 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity-Balanced Diffusion Splitting
Jun 04, 2026Standard continuous-time generative models rely on monolithic architectures that must navigate vastly different signal regimes, from isotropic noise to intricate data distributions. While scaling model capacity improves performance, deploying a massive network uniformly across the entire generative timeline is inherently inefficient. In this work, we propose Complexity-Balanced Splitting (CBS), a principled framework for temporal capacity allocation that distributes the generative workload across multiple specialized sub-networks. Grounded in function approximation theory and de Boor's equidistribution principle, CBS partitions the diffusion timeline into segments of equal approximation burden, allocating more representational capacity to regions where the generative dynamics are more difficult to model. To estimate this local complexity, we introduce two complementary and tractable monitor functions: a spatial measure based on the flow's Dirichlet energy, and a geometric measure based on the acceleration of the sampling trajectories. Using a lightweight auxiliary model to estimate these complexity profiles, our approach eliminates the need for heuristic temporal splits or computationally expensive search procedures. Extensive evaluation across multiple architectures (SiT, JiT, and UNet) and datasets demonstrates that CBS consistently improves synthesis quality without increasing per-step inference cost. In particular, CBS improves FID by ~35% on SiT-XL with CFG relative to naive temporal partitioning. Project page is available at https://noamissachar.github.io/CBS/.
DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
Oct 23, 2025Diffusion Transformer models can generate images with remarkable fidelity and detail, yet training them at ultra-high resolutions remains extremely costly due to the self-attention mechanism's quadratic scaling with the number of image tokens. In this paper, we introduce Dynamic Position Extrapolation (DyPE), a novel, training-free method that enables pre-trained diffusion transformers to synthesize images at resolutions far beyond their training data, with no additional sampling cost. DyPE takes advantage of the spectral progression inherent to the diffusion process, where low-frequency structures converge early, while high-frequencies take more steps to resolve. Specifically, DyPE dynamically adjusts the model's positional encoding at each diffusion step, matching their frequency spectrum with the current stage of the generative process. This approach allows us to generate images at resolutions that exceed the training resolution dramatically, e.g., 16 million pixels using FLUX. On multiple benchmarks, DyPE consistently improves performance and achieves state-of-the-art fidelity in ultra-high-resolution image generation, with gains becoming even more pronounced at higher resolutions. Project page is available at https://noamissachar.github.io/DyPE/.
Designing a Conditional Prior Distribution for Flow-Based Generative Models
Feb 13, 2025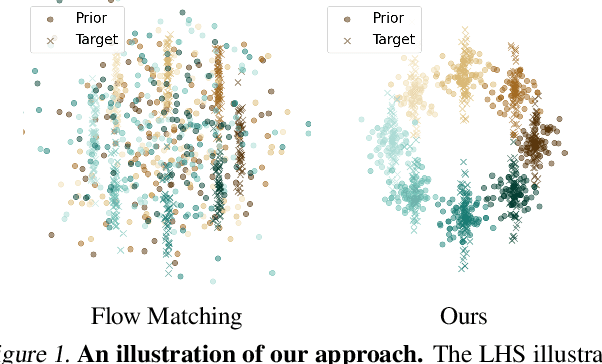

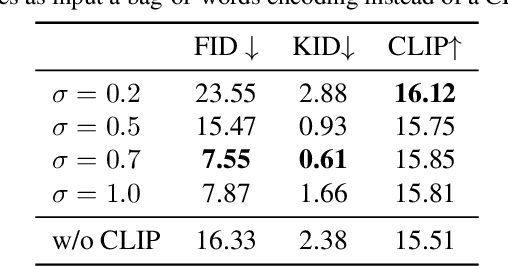
Flow-based generative models have recently shown impressive performance for conditional generation tasks, such as text-to-image generation. However, current methods transform a general unimodal noise distribution to a specific mode of the target data distribution. As such, every point in the initial source distribution can be mapped to every point in the target distribution, resulting in long average paths. To this end, in this work, we tap into a non-utilized property of conditional flow-based models: the ability to design a non-trivial prior distribution. Given an input condition, such as a text prompt, we first map it to a point lying in data space, representing an ``average" data point with the minimal average distance to all data points of the same conditional mode (e.g., class). We then utilize the flow matching formulation to map samples from a parametric distribution centered around this point to the conditional target distribution. Experimentally, our method significantly improves training times and generation efficiency (FID, KID and CLIP alignment scores) compared to baselines, producing high quality samples using fewer sampling steps.
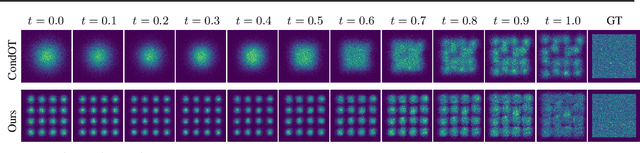
Generative Lines Matching Models
Dec 09, 2024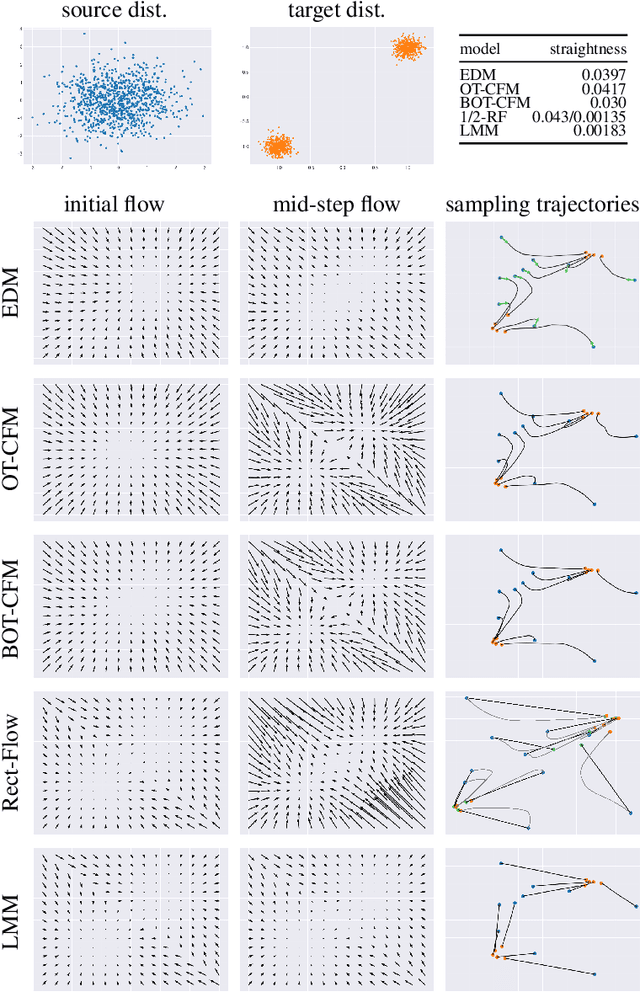



In this paper we identify the source of a singularity in the training loss of key denoising models, that causes the denoiser's predictions to collapse towards the mean of the source or target distributions. This degeneracy creates false basins of attraction, distorting the denoising trajectories and ultimately increasing the number of steps required to sample these models. We circumvent this artifact by leveraging the deterministic ODE-based samplers, offered by certain denoising diffusion and score-matching models, which establish a well-defined change-of-variables between the source and target distributions. Given this correspondence, we propose a new probability flow model, the Lines Matching Model (LMM), which matches globally straight lines interpolating the two distributions. We demonstrate that the flow fields produced by the LMM exhibit notable temporal consistency, resulting in trajectories with excellent straightness scores. Beyond its sampling efficiency, the LMM formulation allows us to enhance the fidelity of the generated samples by integrating domain-specific reconstruction and adversarial losses, and by optimizing its training for the sampling procedure used. Overall, the LMM achieves state-of-the-art FID scores with minimal NFEs on established benchmark datasets: 1.57/1.39 (NFE=1/2) on CIFAR-10, 1.47/1.17 on ImageNet 64x64, and 2.68/1.54 on AFHQ 64x64. Finally, we provide a theoretical analysis showing that the use of optimal transport to relate the two distributions suffers from a curse of dimensionality, where the pairing set size (mini-batch) must scale exponentially with the signal dimension.
ContactNet: Geometric-Based Deep Learning Model for Predicting Protein-Protein Interactions
Jun 26, 2024Deep learning approaches achieved significant progress in predicting protein structures. These methods are often applied to protein-protein interactions (PPIs) yet require Multiple Sequence Alignment (MSA) which is unavailable for various interactions, such as antibody-antigen. Computational docking methods are capable of sampling accurate complex models, but also produce thousands of invalid configurations. The design of scoring functions for identifying accurate models is a long-standing challenge. We develop a novel attention-based Graph Neural Network (GNN), ContactNet, for classifying PPI models obtained from docking algorithms into accurate and incorrect ones. When trained on docked antigen and modeled antibody structures, ContactNet doubles the accuracy of current state-of-the-art scoring functions, achieving accurate models among its Top-10 at 43% of the test cases. When applied to unbound antibodies, its Top-10 accuracy increases to 65%. This performance is achieved without MSA and the approach is applicable to other types of interactions, such as host-pathogens or general PPIs.
Single Image Object Counting and Localizing using Active-Learning
Nov 16, 2021
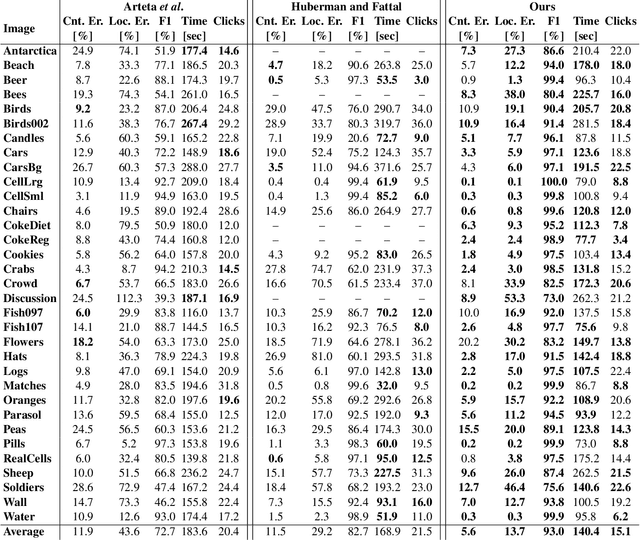


The need to count and localize repeating objects in an image arises in different scenarios, such as biological microscopy studies, production lines inspection, and surveillance recordings analysis. The use of supervised Convoutional Neural Networks (CNNs) achieves accurate object detection when trained over large class-specific datasets. The labeling effort in this approach does not pay-off when the counting is required over few images of a unique object class. We present a new method for counting and localizing repeating objects in single-image scenarios, assuming no pre-trained classifier is available. Our method trains a CNN over a small set of labels carefully collected from the input image in few active-learning iterations. At each iteration, the latent space of the network is analyzed to extract a minimal number of user-queries that strives to both sample the in-class manifold as thoroughly as possible as well as avoid redundant labels. Compared with existing user-assisted counting methods, our active-learning iterations achieve state-of-the-art performance in terms of counting and localizing accuracy, number of user mouse clicks, and running-time. This evaluation was performed through a large user study over a wide range of image classes with diverse conditions of illumination and occlusions.
Unpaired Learning for High Dynamic Range Image Tone Mapping
Oct 30, 2021


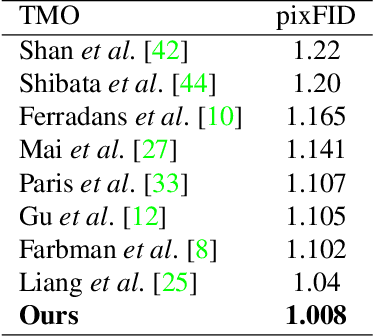
High dynamic range (HDR) photography is becoming increasingly popular and available by DSLR and mobile-phone cameras. While deep neural networks (DNN) have greatly impacted other domains of image manipulation, their use for HDR tone-mapping is limited due to the lack of a definite notion of ground-truth solution, which is needed for producing training data. In this paper we describe a new tone-mapping approach guided by the distinct goal of producing low dynamic range (LDR) renditions that best reproduce the visual characteristics of native LDR images. This goal enables the use of an unpaired adversarial training based on unrelated sets of HDR and LDR images, both of which are widely available and easy to acquire. In order to achieve an effective training under this minimal requirements, we introduce the following new steps and components: (i) a range-normalizing pre-process which estimates and applies a different level of curve-based compression, (ii) a loss that preserves the input content while allowing the network to achieve its goal, and (iii) the use of a more concise discriminator network, designed to promote the reproduction of low-level attributes native LDR possess. Evaluation of the resulting network demonstrates its ability to produce photo-realistic artifact-free tone-mapped images, and state-of-the-art performance on different image fidelity indices and visual distances.
Deblurring using Analysis-Synthesis Networks Pair
Apr 06, 2020
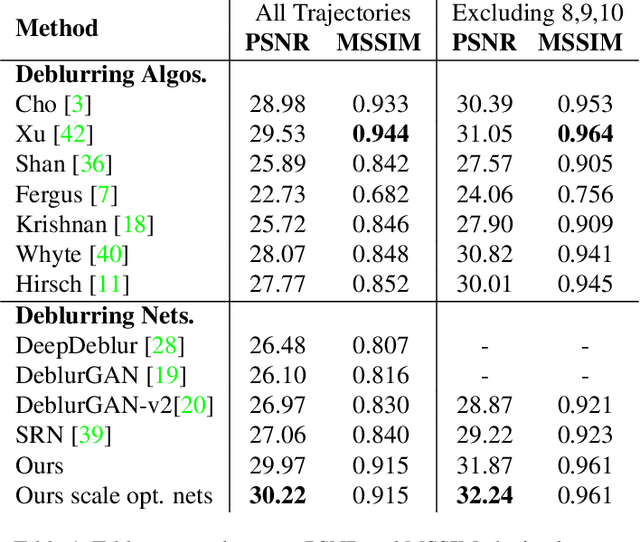
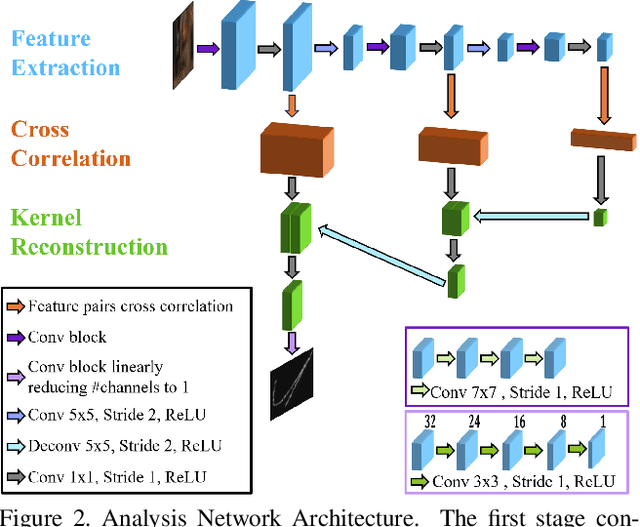
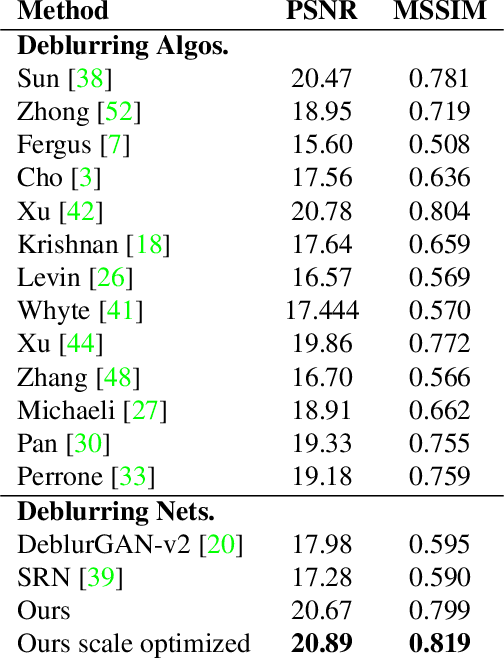
Blind image deblurring remains a challenging problem for modern artificial neural networks. Unlike other image restoration problems, deblurring networks fail behind the performance of existing deblurring algorithms in case of uniform and 3D blur models. This follows from the diverse and profound effect that the unknown blur-kernel has on the deblurring operator. We propose a new architecture which breaks the deblurring network into an analysis network which estimates the blur, and a synthesis network that uses this kernel to deblur the image. Unlike existing deblurring networks, this design allows us to explicitly incorporate the blur-kernel in the network's training. In addition, we introduce new cross-correlation layers that allow better blur estimations, as well as unique components that allow the estimate blur to control the action of the synthesis deblurring action. Evaluating the new approach over established benchmark datasets shows its ability to achieve state-of-the-art deblurring accuracy on various tests, as well as offer a major speedup in runtime.
Detecting Repeating Objects using Patch Correlation Analysis
Apr 11, 2019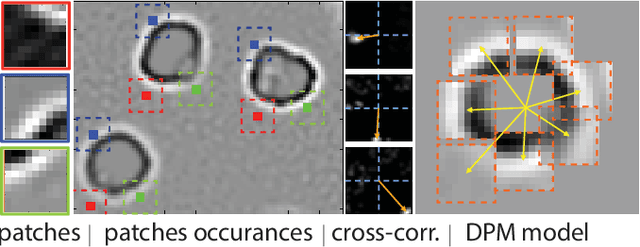
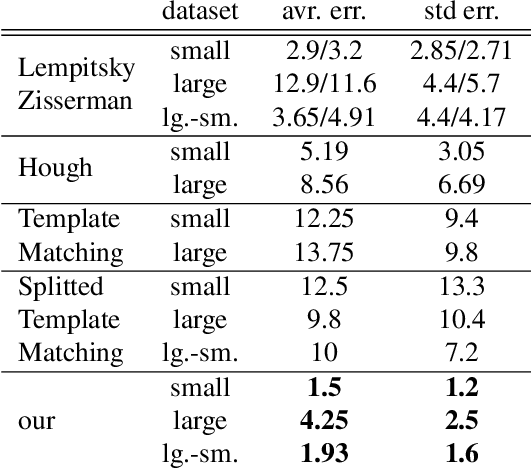
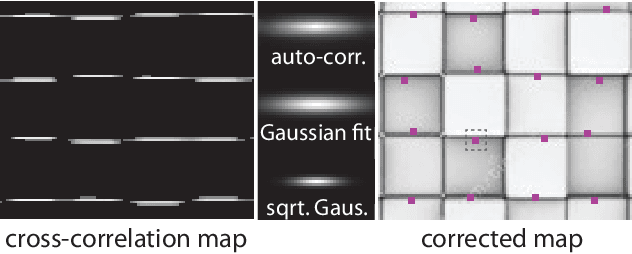
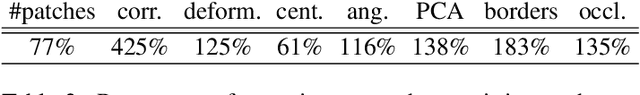
In this paper we describe a new method for detecting and counting a repeating object in an image. While the method relies on a fairly sophisticated deformable part model, unlike existing techniques it estimates the model parameters in an unsupervised fashion thus alleviating the need for a user-annotated training data and avoiding the associated specificity. This automatic fitting process is carried out by exploiting the recurrence of small image patches associated with the repeating object and analyzing their spatial correlation. The analysis allows us to reject outlier patches, recover the visual and shape parameters of the part model, and detect the object instances efficiently. In order to achieve a practical system which is able to cope with diverse images, we describe a simple and intuitive active-learning procedure that updates the object classification by querying the user on very few carefully chosen marginal classifications. Evaluation of the new method against the state-of-the-art techniques demonstrates its ability to achieve higher accuracy through a better user experience.
Reducing Lateral Visual Biases in Displays
Apr 11, 2019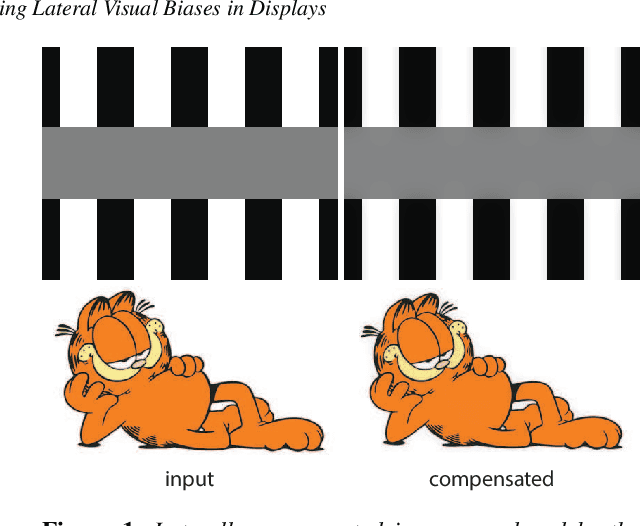

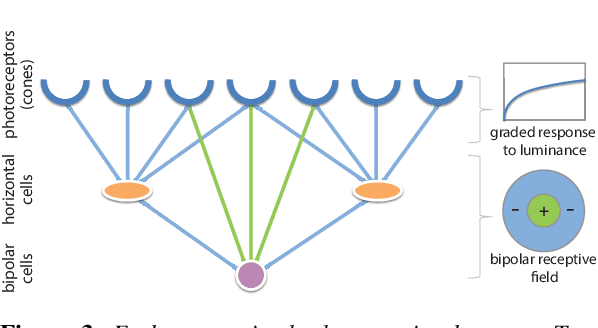
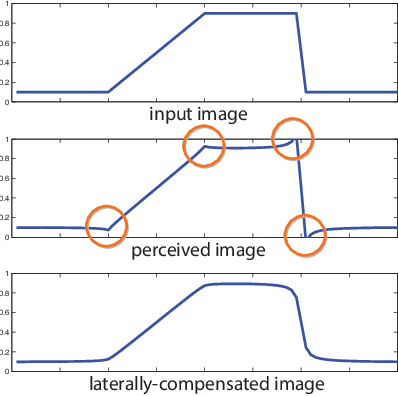
The human visual system is composed of multiple physiological components that apply multiple mechanisms in order to cope with the rich visual content it encounters. The complexity of this system leads to non-trivial relations between what we see and what we perceive, and in particular, between the raw intensities of an image that we display and the ones we perceive where various visual biases and illusions are introduced. In this paper we describe a method for reducing a large class of biases related to the lateral inhibition mechanism in the human retina where neurons suppress the activity of neighboring receptors. Among these biases are the well-known Mach bands and halos that appear around smooth and sharp image gradients as well as the appearance of false contrasts between identical regions. The new method removes these visual biases by computing an image that contains counter biases such that when this laterally-compensated image is viewed on a display, the inserted biases cancel the ones created in the retina.