 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMESSI: A Multi-Elevation Semantic Segmentation Image Dataset of an Urban Environment
May 13, 2025This paper presents a Multi-Elevation Semantic Segmentation Image (MESSI) dataset comprising 2525 images taken by a drone flying over dense urban environments. MESSI is unique in two main features. First, it contains images from various altitudes, allowing us to investigate the effect of depth on semantic segmentation. Second, it includes images taken from several different urban regions (at different altitudes). This is important since the variety covers the visual richness captured by a drone's 3D flight, performing horizontal and vertical maneuvers. MESSI contains images annotated with location, orientation, and the camera's intrinsic parameters and can be used to train a deep neural network for semantic segmentation or other applications of interest (e.g., localization, navigation, and tracking). This paper describes the dataset and provides annotation details. It also explains how semantic segmentation was performed using several neural network models and shows several relevant statistics. MESSI will be published in the public domain to serve as an evaluation benchmark for semantic segmentation using images captured by a drone or similar vehicle flying over a dense urban environment.
Neural Descriptors: Self-Supervised Learning of Robust Local Surface Descriptors Using Polynomial Patches
Mar 05, 2025Classical shape descriptors such as Heat Kernel Signature (HKS), Wave Kernel Signature (WKS), and Signature of Histograms of OrienTations (SHOT), while widely used in shape analysis, exhibit sensitivity to mesh connectivity, sampling patterns, and topological noise. While differential geometry offers a promising alternative through its theory of differential invariants, which are theoretically guaranteed to be robust shape descriptors, the computation of these invariants on discrete meshes often leads to unstable numerical approximations, limiting their practical utility. We present a self-supervised learning approach for extracting geometric features from 3D surfaces. Our method combines synthetic data generation with a neural architecture designed to learn sampling-invariant features. By integrating our features into existing shape correspondence frameworks, we demonstrate improved performance on standard benchmarks including FAUST, SCAPE, TOPKIDS, and SHREC'16, showing particular robustness to topological noise and partial shapes.
Streamlining Conformal Information Retrieval via Score Refinement
Oct 03, 2024
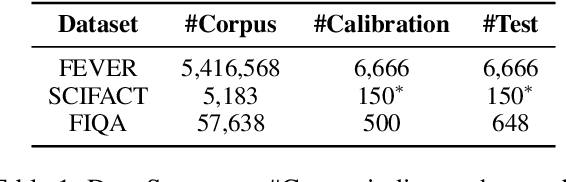
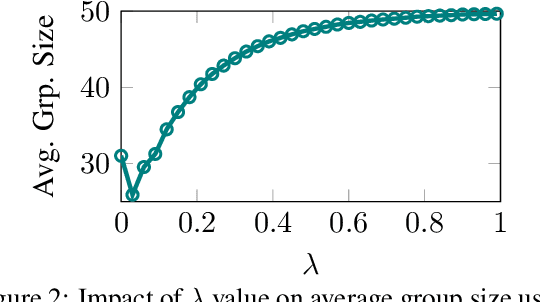
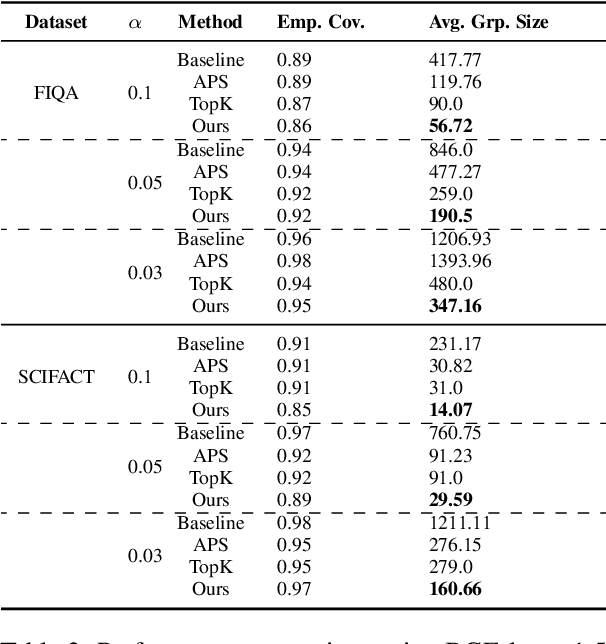
Information retrieval (IR) methods, like retrieval augmented generation, are fundamental to modern applications but often lack statistical guarantees. Conformal prediction addresses this by retrieving sets guaranteed to include relevant information, yet existing approaches produce large-sized sets, incurring high computational costs and slow response times. In this work, we introduce a score refinement method that applies a simple monotone transformation to retrieval scores, leading to significantly smaller conformal sets while maintaining their statistical guarantees. Experiments on various BEIR benchmarks validate the effectiveness of our approach in producing compact sets containing relevant information.
Anchored Diffusion for Video Face Reenactment
Jul 21, 2024
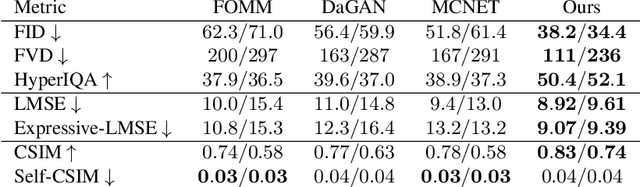
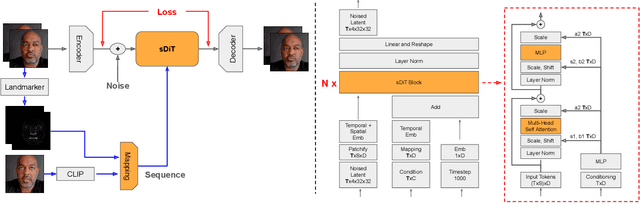

Video generation has drawn significant interest recently, pushing the development of large-scale models capable of producing realistic videos with coherent motion. Due to memory constraints, these models typically generate short video segments that are then combined into long videos. The merging process poses a significant challenge, as it requires ensuring smooth transitions and overall consistency. In this paper, we introduce Anchored Diffusion, a novel method for synthesizing relatively long and seamless videos. We extend Diffusion Transformers (DiTs) to incorporate temporal information, creating our sequence-DiT (sDiT) model for generating short video segments. Unlike previous works, we train our model on video sequences with random non-uniform temporal spacing and incorporate temporal information via external guidance, increasing flexibility and allowing it to capture both short and long-term relationships. Furthermore, during inference, we leverage the transformer architecture to modify the diffusion process, generating a batch of non-uniform sequences anchored to a common frame, ensuring consistency regardless of temporal distance. To demonstrate our method, we focus on face reenactment, the task of creating a video from a source image that replicates the facial expressions and movements from a driving video. Through comprehensive experiments, we show our approach outperforms current techniques in producing longer consistent high-quality videos while offering editing capabilities.
Molecular Diffusion Models with Virtual Receptors
Jun 26, 2024


Machine learning approaches to Structure-Based Drug Design (SBDD) have proven quite fertile over the last few years. In particular, diffusion-based approaches to SBDD have shown great promise. We present a technique which expands on this diffusion approach in two crucial ways. First, we address the size disparity between the drug molecule and the target/receptor, which makes learning more challenging and inference slower. We do so through the notion of a Virtual Receptor, which is a compressed version of the receptor; it is learned so as to preserve key aspects of the structural information of the original receptor, while respecting the relevant group equivariance. Second, we incorporate a protein language embedding used originally in the context of protein folding. We experimentally demonstrate the contributions of both the virtual receptors and the protein embeddings: in practice, they lead to both better performance, as well as significantly faster computations.
Looks Too Good To Be True: An Information-Theoretic Analysis of Hallucinations in Generative Restoration Models
May 26, 2024



The pursuit of high perceptual quality in image restoration has driven the development of revolutionary generative models, capable of producing results often visually indistinguishable from real data. However, as their perceptual quality continues to improve, these models also exhibit a growing tendency to generate hallucinations - realistic-looking details that do not exist in the ground truth images. The presence of hallucinations introduces uncertainty regarding the reliability of the models' predictions, raising major concerns about their practical application. In this paper, we employ information-theory tools to investigate this phenomenon, revealing a fundamental tradeoff between uncertainty and perception. We rigorously analyze the relationship between these two factors, proving that the global minimal uncertainty in generative models grows in tandem with perception. In particular, we define the inherent uncertainty of the restoration problem and show that attaining perfect perceptual quality entails at least twice this uncertainty. Additionally, we establish a relation between mean squared-error distortion, uncertainty and perception, through which we prove the aforementioned uncertainly-perception tradeoff induces the well-known perception-distortion tradeoff. This work uncovers fundamental limitations of generative models in achieving both high perceptual quality and reliable predictions for image restoration. We demonstrate our theoretical findings through an analysis of single image super-resolution algorithms. Our work aims to raise awareness among practitioners about this inherent tradeoff, empowering them to make informed decisions and potentially prioritize safety over perceptual performance.
Uncertainty-Aware PPG-2-ECG for Enhanced Cardiovascular Diagnosis using Diffusion Models
May 19, 2024Analyzing the cardiovascular system condition via Electrocardiography (ECG) is a common and highly effective approach, and it has been practiced and perfected over many decades. ECG sensing is non-invasive and relatively easy to acquire, and yet it is still cumbersome for holter monitoring tests that may span over hours and even days. A possible alternative in this context is Photoplethysmography (PPG): An optically-based signal that measures blood volume fluctuations, as typically sensed by conventional ``wearable devices''. While PPG presents clear advantages in acquisition, convenience, and cost-effectiveness, ECG provides more comprehensive information, allowing for a more precise detection of heart conditions. This implies that a conversion from PPG to ECG, as recently discussed in the literature, inherently involves an unavoidable level of uncertainty. In this paper we introduce a novel methodology for addressing the PPG-2-ECG conversion, and offer an enhanced classification of cardiovascular conditions using the given PPG, all while taking into account the uncertainties arising from the conversion process. We provide a mathematical justification for our proposed computational approach, and present empirical studies demonstrating its superior performance compared to state-of-the-art baseline methods.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 22, 2024



$\textbf{Background}$: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. $\textbf{Methods}$: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. $\textbf{Results}$: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). $\textbf{Conclusion}$: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?
Mar 04, 2024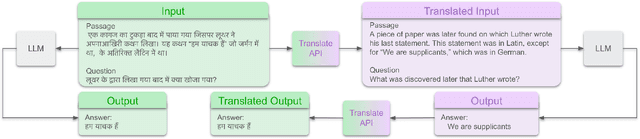
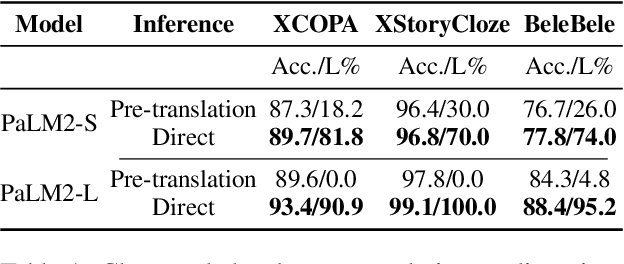

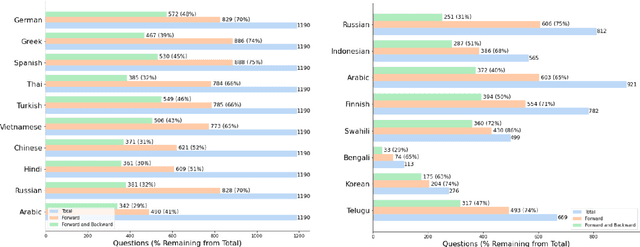
Large language models hold significant promise in multilingual applications. However, inherent biases stemming from predominantly English-centric pre-training have led to the widespread practice of pre-translation, i.e., translating non-English inputs to English before inference, leading to complexity and information loss. This study re-evaluates the need for pre-translation in the context of PaLM2 models (Anil et al., 2023), which have been established as highly performant in multilingual tasks. We offer a comprehensive investigation across 108 languages and 6 diverse benchmarks, including open-end generative tasks, which were excluded from previous similar studies. Our findings challenge the pre-translation paradigm established in prior research, highlighting the advantages of direct inference in PaLM2. Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages. These findings pave the way for more efficient and effective multilingual applications, alleviating the limitations associated with pre-translation and unlocking linguistic authenticity.