 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Increase the Power of Conditional Randomization Tests
Paper and Code
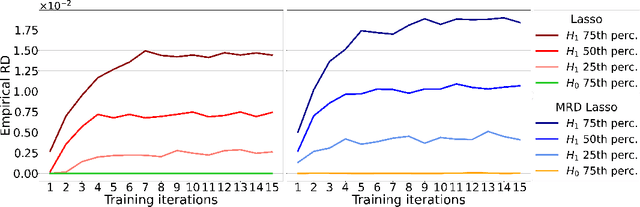
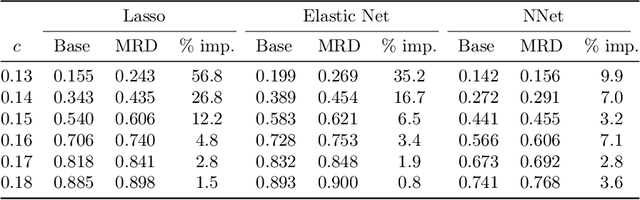
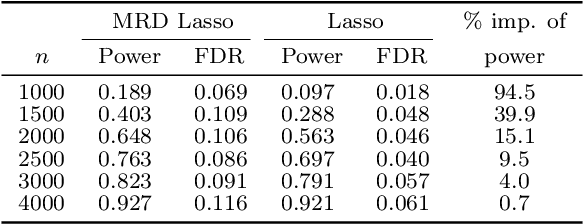
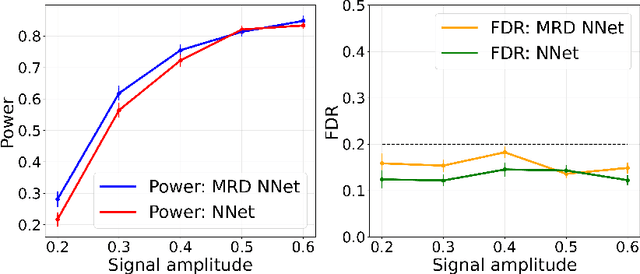
The model-X conditional randomization test is a generic framework for conditional independence testing, unlocking new possibilities to discover features that are conditionally associated with a response of interest while controlling type-I error rates. An appealing advantage of this test is that it can work with any machine learning model to design powerful test statistics. In turn, the common practice in the model-X literature is to form a test statistic using machine learning models, trained to maximize predictive accuracy with the hope to attain a test with good power. However, the ideal goal here is to drive the model (during training) to maximize the power of the test, not merely the predictive accuracy. In this paper, we bridge this gap by introducing, for the first time, novel model-fitting schemes that are designed to explicitly improve the power of model-X tests. This is done by introducing a new cost function that aims at maximizing the test statistic used to measure violations of conditional independence. Using synthetic and real data sets, we demonstrate that the combination of our proposed loss function with various base predictive models (lasso, elastic net, and deep neural networks) consistently increases the number of correct discoveries obtained, while maintaining type-I error rates under control.