 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting For Distribution Shifts with Conditional Conformal Test Martingales
Feb 14, 2026We propose a sequential test for detecting arbitrary distribution shifts that allows conformal test martingales (CTMs) to work under a fixed, reference-conditional setting. Existing CTM detectors construct test martingales by continually growing a reference set with each incoming sample, using it to assess how atypical the new sample is relative to past observations. While this design yields anytime-valid type-I error control, it suffers from test-time contamination: after a change, post-shift observations enter the reference set and dilute the evidence for distribution shift, increasing detection delay and reducing power. In contrast, our method avoids contamination by design by comparing each new sample to a fixed null reference dataset. Our main technical contribution is a robust martingale construction that remains valid conditional on the null reference data, achieved by explicitly accounting for the estimation error in the reference distribution induced by the finite reference set. This yields anytime-valid type-I error control together with guarantees of asymptotic power one and bounded expected detection delay. Empirically, our method detects shifts faster than standard CTMs, providing a powerful and reliable distribution-shift detector.
Prediction-Powered Semi-Supervised Learning with Online Power Tuning
Oct 26, 2025



Prediction-Powered Inference (PPI) is a recently proposed statistical inference technique for parameter estimation that leverages pseudo-labels on both labeled and unlabeled data to construct an unbiased, low-variance estimator. In this work, we extend its core idea to semi-supervised learning (SSL) for model training, introducing a novel unbiased gradient estimator. This extension addresses a key challenge in SSL: while unlabeled data can improve model performance, its benefit heavily depends on the quality of pseudo-labels. Inaccurate pseudo-labels can introduce bias, leading to suboptimal models.To balance the contributions of labeled and pseudo-labeled data, we utilize an interpolation parameter and tune it on the fly, alongside the model parameters, using a one-dimensional online learning algorithm. We verify the practical advantage of our approach through experiments on both synthetic and real datasets, demonstrating improved performance over classic SSL baselines and PPI methods that tune the interpolation parameter offline.
Summary of the NOTSOFAR-1 Challenge: Highlights and Learnings
Jan 28, 2025



The first Natural Office Talkers in Settings of Far-field Audio Recordings (NOTSOFAR-1) Challenge is a pivotal initiative that sets new benchmarks by offering datasets more representative of the needs of real-world business applications than those previously available. The challenge provides a unique combination of 280 recorded meetings across 30 diverse environments, capturing real-world acoustic conditions and conversational dynamics, and a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. In this paper, we provide an overview of the systems submitted to the challenge and analyze the top-performing approaches, hypothesizing the factors behind their success. Additionally, we highlight promising directions left unexplored by participants. By presenting key findings and actionable insights, this work aims to drive further innovation and progress in DASR research and applications.
Protected Test-Time Adaptation via Online Entropy Matching: A Betting Approach
Aug 14, 2024We present a novel approach for test-time adaptation via online self-training, consisting of two components. First, we introduce a statistical framework that detects distribution shifts in the classifier's entropy values obtained on a stream of unlabeled samples. Second, we devise an online adaptation mechanism that utilizes the evidence of distribution shifts captured by the detection tool to dynamically update the classifier's parameters. The resulting adaptation process drives the distribution of test entropy values obtained from the self-trained classifier to match those of the source domain, building invariance to distribution shifts. This approach departs from the conventional self-training method, which focuses on minimizing the classifier's entropy. Our approach combines concepts in betting martingales and online learning to form a detection tool capable of quickly reacting to distribution shifts. We then reveal a tight relation between our adaptation scheme and optimal transport, which forms the basis of our novel self-supervised loss. Experimental results demonstrate that our approach improves test-time accuracy under distribution shifts while maintaining accuracy and calibration in their absence, outperforming leading entropy minimization methods across various scenarios.
NOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024

We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
Model-Free Sequential Testing for Conditional Independence via Testing by Betting
Oct 01, 2022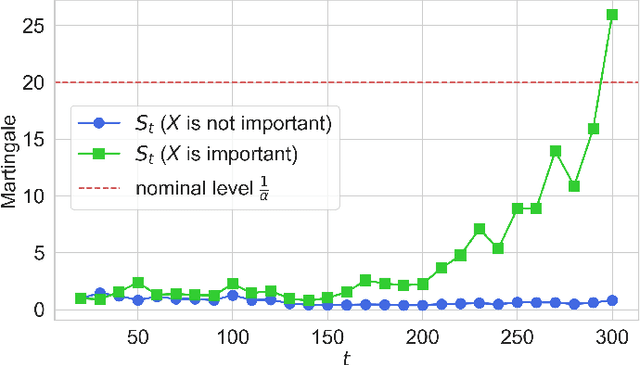
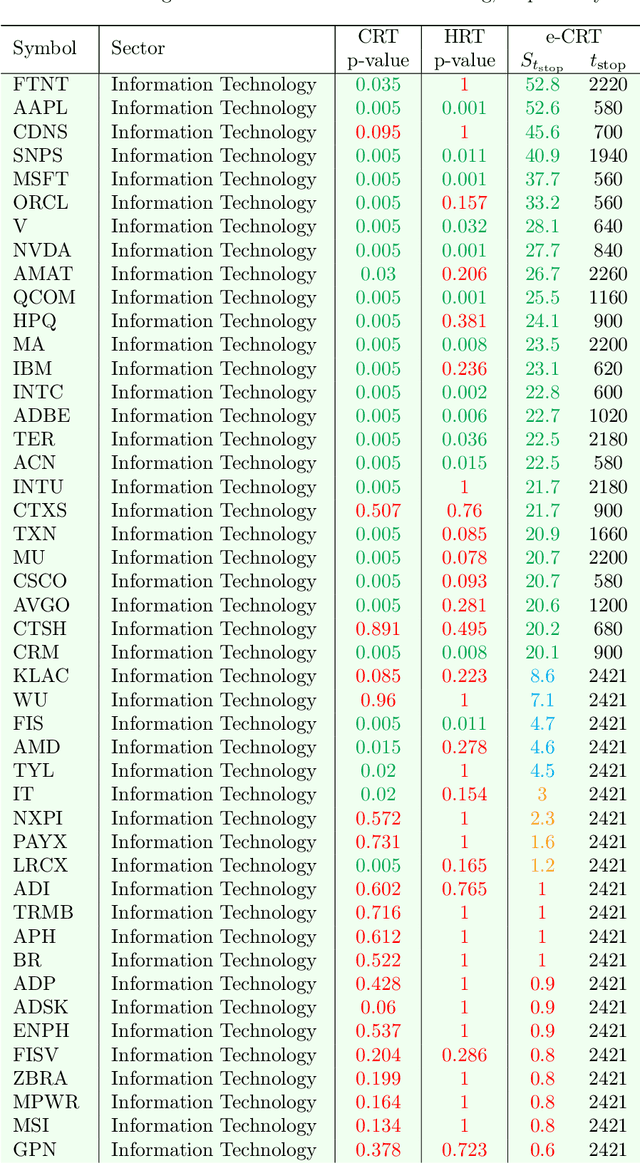


This paper develops a model-free sequential test for conditional independence. The proposed test allows researchers to analyze an incoming i.i.d. data stream with any arbitrary dependency structure, and safely conclude whether a feature is conditionally associated with the response under study. We allow the processing of data points online as soon as they arrive and stop data acquisition once significant results are detected while rigorously controlling the type-I error rate. Our test can work with any sophisticated machine learning algorithm to enhance data efficiency to the extent possible. The developed method is inspired by two statistical frameworks. The first is the model-X conditional randomization test, a test for conditional independence that is valid in offline settings where the sample size is fixed in advance. The second is testing by betting, a "game-theoretic" approach for sequential hypothesis testing. We conduct synthetic experiments to demonstrate the advantage of our test over out-of-the-box sequential tests that account for the multiplicity of tests in the time horizon, and demonstrate the practicality of our proposal by applying it to real-world tasks.
Learning to Increase the Power of Conditional Randomization Tests
Jul 03, 2022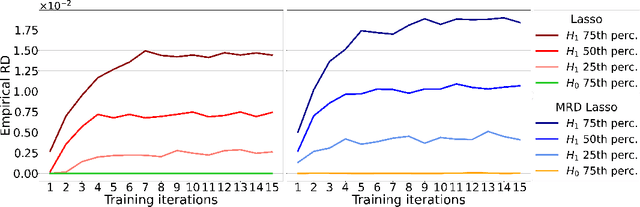
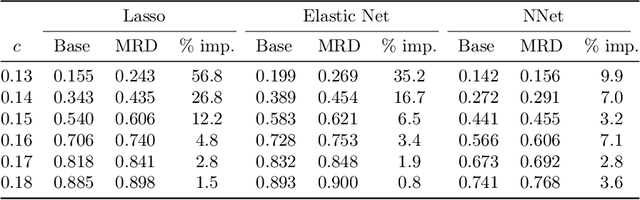
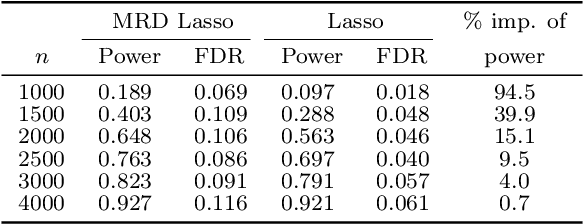
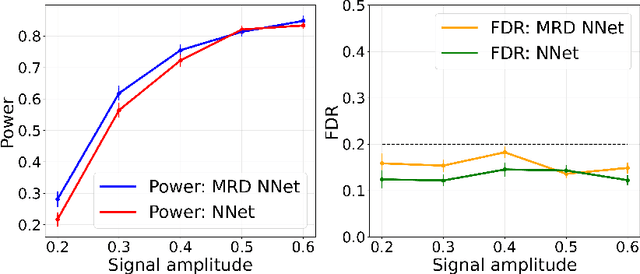
The model-X conditional randomization test is a generic framework for conditional independence testing, unlocking new possibilities to discover features that are conditionally associated with a response of interest while controlling type-I error rates. An appealing advantage of this test is that it can work with any machine learning model to design powerful test statistics. In turn, the common practice in the model-X literature is to form a test statistic using machine learning models, trained to maximize predictive accuracy with the hope to attain a test with good power. However, the ideal goal here is to drive the model (during training) to maximize the power of the test, not merely the predictive accuracy. In this paper, we bridge this gap by introducing, for the first time, novel model-fitting schemes that are designed to explicitly improve the power of model-X tests. This is done by introducing a new cost function that aims at maximizing the test statistic used to measure violations of conditional independence. Using synthetic and real data sets, we demonstrate that the combination of our proposed loss function with various base predictive models (lasso, elastic net, and deep neural networks) consistently increases the number of correct discoveries obtained, while maintaining type-I error rates under control.