 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditor's Choice: Evaluating Abstract Intent in Image Editing through Atomic Entity Analysis
May 14, 2026Humans naturally communicate through abstract concepts like "mood". However, current image editing benchmarks focus primarily on explicit, literal commands, leaving abstract instructions largely underexplored. In this work, we first formalize the definition and taxonomy of abstract image editing. To measure instruction-following in this challenging domain, we introduce Entity-Rubrics, a framework that breaks down abstract edits into individual, entity-level assessments and achieves strong correlation with human judgment. Alongside this framework, we contribute AbstractEdit, the first benchmark dedicated to abstract image editing across diverse real-world scenes. Evaluating 11 leading models on this dataset reveals a fundamental challenge: standard architectures struggle to balance intent and preservation, commonly defaulting to under-editing or over-editing. Our analysis demonstrates that driving meaningful improvements relies heavily on integrating advanced LLM text encoders and iterative thinking. Looking forward, our entity-based paradigm can generalize beyond assessment to serve as a reward model, enable models to correctly interpret abstract communication, or highlight specific failures in test-time critique loops. Ultimately, we hope this work serves as a stepping stone toward seamless multimodal interaction, closing the gap between rigid machine execution and the natural, open-ended way humans communicate.
FUSE: Ensembling Verifiers with Zero Labeled Data
Apr 20, 2026Verification of model outputs is rapidly emerging as a key primitive for both training and real-world deployment of large language models (LLMs). In practice, this often involves using imperfect LLM judges and reward models since ground truth acquisition can be time-consuming and expensive. We introduce Fully Unsupervised Score Ensembling (FUSE), a method for improving verification quality by ensembling verifiers without access to ground truth correctness labels. The key idea behind FUSE is to control conditional dependencies between verifiers in a manner that improves the unsupervised performance of a class of spectral algorithms from the ensembling literature. Despite requiring zero ground truth labels, FUSE typically matches or improves upon semi-supervised alternatives in test-time scaling experiments with diverse sets of generator models, verifiers, and benchmarks. In particular, we validate our method on both conventional academic benchmarks such as GPQA Diamond and on frontier, unsaturated benchmarks such as Humanity's Last Exam and IMO Shortlist questions.
Beyond the Noise: Aligning Prompts with Latent Representations in Diffusion Models
Dec 09, 2025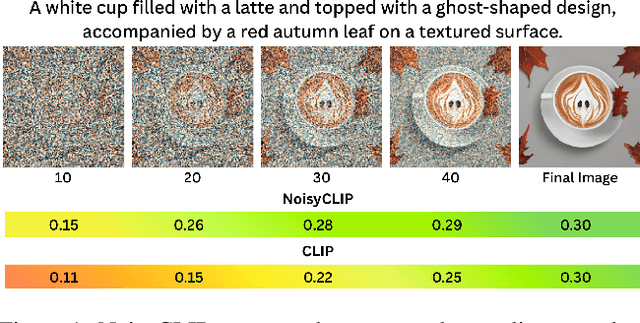
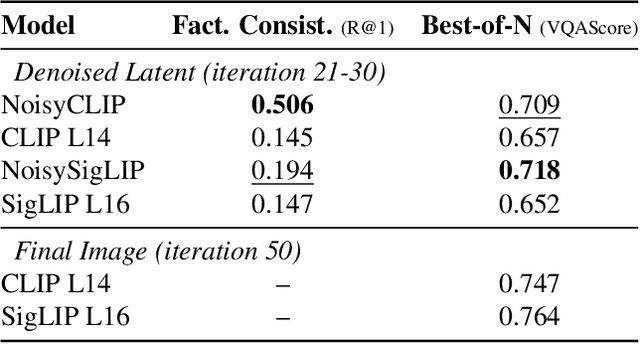
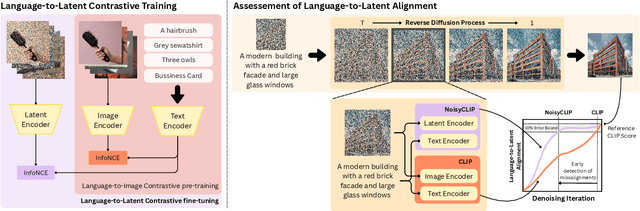
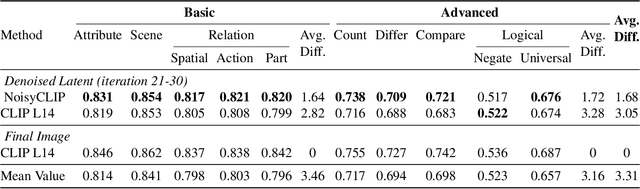
Conditional diffusion models rely on language-to-image alignment methods to steer the generation towards semantically accurate outputs. Despite the success of this architecture, misalignment and hallucinations remain common issues and require automatic misalignment detection tools to improve quality, for example by applying them in a Best-of-N (BoN) post-generation setting. Unfortunately, measuring the alignment after the generation is an expensive step since we need to wait for the overall generation to finish to determine prompt adherence. In contrast, this work hypothesizes that text/image misalignments can be detected early in the denoising process, enabling real-time alignment assessment without waiting for the complete generation. In particular, we propose NoisyCLIP a method that measures semantic alignment in the noisy latent space. This work is the first to explore and benchmark prompt-to-latent misalignment detection during image generation using dual encoders in the reverse diffusion process. We evaluate NoisyCLIP qualitatively and quantitatively and find it reduces computational cost by 50% while achieving 98% of CLIP alignment performance in BoN settings. This approach enables real-time alignment assessment during generation, reducing costs without sacrificing semantic fidelity.
Latent Beam Diffusion Models for Decoding Image Sequences
Mar 26, 2025



While diffusion models excel at generating high-quality images from text prompts, they struggle with visual consistency in image sequences. Existing methods generate each image independently, leading to disjointed narratives - a challenge further exacerbated in non-linear storytelling, where scenes must connect beyond adjacent frames. We introduce a novel beam search strategy for latent space exploration, enabling conditional generation of full image sequences with beam search decoding. Unlike prior approaches that use fixed latent priors, our method dynamically searches for an optimal sequence of latent representations, ensuring coherent visual transitions. To address beam search's quadratic complexity, we integrate a cross-attention mechanism that efficiently scores search paths and enables pruning, prioritizing alignment with both textual prompts and visual context. Human evaluations confirm that our approach outperforms baseline methods, producing full sequences with superior coherence, visual continuity, and textual alignment. By bridging advances in search optimization and latent space refinement, this work sets a new standard for structured image sequence generation.
Streamlining Conformal Information Retrieval via Score Refinement
Oct 03, 2024
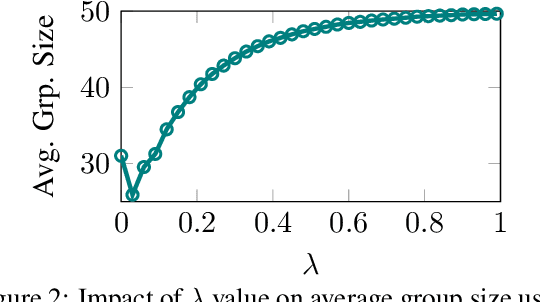
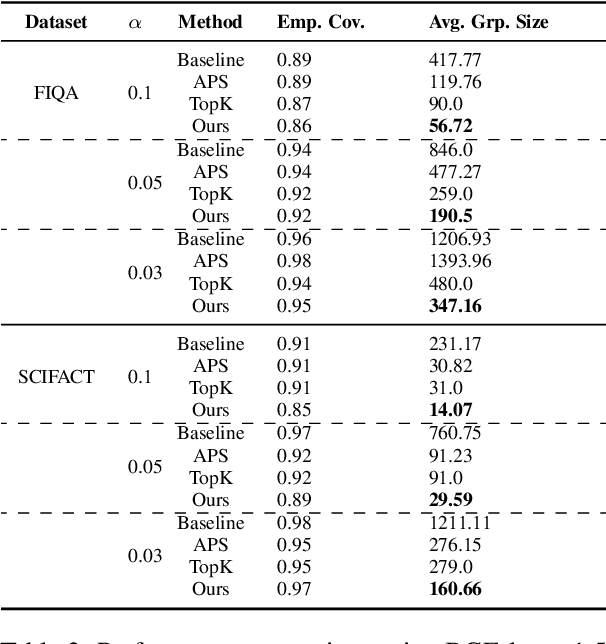
Information retrieval (IR) methods, like retrieval augmented generation, are fundamental to modern applications but often lack statistical guarantees. Conformal prediction addresses this by retrieving sets guaranteed to include relevant information, yet existing approaches produce large-sized sets, incurring high computational costs and slow response times. In this work, we introduce a score refinement method that applies a simple monotone transformation to retrieval scores, leading to significantly smaller conformal sets while maintaining their statistical guarantees. Experiments on various BEIR benchmarks validate the effectiveness of our approach in producing compact sets containing relevant information.
Anchored Diffusion for Video Face Reenactment
Jul 21, 2024
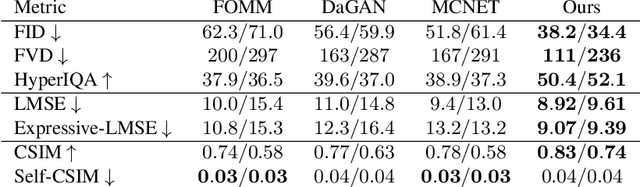
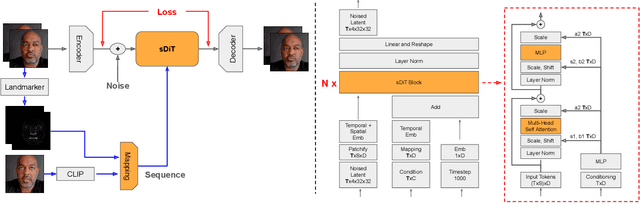

Video generation has drawn significant interest recently, pushing the development of large-scale models capable of producing realistic videos with coherent motion. Due to memory constraints, these models typically generate short video segments that are then combined into long videos. The merging process poses a significant challenge, as it requires ensuring smooth transitions and overall consistency. In this paper, we introduce Anchored Diffusion, a novel method for synthesizing relatively long and seamless videos. We extend Diffusion Transformers (DiTs) to incorporate temporal information, creating our sequence-DiT (sDiT) model for generating short video segments. Unlike previous works, we train our model on video sequences with random non-uniform temporal spacing and incorporate temporal information via external guidance, increasing flexibility and allowing it to capture both short and long-term relationships. Furthermore, during inference, we leverage the transformer architecture to modify the diffusion process, generating a batch of non-uniform sequences anchored to a common frame, ensuring consistency regardless of temporal distance. To demonstrate our method, we focus on face reenactment, the task of creating a video from a source image that replicates the facial expressions and movements from a driving video. Through comprehensive experiments, we show our approach outperforms current techniques in producing longer consistent high-quality videos while offering editing capabilities.
Looks Too Good To Be True: An Information-Theoretic Analysis of Hallucinations in Generative Restoration Models
May 26, 2024



The pursuit of high perceptual quality in image restoration has driven the development of revolutionary generative models, capable of producing results often visually indistinguishable from real data. However, as their perceptual quality continues to improve, these models also exhibit a growing tendency to generate hallucinations - realistic-looking details that do not exist in the ground truth images. The presence of hallucinations introduces uncertainty regarding the reliability of the models' predictions, raising major concerns about their practical application. In this paper, we employ information-theory tools to investigate this phenomenon, revealing a fundamental tradeoff between uncertainty and perception. We rigorously analyze the relationship between these two factors, proving that the global minimal uncertainty in generative models grows in tandem with perception. In particular, we define the inherent uncertainty of the restoration problem and show that attaining perfect perceptual quality entails at least twice this uncertainty. Additionally, we establish a relation between mean squared-error distortion, uncertainty and perception, through which we prove the aforementioned uncertainly-perception tradeoff induces the well-known perception-distortion tradeoff. This work uncovers fundamental limitations of generative models in achieving both high perceptual quality and reliable predictions for image restoration. We demonstrate our theoretical findings through an analysis of single image super-resolution algorithms. Our work aims to raise awareness among practitioners about this inherent tradeoff, empowering them to make informed decisions and potentially prioritize safety over perceptual performance.
Uncertainty-Aware PPG-2-ECG for Enhanced Cardiovascular Diagnosis using Diffusion Models
May 19, 2024Analyzing the cardiovascular system condition via Electrocardiography (ECG) is a common and highly effective approach, and it has been practiced and perfected over many decades. ECG sensing is non-invasive and relatively easy to acquire, and yet it is still cumbersome for holter monitoring tests that may span over hours and even days. A possible alternative in this context is Photoplethysmography (PPG): An optically-based signal that measures blood volume fluctuations, as typically sensed by conventional ``wearable devices''. While PPG presents clear advantages in acquisition, convenience, and cost-effectiveness, ECG provides more comprehensive information, allowing for a more precise detection of heart conditions. This implies that a conversion from PPG to ECG, as recently discussed in the literature, inherently involves an unavoidable level of uncertainty. In this paper we introduce a novel methodology for addressing the PPG-2-ECG conversion, and offer an enhanced classification of cardiovascular conditions using the given PPG, all while taking into account the uncertainties arising from the conversion process. We provide a mathematical justification for our proposed computational approach, and present empirical studies demonstrating its superior performance compared to state-of-the-art baseline methods.
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Feb 19, 2024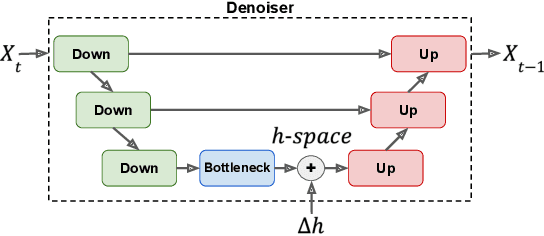

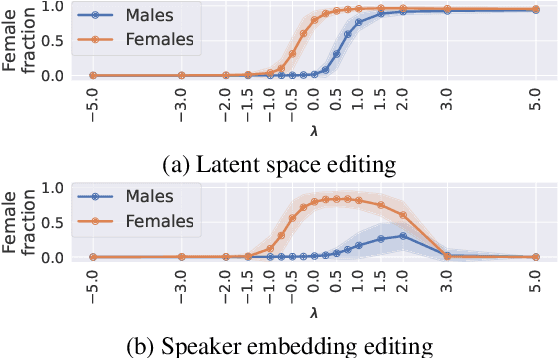

The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
Early Time Classification with Accumulated Accuracy Gap Control
Feb 01, 2024
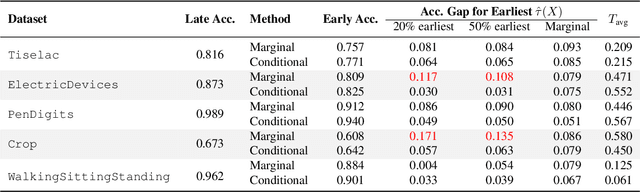
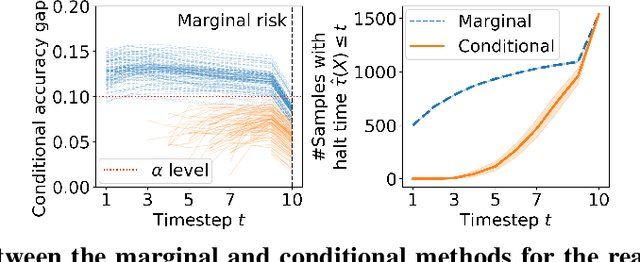
Early time classification algorithms aim to label a stream of features without processing the full input stream, while maintaining accuracy comparable to that achieved by applying the classifier to the entire input. In this paper, we introduce a statistical framework that can be applied to any sequential classifier, formulating a calibrated stopping rule. This data-driven rule attains finite-sample, distribution-free control of the accuracy gap between full and early-time classification. We start by presenting a novel method that builds on the Learn-then-Test calibration framework to control this gap marginally, on average over i.i.d. instances. As this algorithm tends to yield an excessively high accuracy gap for early halt times, our main contribution is the proposal of a framework that controls a stronger notion of error, where the accuracy gap is controlled conditionally on the accumulated halt times. Numerical experiments demonstrate the effectiveness, applicability, and usefulness of our method. We show that our proposed early stopping mechanism reduces up to 94% of timesteps used for classification while achieving rigorous accuracy gap control.