 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContactNet: Geometric-Based Deep Learning Model for Predicting Protein-Protein Interactions
Jun 26, 2024Deep learning approaches achieved significant progress in predicting protein structures. These methods are often applied to protein-protein interactions (PPIs) yet require Multiple Sequence Alignment (MSA) which is unavailable for various interactions, such as antibody-antigen. Computational docking methods are capable of sampling accurate complex models, but also produce thousands of invalid configurations. The design of scoring functions for identifying accurate models is a long-standing challenge. We develop a novel attention-based Graph Neural Network (GNN), ContactNet, for classifying PPI models obtained from docking algorithms into accurate and incorrect ones. When trained on docked antigen and modeled antibody structures, ContactNet doubles the accuracy of current state-of-the-art scoring functions, achieving accurate models among its Top-10 at 43% of the test cases. When applied to unbound antibodies, its Top-10 accuracy increases to 65%. This performance is achieved without MSA and the approach is applicable to other types of interactions, such as host-pathogens or general PPIs.
Molecular Diffusion Models with Virtual Receptors
Jun 26, 2024


Machine learning approaches to Structure-Based Drug Design (SBDD) have proven quite fertile over the last few years. In particular, diffusion-based approaches to SBDD have shown great promise. We present a technique which expands on this diffusion approach in two crucial ways. First, we address the size disparity between the drug molecule and the target/receptor, which makes learning more challenging and inference slower. We do so through the notion of a Virtual Receptor, which is a compressed version of the receptor; it is learned so as to preserve key aspects of the structural information of the original receptor, while respecting the relevant group equivariance. Second, we incorporate a protein language embedding used originally in the context of protein folding. We experimentally demonstrate the contributions of both the virtual receptors and the protein embeddings: in practice, they lead to both better performance, as well as significantly faster computations.
Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?
Mar 04, 2024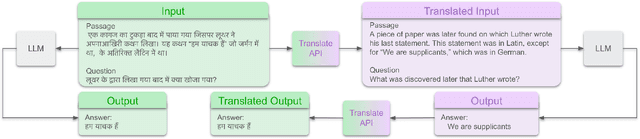
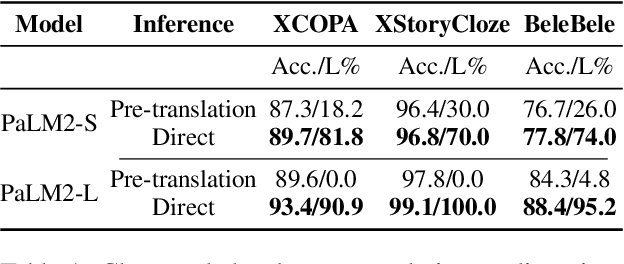

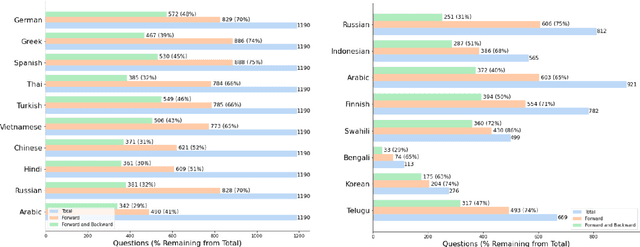
Large language models hold significant promise in multilingual applications. However, inherent biases stemming from predominantly English-centric pre-training have led to the widespread practice of pre-translation, i.e., translating non-English inputs to English before inference, leading to complexity and information loss. This study re-evaluates the need for pre-translation in the context of PaLM2 models (Anil et al., 2023), which have been established as highly performant in multilingual tasks. We offer a comprehensive investigation across 108 languages and 6 diverse benchmarks, including open-end generative tasks, which were excluded from previous similar studies. Our findings challenge the pre-translation paradigm established in prior research, highlighting the advantages of direct inference in PaLM2. Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages. These findings pave the way for more efficient and effective multilingual applications, alleviating the limitations associated with pre-translation and unlocking linguistic authenticity.