 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
Oct 23, 2025Diffusion Transformer models can generate images with remarkable fidelity and detail, yet training them at ultra-high resolutions remains extremely costly due to the self-attention mechanism's quadratic scaling with the number of image tokens. In this paper, we introduce Dynamic Position Extrapolation (DyPE), a novel, training-free method that enables pre-trained diffusion transformers to synthesize images at resolutions far beyond their training data, with no additional sampling cost. DyPE takes advantage of the spectral progression inherent to the diffusion process, where low-frequency structures converge early, while high-frequencies take more steps to resolve. Specifically, DyPE dynamically adjusts the model's positional encoding at each diffusion step, matching their frequency spectrum with the current stage of the generative process. This approach allows us to generate images at resolutions that exceed the training resolution dramatically, e.g., 16 million pixels using FLUX. On multiple benchmarks, DyPE consistently improves performance and achieves state-of-the-art fidelity in ultra-high-resolution image generation, with gains becoming even more pronounced at higher resolutions. Project page is available at https://noamissachar.github.io/DyPE/.
Designing a Conditional Prior Distribution for Flow-Based Generative Models
Feb 13, 2025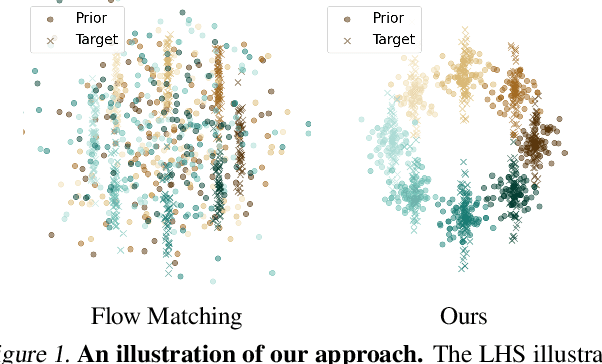

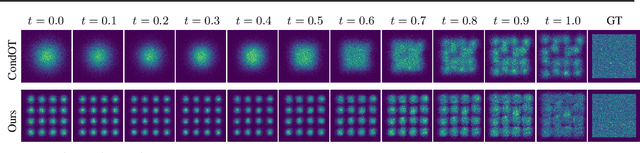
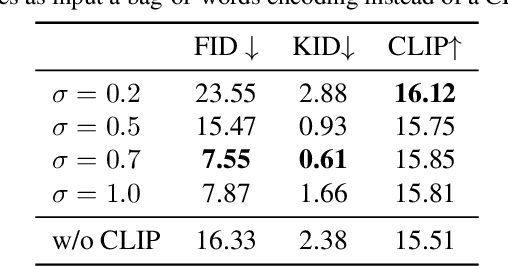
Flow-based generative models have recently shown impressive performance for conditional generation tasks, such as text-to-image generation. However, current methods transform a general unimodal noise distribution to a specific mode of the target data distribution. As such, every point in the initial source distribution can be mapped to every point in the target distribution, resulting in long average paths. To this end, in this work, we tap into a non-utilized property of conditional flow-based models: the ability to design a non-trivial prior distribution. Given an input condition, such as a text prompt, we first map it to a point lying in data space, representing an ``average" data point with the minimal average distance to all data points of the same conditional mode (e.g., class). We then utilize the flow matching formulation to map samples from a parametric distribution centered around this point to the conditional target distribution. Experimentally, our method significantly improves training times and generation efficiency (FID, KID and CLIP alignment scores) compared to baselines, producing high quality samples using fewer sampling steps.
DGD: Dynamic 3D Gaussians Distillation
May 29, 2024



We tackle the task of learning dynamic 3D semantic radiance fields given a single monocular video as input. Our learned semantic radiance field captures per-point semantics as well as color and geometric properties for a dynamic 3D scene, enabling the generation of novel views and their corresponding semantics. This enables the segmentation and tracking of a diverse set of 3D semantic entities, specified using a simple and intuitive interface that includes a user click or a text prompt. To this end, we present DGD, a unified 3D representation for both the appearance and semantics of a dynamic 3D scene, building upon the recently proposed dynamic 3D Gaussians representation. Our representation is optimized over time with both color and semantic information. Key to our method is the joint optimization of the appearance and semantic attributes, which jointly affect the geometric properties of the scene. We evaluate our approach in its ability to enable dense semantic 3D object tracking and demonstrate high-quality results that are fast to render, for a diverse set of scenes. Our project webpage is available on https://isaaclabe.github.io/DGD-Website/