 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Diffusion for Video Face Reenactment
Paper and Code
Jul 21, 2024
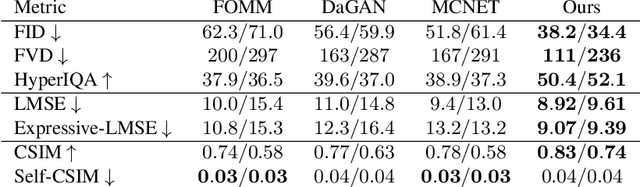
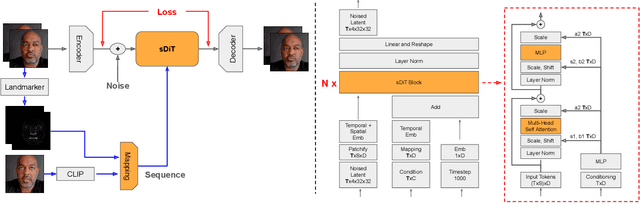

Video generation has drawn significant interest recently, pushing the development of large-scale models capable of producing realistic videos with coherent motion. Due to memory constraints, these models typically generate short video segments that are then combined into long videos. The merging process poses a significant challenge, as it requires ensuring smooth transitions and overall consistency. In this paper, we introduce Anchored Diffusion, a novel method for synthesizing relatively long and seamless videos. We extend Diffusion Transformers (DiTs) to incorporate temporal information, creating our sequence-DiT (sDiT) model for generating short video segments. Unlike previous works, we train our model on video sequences with random non-uniform temporal spacing and incorporate temporal information via external guidance, increasing flexibility and allowing it to capture both short and long-term relationships. Furthermore, during inference, we leverage the transformer architecture to modify the diffusion process, generating a batch of non-uniform sequences anchored to a common frame, ensuring consistency regardless of temporal distance. To demonstrate our method, we focus on face reenactment, the task of creating a video from a source image that replicates the facial expressions and movements from a driving video. Through comprehensive experiments, we show our approach outperforms current techniques in producing longer consistent high-quality videos while offering editing capabilities.