datasets encompassing the entire long-tail of images is impossible. In this paper, we demonstrate that simply training a conditional adversarial generator on the single target image is sufficient for performing complex image manipulations. We find that the key for enabling single image training is extensive augmentation of the input image and provide a novel augmentation method. Our network learns to map between a primitive representation of the image (e.g. edges) to the image itself. At manipulation time, our generator allows for making general image changes by modifying the primitive input representation and mapping it through the network. We extensively evaluate our method and find that it provides remarkable performance.
Training End-to-end Single Image Generators without GANs
Apr 07, 2020



We present AugurOne, a novel approach for training single image generative models. Our approach trains an upscaling neural network using non-affine augmentations of the (single) input image, particularly including non-rigid thin plate spline image warps. The extensive augmentations significantly increase the in-sample distribution for the upsampling network enabling the upscaling of highly variable inputs. A compact latent space is jointly learned allowing for controlled image synthesis. Differently from Single Image GAN, our approach does not require GAN training and takes place in an end-to-end fashion allowing fast and stable training. We experimentally evaluate our method and show that it obtains compelling novel animations of single-image, as well as, state-of-the-art performance on conditional generation tasks e.g. paint-to-image and edges-to-image.