 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Field Parallel Decoding for Discrete Diffusion Language Models
Jun 14, 2026Discrete diffusion language models enable parallel token generation, offering a pathway to low-latency decoding. However, selecting tokens independently by marginal confidence limits effective parallelism: tokens that appear reliable in isolation can form incompatible configurations when several positions are updated at once. We introduce a training-free decoding framework that coordinates these parallel updates. At each forward pass, the method assigns a commit score to each masked position and refines these scores using pairwise interactions derived from the model's predictive distributions. A variational relaxation yields a simple fixed-point update that suppresses conflicting simultaneous commitments within a single forward pass. This mechanism allows the decoder to commit more tokens in parallel while maintaining competitive generation quality. The method is lightweight, requires no auxiliary model or retraining, and drops into existing diffusion decoding pipelines without modification. Experiments on reasoning and code-generation benchmarks show consistent improvements in the quality-latency trade-off.
Accelerating Speculative Decoding with Block Diffusion Draft Trees
Apr 14, 2026Speculative decoding accelerates autoregressive language models by using a lightweight drafter to propose multiple future tokens, which the target model then verifies in parallel. DFlash shows that a block diffusion drafter can generate an entire draft block in a single forward pass and achieve state-of-the-art speculative decoding performance, outperforming strong autoregressive drafters such as EAGLE-3. Vanilla DFlash, however, still verifies only a single drafted trajectory per round, potentially limiting its acceptance length. We introduce DDTree (Diffusion Draft Tree), a method that constructs a draft tree directly from the per-position distributions of a block diffusion drafter. Under a fixed node budget, DDTree uses a simple best-first heap algorithm to select the continuations that are most likely to match the target model according to a surrogate defined by the draft model's output. The resulting tree is verified efficiently in a single target model forward pass using an ancestor-only attention mask. Because DDTree builds on DFlash, a leading draft model for speculative decoding, these gains place DDTree among the leading approaches to speculative decoding.
Dependency-Guided Parallel Decoding in Discrete Diffusion Language Models
Apr 02, 2026Discrete diffusion language models (dLLMs) accelerate text generation by unmasking multiple tokens in parallel. However, parallel decoding introduces a distributional mismatch: it approximates the joint conditional using a fully factorized product of per-token marginals, which degrades output quality when selected tokens are strongly dependent. We propose DEMASK (DEpendency-guided unMASKing), a lightweight dependency predictor that attaches to the final hidden states of a dLLM. In a single forward pass, it estimates pairwise conditional influences between masked positions. Using these predictions, a greedy selection algorithm identifies positions with bounded cumulative dependency for simultaneous unmasking. Under a sub-additivity assumption, we prove this bounds the total variation distance between our parallel sampling and the model's joint. Empirically, DEMASK achieves 1.7-2.2$\times$ speedup on Dream-7B while matching or improving accuracy compared to confidence-based and KL-based baselines.
Learning a Continue-Thinking Token for Enhanced Test-Time Scaling
Jun 12, 2025Test-time scaling has emerged as an effective approach for improving language model performance by utilizing additional compute at inference time. Recent studies have shown that overriding end-of-thinking tokens (e.g., replacing "</think>" with "Wait") can extend reasoning steps and improve accuracy. In this work, we explore whether a dedicated continue-thinking token can be learned to trigger extended reasoning. We augment a distilled version of DeepSeek-R1 with a single learned "<|continue-thinking|>" token, training only its embedding via reinforcement learning while keeping the model weights frozen. Our experiments show that this learned token achieves improved accuracy on standard math benchmarks compared to both the baseline model and a test-time scaling approach that uses a fixed token (e.g., "Wait") for budget forcing. In particular, we observe that in cases where the fixed-token approach enhances the base model's accuracy, our method achieves a markedly greater improvement. For example, on the GSM8K benchmark, the fixed-token approach yields a 1.3% absolute improvement in accuracy, whereas our learned-token method achieves a 4.2% improvement over the base model that does not use budget forcing.
Segment-Based Attention Masking for GPTs
Dec 24, 2024Modern Language Models (LMs) owe much of their success to masked causal attention, the backbone of Generative Pre-Trained Transformer (GPT) models. Although GPTs can process the entire user prompt at once, the causal masking is applied to all input tokens step-by-step, mimicking the generation process. This imposes an unnecessary constraint during the initial "prefill" phase when the model processes the input prompt and generates the internal representations before producing any output tokens. In this work, attention is masked based on the known block structure at the prefill phase, followed by the conventional token-by-token autoregressive process after that. For example, in a typical chat prompt, the system prompt is treated as one block, and the user prompt as the next one. Each of these is treated as a unit for the purpose of masking, such that the first tokens in each block can access the subsequent tokens in a non-causal manner. Then, the model answer is generated in the conventional causal manner. This Segment-by-Segment scheme entails no additional computational overhead. When integrating it into models such as Llama and Qwen, state-of-the-art performance is consistently achieved.
Semi-Supervised Risk Control via Prediction-Powered Inference
Dec 15, 2024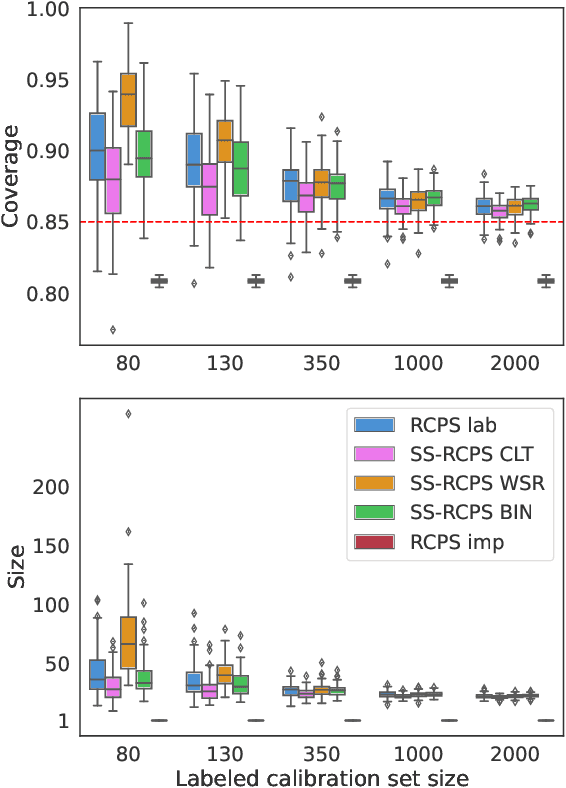
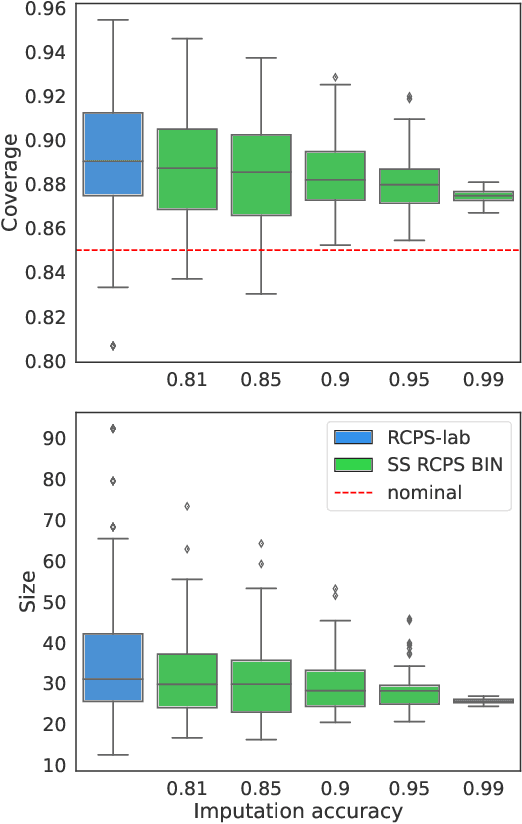
The risk-controlling prediction sets (RCPS) framework is a general tool for transforming the output of any machine learning model to design a predictive rule with rigorous error rate control. The key idea behind this framework is to use labeled hold-out calibration data to tune a hyper-parameter that affects the error rate of the resulting prediction rule. However, the limitation of such a calibration scheme is that with limited hold-out data, the tuned hyper-parameter becomes noisy and leads to a prediction rule with an error rate that is often unnecessarily conservative. To overcome this sample-size barrier, we introduce a semi-supervised calibration procedure that leverages unlabeled data to rigorously tune the hyper-parameter without compromising statistical validity. Our procedure builds upon the prediction-powered inference framework, carefully tailoring it to risk-controlling tasks. We demonstrate the benefits and validity of our proposal through two real-data experiments: few-shot image classification and early time series classification.
Early Time Classification with Accumulated Accuracy Gap Control
Feb 01, 2024
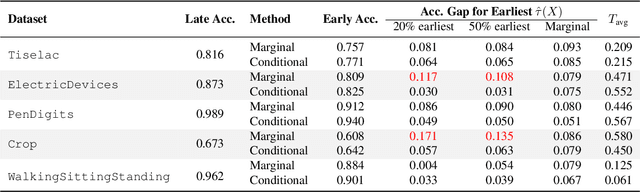
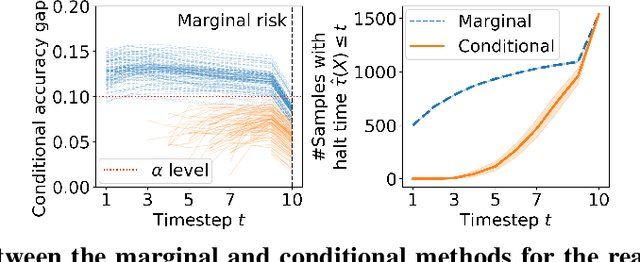
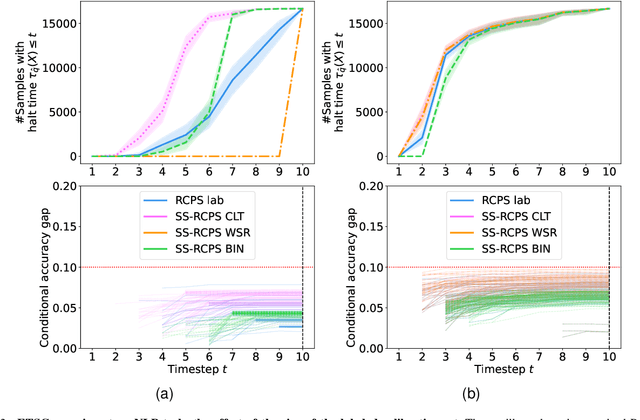
Early time classification algorithms aim to label a stream of features without processing the full input stream, while maintaining accuracy comparable to that achieved by applying the classifier to the entire input. In this paper, we introduce a statistical framework that can be applied to any sequential classifier, formulating a calibrated stopping rule. This data-driven rule attains finite-sample, distribution-free control of the accuracy gap between full and early-time classification. We start by presenting a novel method that builds on the Learn-then-Test calibration framework to control this gap marginally, on average over i.i.d. instances. As this algorithm tends to yield an excessively high accuracy gap for early halt times, our main contribution is the proposal of a framework that controls a stronger notion of error, where the accuracy gap is controlled conditionally on the accumulated halt times. Numerical experiments demonstrate the effectiveness, applicability, and usefulness of our method. We show that our proposed early stopping mechanism reduces up to 94% of timesteps used for classification while achieving rigorous accuracy gap control.