 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundSet: A Cadastral-Grounded Dataset for Spatial Understanding with Vector Data
Mar 15, 2026Precise spatial understanding in Earth Observation is essential for translating raw aerial imagery into actionable insights for critical applications like urban planning, environmental monitoring and disaster management. However, Multimodal Large Language Models exhibit critical deficiencies in fine-grained spatial understanding within Remote Sensing, primarily due to a reliance on limited or repurposed legacy datasets. To bridge this gap, we introduce a large-scale dataset grounded in verifiable cadastral vector data, comprising 3.8 million annotated objects across 510k high-resolution images with 135 granular semantic categories. We validate this resource through a comprehensive instruction-tuning benchmark spanning seven spatial reasoning tasks. Our evaluation establishes a robust baseline using a standard LLaVA architecture. We show that while current RS-specialized and commercial models (e.g., Gemini) struggle in zero-shot settings, high-fidelity supervision effectively bridges this gap, enabling standard architectures to master fine-grained spatial grounding without complex architectural modifications.
Anchored Diffusion for Video Face Reenactment
Jul 21, 2024
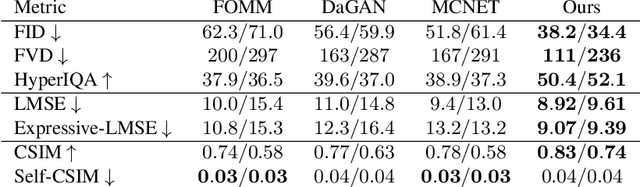
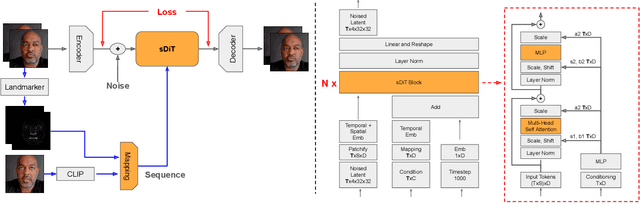

Video generation has drawn significant interest recently, pushing the development of large-scale models capable of producing realistic videos with coherent motion. Due to memory constraints, these models typically generate short video segments that are then combined into long videos. The merging process poses a significant challenge, as it requires ensuring smooth transitions and overall consistency. In this paper, we introduce Anchored Diffusion, a novel method for synthesizing relatively long and seamless videos. We extend Diffusion Transformers (DiTs) to incorporate temporal information, creating our sequence-DiT (sDiT) model for generating short video segments. Unlike previous works, we train our model on video sequences with random non-uniform temporal spacing and incorporate temporal information via external guidance, increasing flexibility and allowing it to capture both short and long-term relationships. Furthermore, during inference, we leverage the transformer architecture to modify the diffusion process, generating a batch of non-uniform sequences anchored to a common frame, ensuring consistency regardless of temporal distance. To demonstrate our method, we focus on face reenactment, the task of creating a video from a source image that replicates the facial expressions and movements from a driving video. Through comprehensive experiments, we show our approach outperforms current techniques in producing longer consistent high-quality videos while offering editing capabilities.
Uncertainty-Aware PPG-2-ECG for Enhanced Cardiovascular Diagnosis using Diffusion Models
May 19, 2024Analyzing the cardiovascular system condition via Electrocardiography (ECG) is a common and highly effective approach, and it has been practiced and perfected over many decades. ECG sensing is non-invasive and relatively easy to acquire, and yet it is still cumbersome for holter monitoring tests that may span over hours and even days. A possible alternative in this context is Photoplethysmography (PPG): An optically-based signal that measures blood volume fluctuations, as typically sensed by conventional ``wearable devices''. While PPG presents clear advantages in acquisition, convenience, and cost-effectiveness, ECG provides more comprehensive information, allowing for a more precise detection of heart conditions. This implies that a conversion from PPG to ECG, as recently discussed in the literature, inherently involves an unavoidable level of uncertainty. In this paper we introduce a novel methodology for addressing the PPG-2-ECG conversion, and offer an enhanced classification of cardiovascular conditions using the given PPG, all while taking into account the uncertainties arising from the conversion process. We provide a mathematical justification for our proposed computational approach, and present empirical studies demonstrating its superior performance compared to state-of-the-art baseline methods.
Semi-supervised Quality Evaluation of Colonoscopy Procedures
May 17, 2023



Colonoscopy is the standard of care technique for detecting and removing polyps for the prevention of colorectal cancer. Nevertheless, gastroenterologists (GI) routinely miss approximately 25% of polyps during colonoscopies. These misses are highly operator dependent, influenced by the physician skills, experience, vigilance, and fatigue. Standard quality metrics, such as Withdrawal Time or Cecal Intubation Rate, have been shown to be well correlated with Adenoma Detection Rate (ADR). However, those metrics are limited in their ability to assess the quality of a specific procedure, and they do not address quality aspects related to the style or technique of the examination. In this work we design novel online and offline quality metrics, based on visual appearance quality criteria learned by an ML model in an unsupervised way. Furthermore, we evaluate the likelihood of detecting an existing polyp as a function of quality and use it to demonstrate high correlation of the proposed metric to polyp detection sensitivity. The proposed online quality metric can be used to provide real time quality feedback to the performing GI. By integrating the local metric over the withdrawal phase, we build a global, offline quality metric, which is shown to be highly correlated to the standard Polyp Per Colonoscopy (PPC) quality metric.
Weakly-supervised Representation Learning for Video Alignment and Analysis
Feb 08, 2023Many tasks in video analysis and understanding boil down to the need for frame-based feature learning, aiming to encapsulate the relevant visual content so as to enable simpler and easier subsequent processing. While supervised strategies for this learning task can be envisioned, self and weakly-supervised alternatives are preferred due to the difficulties in getting labeled data. This paper introduces LRProp -- a novel weakly-supervised representation learning approach, with an emphasis on the application of temporal alignment between pairs of videos of the same action category. The proposed approach uses a transformer encoder for extracting frame-level features, and employs the DTW algorithm within the training iterations in order to identify the alignment path between video pairs. Through a process referred to as ``pair-wise position propagation'', the probability distributions of these correspondences per location are matched with the similarity of the frame-level features via KL-divergence minimization. The proposed algorithm uses also a regularized SoftDTW loss for better tuning the learned features. Our novel representation learning paradigm consistently outperforms the state of the art on temporal alignment tasks, establishing a new performance bar over several downstream video analysis applications.