 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Conditional Prior Distribution for Flow-Based Generative Models
Feb 13, 2025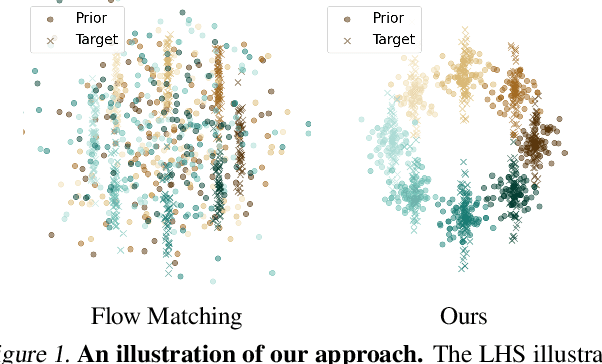

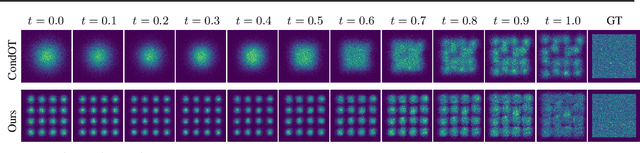
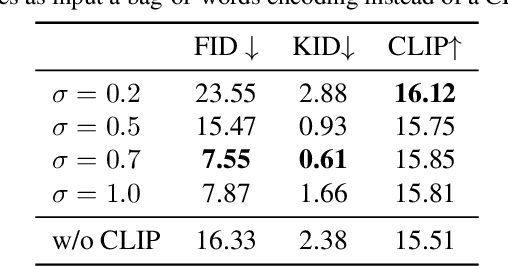
Flow-based generative models have recently shown impressive performance for conditional generation tasks, such as text-to-image generation. However, current methods transform a general unimodal noise distribution to a specific mode of the target data distribution. As such, every point in the initial source distribution can be mapped to every point in the target distribution, resulting in long average paths. To this end, in this work, we tap into a non-utilized property of conditional flow-based models: the ability to design a non-trivial prior distribution. Given an input condition, such as a text prompt, we first map it to a point lying in data space, representing an ``average" data point with the minimal average distance to all data points of the same conditional mode (e.g., class). We then utilize the flow matching formulation to map samples from a parametric distribution centered around this point to the conditional target distribution. Experimentally, our method significantly improves training times and generation efficiency (FID, KID and CLIP alignment scores) compared to baselines, producing high quality samples using fewer sampling steps.
Dataset Size Recovery from LoRA Weights
Jun 27, 2024Model inversion and membership inference attacks aim to reconstruct and verify the data which a model was trained on. However, they are not guaranteed to find all training samples as they do not know the size of the training set. In this paper, we introduce a new task: dataset size recovery, that aims to determine the number of samples used to train a model, directly from its weights. We then propose DSiRe, a method for recovering the number of images used to fine-tune a model, in the common case where fine-tuning uses LoRA. We discover that both the norm and the spectrum of the LoRA matrices are closely linked to the fine-tuning dataset size; we leverage this finding to propose a simple yet effective prediction algorithm. To evaluate dataset size recovery of LoRA weights, we develop and release a new benchmark, LoRA-WiSE, consisting of over 25000 weight snapshots from more than 2000 diverse LoRA fine-tuned models. Our best classifier can predict the number of fine-tuning images with a mean absolute error of 0.36 images, establishing the feasibility of this attack.