 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic-Powered Multiple Testing with FDR Control
Feb 18, 2026Multiple hypothesis testing with false discovery rate (FDR) control is a fundamental problem in statistical inference, with broad applications in genomics, drug screening, and outlier detection. In many such settings, researchers may have access not only to real experimental observations but also to auxiliary or synthetic data -- from past, related experiments or generated by generative models -- that can provide additional evidence about the hypotheses of interest. We introduce SynthBH, a synthetic-powered multiple testing procedure that safely leverages such synthetic data. We prove that SynthBH guarantees finite-sample, distribution-free FDR control under a mild PRDS-type positive dependence condition, without requiring the pooled-data p-values to be valid under the null. The proposed method adapts to the (unknown) quality of the synthetic data: it enhances the sample efficiency and may boost the power when synthetic data are of high quality, while controlling the FDR at a user-specified level regardless of their quality. We demonstrate the empirical performance of SynthBH on tabular outlier detection benchmarks and on genomic analyses of drug-cancer sensitivity associations, and further study its properties through controlled experiments on simulated data.
Testing For Distribution Shifts with Conditional Conformal Test Martingales
Feb 14, 2026We propose a sequential test for detecting arbitrary distribution shifts that allows conformal test martingales (CTMs) to work under a fixed, reference-conditional setting. Existing CTM detectors construct test martingales by continually growing a reference set with each incoming sample, using it to assess how atypical the new sample is relative to past observations. While this design yields anytime-valid type-I error control, it suffers from test-time contamination: after a change, post-shift observations enter the reference set and dilute the evidence for distribution shift, increasing detection delay and reducing power. In contrast, our method avoids contamination by design by comparing each new sample to a fixed null reference dataset. Our main technical contribution is a robust martingale construction that remains valid conditional on the null reference data, achieved by explicitly accounting for the estimation error in the reference distribution induced by the finite reference set. This yields anytime-valid type-I error control together with guarantees of asymptotic power one and bounded expected detection delay. Empirically, our method detects shifts faster than standard CTMs, providing a powerful and reliable distribution-shift detector.
Prediction-Powered Semi-Supervised Learning with Online Power Tuning
Oct 26, 2025



Prediction-Powered Inference (PPI) is a recently proposed statistical inference technique for parameter estimation that leverages pseudo-labels on both labeled and unlabeled data to construct an unbiased, low-variance estimator. In this work, we extend its core idea to semi-supervised learning (SSL) for model training, introducing a novel unbiased gradient estimator. This extension addresses a key challenge in SSL: while unlabeled data can improve model performance, its benefit heavily depends on the quality of pseudo-labels. Inaccurate pseudo-labels can introduce bias, leading to suboptimal models.To balance the contributions of labeled and pseudo-labeled data, we utilize an interpolation parameter and tune it on the fly, alongside the model parameters, using a one-dimensional online learning algorithm. We verify the practical advantage of our approach through experiments on both synthetic and real datasets, demonstrating improved performance over classic SSL baselines and PPI methods that tune the interpolation parameter offline.
Calibrated Predictive Lower Bounds on Time-to-Unsafe-Sampling in LLMs
Jun 16, 2025We develop a framework to quantify the time-to-unsafe-sampling - the number of large language model (LLM) generations required to trigger an unsafe (e.g., toxic) response. Estimating this quantity is challenging, since unsafe responses are exceedingly rare in well-aligned LLMs, potentially occurring only once in thousands of generations. As a result, directly estimating time-to-unsafe-sampling would require collecting training data with a prohibitively large number of generations per prompt. However, with realistic sampling budgets, we often cannot generate enough responses to observe an unsafe outcome for every prompt, leaving the time-to-unsafe-sampling unobserved in many cases, making the estimation and evaluation tasks particularly challenging. To address this, we frame this estimation problem as one of survival analysis and develop a provably calibrated lower predictive bound (LPB) on the time-to-unsafe-sampling of a given prompt, leveraging recent advances in conformal prediction. Our key innovation is designing an adaptive, per-prompt sampling strategy, formulated as a convex optimization problem. The objective function guiding this optimized sampling allocation is designed to reduce the variance of the estimators used to construct the LPB, leading to improved statistical efficiency over naive methods that use a fixed sampling budget per prompt. Experiments on both synthetic and real data support our theoretical results and demonstrate the practical utility of our method for safety risk assessment in generative AI models.
Learning a Continue-Thinking Token for Enhanced Test-Time Scaling
Jun 12, 2025Test-time scaling has emerged as an effective approach for improving language model performance by utilizing additional compute at inference time. Recent studies have shown that overriding end-of-thinking tokens (e.g., replacing "</think>" with "Wait") can extend reasoning steps and improve accuracy. In this work, we explore whether a dedicated continue-thinking token can be learned to trigger extended reasoning. We augment a distilled version of DeepSeek-R1 with a single learned "<|continue-thinking|>" token, training only its embedding via reinforcement learning while keeping the model weights frozen. Our experiments show that this learned token achieves improved accuracy on standard math benchmarks compared to both the baseline model and a test-time scaling approach that uses a fixed token (e.g., "Wait") for budget forcing. In particular, we observe that in cases where the fixed-token approach enhances the base model's accuracy, our method achieves a markedly greater improvement. For example, on the GSM8K benchmark, the fixed-token approach yields a 1.3% absolute improvement in accuracy, whereas our learned-token method achieves a 4.2% improvement over the base model that does not use budget forcing.
Synthetic-Powered Predictive Inference
May 19, 2025


Conformal prediction is a framework for predictive inference with a distribution-free, finite-sample guarantee. However, it tends to provide uninformative prediction sets when calibration data are scarce. This paper introduces Synthetic-powered predictive inference (SPPI), a novel framework that incorporates synthetic data -- e.g., from a generative model -- to improve sample efficiency. At the core of our method is a score transporter: an empirical quantile mapping that aligns nonconformity scores from trusted, real data with those from synthetic data. By carefully integrating the score transporter into the calibration process, SPPI provably achieves finite-sample coverage guarantees without making any assumptions about the real and synthetic data distributions. When the score distributions are well aligned, SPPI yields substantially tighter and more informative prediction sets than standard conformal prediction. Experiments on image classification and tabular regression demonstrate notable improvements in predictive efficiency in data-scarce settings.
Conformal Prediction with Corrupted Labels: Uncertain Imputation and Robust Re-weighting
May 07, 2025We introduce a framework for robust uncertainty quantification in situations where labeled training data are corrupted, through noisy or missing labels. We build on conformal prediction, a statistical tool for generating prediction sets that cover the test label with a pre-specified probability. The validity of conformal prediction, however, holds under the i.i.d assumption, which does not hold in our setting due to the corruptions in the data. To account for this distribution shift, the privileged conformal prediction (PCP) method proposed leveraging privileged information (PI) -- additional features available only during training -- to re-weight the data distribution, yielding valid prediction sets under the assumption that the weights are accurate. In this work, we analyze the robustness of PCP to inaccuracies in the weights. Our analysis indicates that PCP can still yield valid uncertainty estimates even when the weights are poorly estimated. Furthermore, we introduce uncertain imputation (UI), a new conformal method that does not rely on weight estimation. Instead, we impute corrupted labels in a way that preserves their uncertainty. Our approach is supported by theoretical guarantees and validated empirically on both synthetic and real benchmarks. Finally, we show that these techniques can be integrated into a triply robust framework, ensuring statistically valid predictions as long as at least one underlying method is valid.
Robust Conformal Outlier Detection under Contaminated Reference Data
Feb 07, 2025Conformal prediction is a flexible framework for calibrating machine learning predictions, providing distribution-free statistical guarantees. In outlier detection, this calibration relies on a reference set of labeled inlier data to control the type-I error rate. However, obtaining a perfectly labeled inlier reference set is often unrealistic, and a more practical scenario involves access to a contaminated reference set containing a small fraction of outliers. This paper analyzes the impact of such contamination on the validity of conformal methods. We prove that under realistic, non-adversarial settings, calibration on contaminated data yields conservative type-I error control, shedding light on the inherent robustness of conformal methods. This conservativeness, however, typically results in a loss of power. To alleviate this limitation, we propose a novel, active data-cleaning framework that leverages a limited labeling budget and an outlier detection model to selectively annotate data points in the contaminated reference set that are suspected as outliers. By removing only the annotated outliers in this ``suspicious'' subset, we can effectively enhance power while mitigating the risk of inflating the type-I error rate, as supported by our theoretical analysis. Experiments on real datasets validate the conservative behavior of conformal methods under contamination and show that the proposed data-cleaning strategy improves power without sacrificing validity.
Segment-Based Attention Masking for GPTs
Dec 24, 2024Modern Language Models (LMs) owe much of their success to masked causal attention, the backbone of Generative Pre-Trained Transformer (GPT) models. Although GPTs can process the entire user prompt at once, the causal masking is applied to all input tokens step-by-step, mimicking the generation process. This imposes an unnecessary constraint during the initial "prefill" phase when the model processes the input prompt and generates the internal representations before producing any output tokens. In this work, attention is masked based on the known block structure at the prefill phase, followed by the conventional token-by-token autoregressive process after that. For example, in a typical chat prompt, the system prompt is treated as one block, and the user prompt as the next one. Each of these is treated as a unit for the purpose of masking, such that the first tokens in each block can access the subsequent tokens in a non-causal manner. Then, the model answer is generated in the conventional causal manner. This Segment-by-Segment scheme entails no additional computational overhead. When integrating it into models such as Llama and Qwen, state-of-the-art performance is consistently achieved.
Semi-Supervised Risk Control via Prediction-Powered Inference
Dec 15, 2024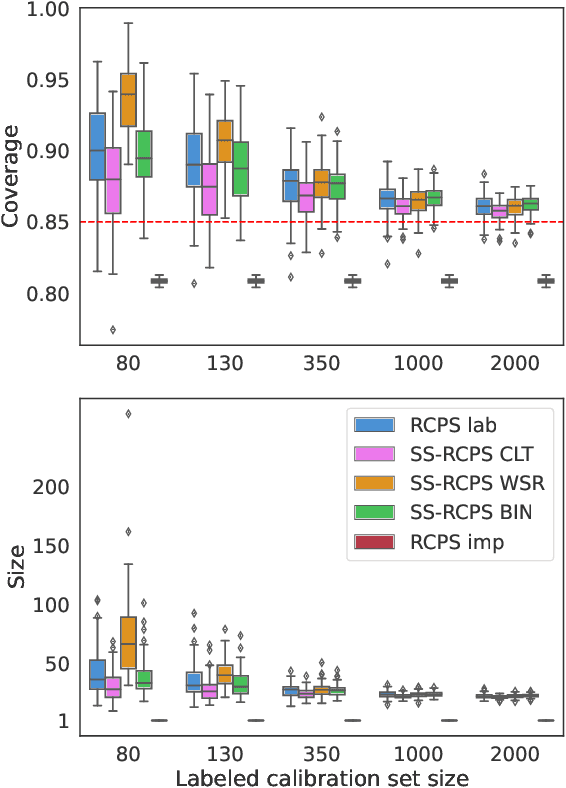
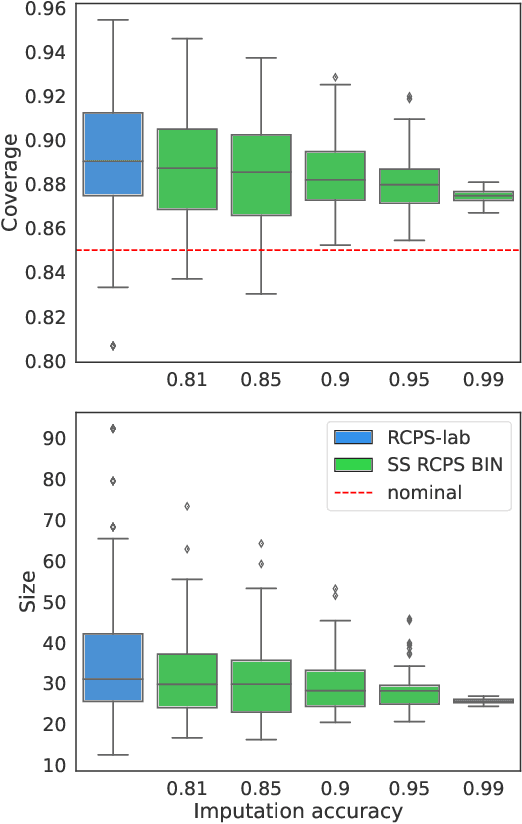
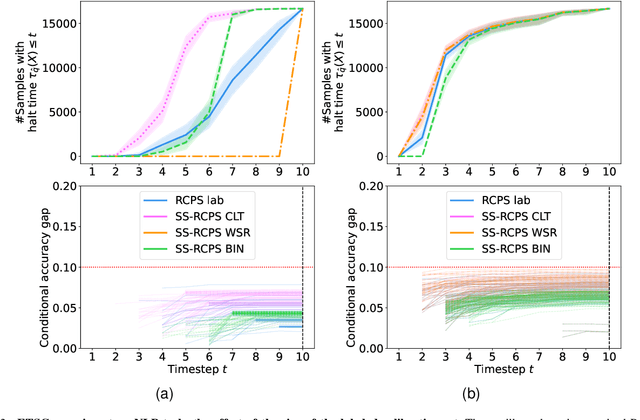
The risk-controlling prediction sets (RCPS) framework is a general tool for transforming the output of any machine learning model to design a predictive rule with rigorous error rate control. The key idea behind this framework is to use labeled hold-out calibration data to tune a hyper-parameter that affects the error rate of the resulting prediction rule. However, the limitation of such a calibration scheme is that with limited hold-out data, the tuned hyper-parameter becomes noisy and leads to a prediction rule with an error rate that is often unnecessarily conservative. To overcome this sample-size barrier, we introduce a semi-supervised calibration procedure that leverages unlabeled data to rigorously tune the hyper-parameter without compromising statistical validity. Our procedure builds upon the prediction-powered inference framework, carefully tailoring it to risk-controlling tasks. We demonstrate the benefits and validity of our proposal through two real-data experiments: few-shot image classification and early time series classification.