 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Hidden Gems in Model Repositories
Jan 29, 2026Public repositories host millions of fine-tuned models, yet community usage remains disproportionately concentrated on a small number of foundation checkpoints. We investigate whether this concentration reflects efficient market selection or if superior models are systematically overlooked. Through an extensive evaluation of over 2,000 models, we show the prevalence of "hidden gems", unpopular fine-tunes that significantly outperform their popular counterparts. Notably, within the Llama-3.1-8B family, we find rarely downloaded checkpoints that improve math performance from 83.2% to 96.0% without increasing inference costs. However, discovering these models through exhaustive evaluation of every uploaded model is computationally infeasible. We therefore formulate model discovery as a Multi-Armed Bandit problem and accelerate the Sequential Halving search algorithm by using shared query sets and aggressive elimination schedules. Our method retrieves top models with as few as 50 queries per candidate, accelerating discovery by over 50x.
Charting and Navigating Hugging Face's Model Atlas
Mar 13, 2025



As there are now millions of publicly available neural networks, searching and analyzing large model repositories becomes increasingly important. Navigating so many models requires an atlas, but as most models are poorly documented charting such an atlas is challenging. To explore the hidden potential of model repositories, we chart a preliminary atlas representing the documented fraction of Hugging Face. It provides stunning visualizations of the model landscape and evolution. We demonstrate several applications of this atlas including predicting model attributes (e.g., accuracy), and analyzing trends in computer vision models. However, as the current atlas remains incomplete, we propose a method for charting undocumented regions. Specifically, we identify high-confidence structural priors based on dominant real-world model training practices. Leveraging these priors, our approach enables accurate mapping of previously undocumented areas of the atlas. We publicly release our datasets, code, and interactive atlas.
Can this Model Also Recognize Dogs? Zero-Shot Model Search from Weights
Feb 13, 2025



With the increasing numbers of publicly available models, there are probably pretrained, online models for most tasks users require. However, current model search methods are rudimentary, essentially a text-based search in the documentation, thus users cannot find the relevant models. This paper presents ProbeLog, a method for retrieving classification models that can recognize a target concept, such as "Dog", without access to model metadata or training data. Differently from previous probing methods, ProbeLog computes a descriptor for each output dimension (logit) of each model, by observing its responses on a fixed set of inputs (probes). Our method supports both logit-based retrieval ("find more logits like this") and zero-shot, text-based retrieval ("find all logits corresponding to dogs"). As probing-based representations require multiple costly feedforward passes through the model, we develop a method, based on collaborative filtering, that reduces the cost of encoding repositories by 3x. We demonstrate that ProbeLog achieves high retrieval accuracy, both in real-world and fine-grained search tasks and is scalable to full-size repositories.
Representing Model Weights with Language using Tree Experts
Oct 17, 2024



The increasing availability of public models begs the question: can we train neural networks that use other networks as input? This paper learns to represent models within a joint space that embeds both model weights and language. However, machine learning on model weights is challenging as model weights often exhibit significant variation unrelated to the models' semantic properties (nuisance variation). We identify a key property of real-world models: most public models belong to a small set of Model Trees, where all models within a tree are fine-tuned from a common ancestor (e.g., a foundation model). Importantly, we find that within each tree there is less nuisance variation between models. For example, while classifying models according to their training dataset generally requires complex architectures, in our case, even a linear classifier trained on a single layer is often effective. While effective, linear layers are computationally expensive as model weights are very high dimensional. To address this, we introduce Probing Experts (ProbeX), a theoretically motivated, lightweight probing method. Notably, ProbeX is the first probing method designed to learn from the weights of just a single model layer. We also construct and release a dataset that simulates the structure of public model repositories. Our results show that ProbeX can effectively map the weights of large models into a shared weight-language embedding space. Furthermore, we demonstrate the impressive generalization of our method, achieving zero-shot model classification and retrieval.
Deep Linear Probe Generators for Weight Space Learning
Oct 14, 2024



Weight space learning aims to extract information about a neural network, such as its training dataset or generalization error. Recent approaches learn directly from model weights, but this presents many challenges as weights are high-dimensional and include permutation symmetries between neurons. An alternative approach, Probing, represents a model by passing a set of learned inputs (probes) through the model, and training a predictor on top of the corresponding outputs. Although probing is typically not used as a stand alone approach, our preliminary experiment found that a vanilla probing baseline worked surprisingly well. However, we discover that current probe learning strategies are ineffective. We therefore propose Deep Linear Probe Generators (ProbeGen), a simple and effective modification to probing approaches. ProbeGen adds a shared generator module with a deep linear architecture, providing an inductive bias towards structured probes thus reducing overfitting. While simple, ProbeGen performs significantly better than the state-of-the-art and is very efficient, requiring between 30 to 1000 times fewer FLOPs than other top approaches.
Dataset Size Recovery from LoRA Weights
Jun 27, 2024Model inversion and membership inference attacks aim to reconstruct and verify the data which a model was trained on. However, they are not guaranteed to find all training samples as they do not know the size of the training set. In this paper, we introduce a new task: dataset size recovery, that aims to determine the number of samples used to train a model, directly from its weights. We then propose DSiRe, a method for recovering the number of images used to fine-tune a model, in the common case where fine-tuning uses LoRA. We discover that both the norm and the spectrum of the LoRA matrices are closely linked to the fine-tuning dataset size; we leverage this finding to propose a simple yet effective prediction algorithm. To evaluate dataset size recovery of LoRA weights, we develop and release a new benchmark, LoRA-WiSE, consisting of over 25000 weight snapshots from more than 2000 diverse LoRA fine-tuned models. Our best classifier can predict the number of fine-tuning images with a mean absolute error of 0.36 images, establishing the feasibility of this attack.
Real-Time Deepfake Detection in the Real-World
Jun 13, 2024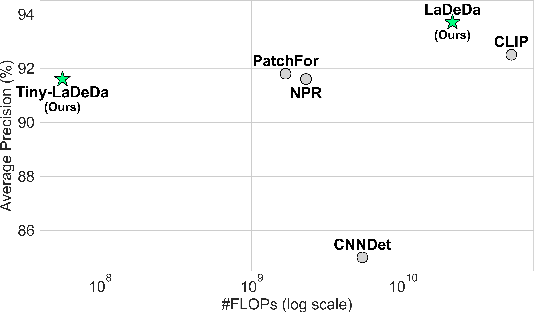
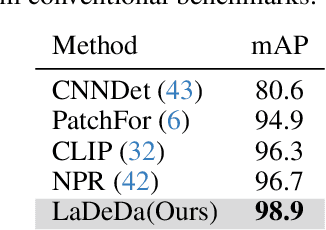
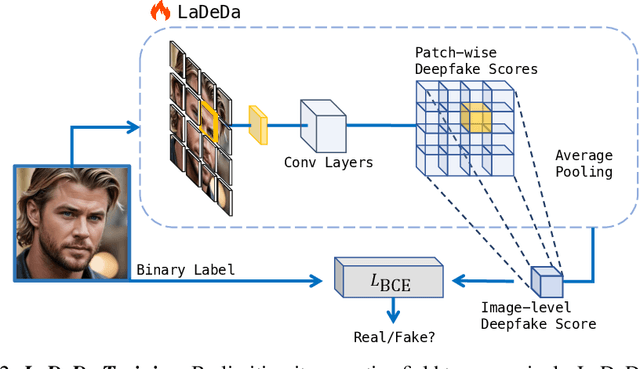
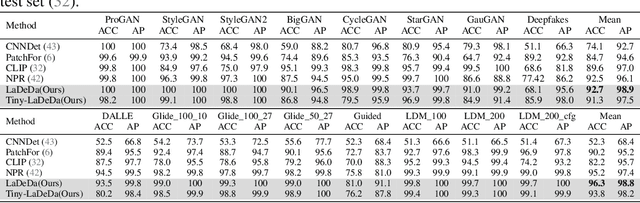
Recent improvements in generative AI made synthesizing fake images easy; as they can be used to cause harm, it is crucial to develop accurate techniques to identify them. This paper introduces "Locally Aware Deepfake Detection Algorithm" (LaDeDa), that accepts a single 9x9 image patch and outputs its deepfake score. The image deepfake score is the pooled score of its patches. With merely patch-level information, LaDeDa significantly improves over the state-of-the-art, achieving around 99% mAP on current benchmarks. Owing to the patch-level structure of LaDeDa, we hypothesize that the generation artifacts can be detected by a simple model. We therefore distill LaDeDa into Tiny-LaDeDa, a highly efficient model consisting of only 4 convolutional layers. Remarkably, Tiny-LaDeDa has 375x fewer FLOPs and is 10,000x more parameter-efficient than LaDeDa, allowing it to run efficiently on edge devices with a minor decrease in accuracy. These almost-perfect scores raise the question: is the task of deepfake detection close to being solved? Perhaps surprisingly, our investigation reveals that current training protocols prevent methods from generalizing to real-world deepfakes extracted from social media. To address this issue, we introduce WildRF, a new deepfake detection dataset curated from several popular social networks. Our method achieves the top performance of 93.7% mAP on WildRF, however the large gap from perfect accuracy shows that reliable real-world deepfake detection is still unsolved.
On the Origin of Llamas: Model Tree Heritage Recovery
May 28, 2024



The rapid growth of neural network models shared on the internet has made model weights an important data modality. However, this information is underutilized as the weights are uninterpretable, and publicly available models are disorganized. Inspired by Darwin's tree of life, we define the Model Tree which describes the origin of models i.e., the parent model that was used to fine-tune the target model. Similarly to the natural world, the tree structure is unknown. In this paper, we introduce the task of Model Tree Heritage Recovery (MoTHer Recovery) for discovering Model Trees in the ever-growing universe of neural networks. Our hypothesis is that model weights encode this information, the challenge is to decode the underlying tree structure given the weights. Beyond the immediate application of model authorship attribution, MoTHer recovery holds exciting long-term applications akin to indexing the internet by search engines. Practically, for each pair of models, this task requires: i) determining if they are related, and ii) establishing the direction of the relationship. We find that certain distributional properties of the weights evolve monotonically during training, which enables us to classify the relationship between two given models. MoTHer recovery reconstructs entire model hierarchies, represented by a directed tree, where a parent model gives rise to multiple child models through additional training. Our approach successfully reconstructs complex Model Trees, as well as the structure of "in-the-wild" model families such as Llama 2 and Stable Diffusion.
Distilling Datasets Into Less Than One Image
Mar 18, 2024



Dataset distillation aims to compress a dataset into a much smaller one so that a model trained on the distilled dataset achieves high accuracy. Current methods frame this as maximizing the distilled classification accuracy for a budget of K distilled images-per-class, where K is a positive integer. In this paper, we push the boundaries of dataset distillation, compressing the dataset into less than an image-per-class. It is important to realize that the meaningful quantity is not the number of distilled images-per-class but the number of distilled pixels-per-dataset. We therefore, propose Poster Dataset Distillation (PoDD), a new approach that distills the entire original dataset into a single poster. The poster approach motivates new technical solutions for creating training images and learnable labels. Our method can achieve comparable or better performance with less than an image-per-class compared to existing methods that use one image-per-class. Specifically, our method establishes a new state-of-the-art performance on CIFAR-10, CIFAR-100, and CUB200 using as little as 0.3 images-per-class.
Recovering the Pre-Fine-Tuning Weights of Generative Models
Feb 15, 2024



The dominant paradigm in generative modeling consists of two steps: i) pre-training on a large-scale but unsafe dataset, ii) aligning the pre-trained model with human values via fine-tuning. This practice is considered safe, as no current method can recover the unsafe, pre-fine-tuning model weights. In this paper, we demonstrate that this assumption is often false. Concretely, we present Spectral DeTuning, a method that can recover the weights of the pre-fine-tuning model using a few low-rank (LoRA) fine-tuned models. In contrast to previous attacks that attempt to recover pre-fine-tuning capabilities, our method aims to recover the exact pre-fine-tuning weights. Our approach exploits this new vulnerability against large-scale models such as a personalized Stable Diffusion and an aligned Mistral.