 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal MixVR: Breaking the Communication-Sample Dependence in Distributed Learning
May 31, 2026Communication overhead is a crucial bottleneck in scalable distributed learning. While existing methods aim to efficiently utilize data points, such as Local SGD, Minibatch SGD, and their accelerated variants, they still exhibit communication-round complexity that scales with the total number of samples $N$. In this paper, we introduce Local MixVR, a distributed framework that integrates local updates with variance-reduction techniques to mitigate local noise. We show that Local MixVR is the first distributed method to eliminate the dependence of communication complexity on $N$, achieving a complexity that scales only with the number of workers $M$. In common regimes where $M<O\left(N^{1/4}\right)$, Local MixVR outperforms the state-of-the-art Minibatch Accelerated SGD baseline, bridging a long-standing gap in distributed optimization and establishing a new paradigm for communication-efficient training.
Bringing Order to Asynchronous SGD: Towards Optimality under Data-Dependent Delays with Momentum
May 03, 2026Asynchronous stochastic gradient descent (SGD) enables scalable distributed training but suffers from gradient staleness. Existing mitigation strategies, such as delay-adaptive learning rates and staleness-aware filtering, typically attenuate or discard delayed gradients, introducing systematic bias: updates from simpler or faster-to-process samples are overrepresented, while gradients from more complex samples are delayed or suppressed. In contrast, prior approaches to data-dependent delays rely on a Lipschitz assumption that yields suboptimal rates or leave the smooth, convex case unaddressed. We propose a momentum-based asynchronous framework designed to preserve information from delayed gradients while mitigating the effects of staleness. We establish the first optimal convergence rates for data-dependent delays in both convex and non-convex smooth setups, providing a new result for asynchronous optimization under standard assumptions. Additionally, we derive robust learning-rate schedules that simplify hyperparameter tuning in practice.
Prediction-Powered Semi-Supervised Learning with Online Power Tuning
Oct 26, 2025



Prediction-Powered Inference (PPI) is a recently proposed statistical inference technique for parameter estimation that leverages pseudo-labels on both labeled and unlabeled data to construct an unbiased, low-variance estimator. In this work, we extend its core idea to semi-supervised learning (SSL) for model training, introducing a novel unbiased gradient estimator. This extension addresses a key challenge in SSL: while unlabeled data can improve model performance, its benefit heavily depends on the quality of pseudo-labels. Inaccurate pseudo-labels can introduce bias, leading to suboptimal models.To balance the contributions of labeled and pseudo-labeled data, we utilize an interpolation parameter and tune it on the fly, alongside the model parameters, using a one-dimensional online learning algorithm. We verify the practical advantage of our approach through experiments on both synthetic and real datasets, demonstrating improved performance over classic SSL baselines and PPI methods that tune the interpolation parameter offline.
Safety in the Face of Adversity: Achieving Zero Constraint Violation in Online Learning with Slowly Changing Constraints
May 01, 2025We present the first theoretical guarantees for zero constraint violation in Online Convex Optimization (OCO) across all rounds, addressing dynamic constraint changes. Unlike existing approaches in constrained OCO, which allow for occasional safety breaches, we provide the first approach for maintaining strict safety under the assumption of gradually evolving constraints, namely the constraints change at most by a small amount between consecutive rounds. This is achieved through a primal-dual approach and Online Gradient Ascent in the dual space. We show that employing a dichotomous learning rate enables ensuring both safety, via zero constraint violation, and sublinear regret. Our framework marks a departure from previous work by providing the first provable guarantees for maintaining absolute safety in the face of changing constraints in OCO.
DE-PADA: Personalized Augmentation and Domain Adaptation for ECG Biometrics Across Physiological States
Feb 07, 2025Electrocardiogram (ECG)-based biometrics offer a promising method for user identification, combining intrinsic liveness detection with morphological uniqueness. However, elevated heart rates introduce significant physiological variability, posing challenges to pattern recognition systems and leading to a notable performance gap between resting and post-exercise conditions. Addressing this gap is critical for advancing ECG-based biometric systems for real-world applications. We propose DE-PADA, a Dual Expert model with Personalized Augmentation and Domain Adaptation, designed to enhance robustness across diverse physiological states. The model is trained primarily on resting-state data from the evaluation dataset, without direct exposure to their exercise data. To address variability, DE-PADA incorporates ECG-specific innovations, including heartbeat segmentation into the PQRS interval, known for its relative temporal consistency, and the heart rate-sensitive ST interval, enabling targeted feature extraction tailored to each region's unique characteristics. Personalized augmentation simulates subject-specific T-wave variability across heart rates using individual T-wave peak predictions to adapt augmentation ranges. Domain adaptation further improves generalization by leveraging auxiliary data from supplementary subjects used exclusively for training, including both resting and exercise conditions. Experiments on the University of Toronto ECG Database demonstrate the model's effectiveness. DE-PADA achieves relative improvements in post-exercise identification rates of 26.75% in the initial recovery phase and 11.72% in the late recovery phase, while maintaining a 98.12% identification rate in the sitting position. These results highlight DE-PADA's ability to address intra-subject variability and enhance the robustness of ECG-based biometric systems across diverse physiological states.
Weight for Robustness: A Comprehensive Approach towards Optimal Fault-Tolerant Asynchronous ML
Jan 16, 2025



We address the challenges of Byzantine-robust training in asynchronous distributed machine learning systems, aiming to enhance efficiency amid massive parallelization and heterogeneous computing resources. Asynchronous systems, marked by independently operating workers and intermittent updates, uniquely struggle with maintaining integrity against Byzantine failures, which encompass malicious or erroneous actions that disrupt learning. The inherent delays in such settings not only introduce additional bias to the system but also obscure the disruptions caused by Byzantine faults. To tackle these issues, we adapt the Byzantine framework to asynchronous dynamics by introducing a novel weighted robust aggregation framework. This allows for the extension of robust aggregators and a recent meta-aggregator to their weighted versions, mitigating the effects of delayed updates. By further incorporating a recent variance-reduction technique, we achieve an optimal convergence rate for the first time in an asynchronous Byzantine environment. Our methodology is rigorously validated through empirical and theoretical analysis, demonstrating its effectiveness in enhancing fault tolerance and optimizing performance in asynchronous ML systems.
Private and Federated Stochastic Convex Optimization: Efficient Strategies for Centralized Systems
Jul 17, 2024

This paper addresses the challenge of preserving privacy in Federated Learning (FL) within centralized systems, focusing on both trusted and untrusted server scenarios. We analyze this setting within the Stochastic Convex Optimization (SCO) framework, and devise methods that ensure Differential Privacy (DP) while maintaining optimal convergence rates for homogeneous and heterogeneous data distributions. Our approach, based on a recent stochastic optimization technique, offers linear computational complexity, comparable to non-private FL methods, and reduced gradient obfuscation. This work enhances the practicality of DP in FL, balancing privacy, efficiency, and robustness in a variety of server trust environment.
Fault Tolerant ML: Efficient Meta-Aggregation and Synchronous Training
May 23, 2024In this paper, we investigate the challenging framework of Byzantine-robust training in distributed machine learning (ML) systems, focusing on enhancing both efficiency and practicality. As distributed ML systems become integral for complex ML tasks, ensuring resilience against Byzantine failures-where workers may contribute incorrect updates due to malice or error-gains paramount importance. Our first contribution is the introduction of the Centered Trimmed Meta Aggregator (CTMA), an efficient meta-aggregator that upgrades baseline aggregators to optimal performance levels, while requiring low computational demands. Additionally, we propose harnessing a recently developed gradient estimation technique based on a double-momentum strategy within the Byzantine context. Our paper highlights its theoretical and practical advantages for Byzantine-robust training, especially in simplifying the tuning process and reducing the reliance on numerous hyperparameters. The effectiveness of this technique is supported by theoretical insights within the stochastic convex optimization (SCO) framework.
On the Global Convergence of Policy Gradient in Average Reward Markov Decision Processes
Mar 11, 2024



We present the first finite time global convergence analysis of policy gradient in the context of infinite horizon average reward Markov decision processes (MDPs). Specifically, we focus on ergodic tabular MDPs with finite state and action spaces. Our analysis shows that the policy gradient iterates converge to the optimal policy at a sublinear rate of $O\left({\frac{1}{T}}\right),$ which translates to $O\left({\log(T)}\right)$ regret, where $T$ represents the number of iterations. Prior work on performance bounds for discounted reward MDPs cannot be extended to average reward MDPs because the bounds grow proportional to the fifth power of the effective horizon. Thus, our primary contribution is in proving that the policy gradient algorithm converges for average-reward MDPs and in obtaining finite-time performance guarantees. In contrast to the existing discounted reward performance bounds, our performance bounds have an explicit dependence on constants that capture the complexity of the underlying MDP. Motivated by this observation, we reexamine and improve the existing performance bounds for discounted reward MDPs. We also present simulations to empirically evaluate the performance of average reward policy gradient algorithm.
Dynamic Byzantine-Robust Learning: Adapting to Switching Byzantine Workers
Feb 05, 2024
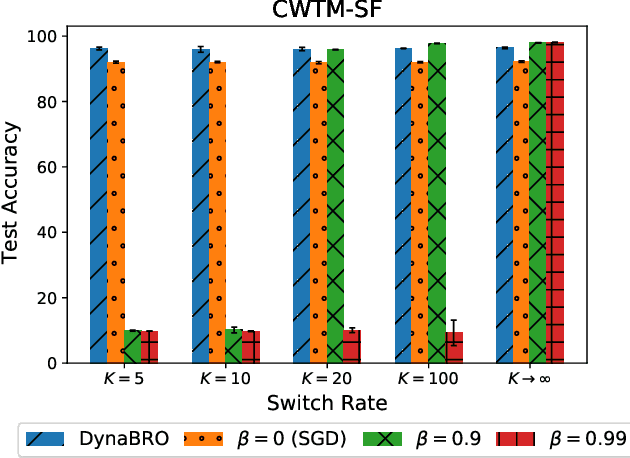
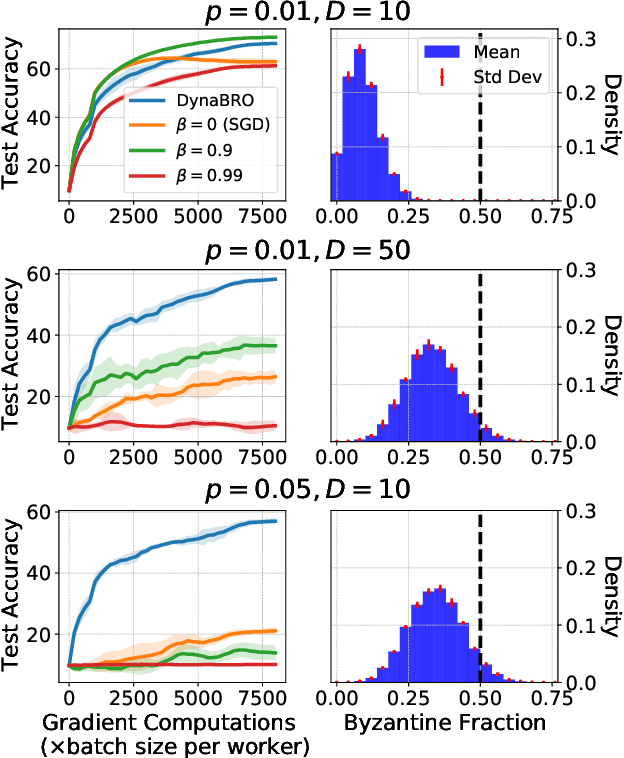
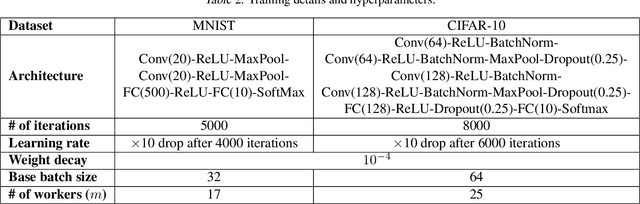
Byzantine-robust learning has emerged as a prominent fault-tolerant distributed machine learning framework. However, most techniques consider the static setting, wherein the identity of Byzantine machines remains fixed during the learning process. This assumption does not capture real-world dynamic Byzantine behaviors, which may include transient malfunctions or targeted temporal attacks. Addressing this limitation, we propose $\textsf{DynaBRO}$ -- a new method capable of withstanding $\mathcal{O}(\sqrt{T})$ rounds of Byzantine identity alterations (where $T$ is the total number of training rounds), while matching the asymptotic convergence rate of the static setting. Our method combines a multi-level Monte Carlo (MLMC) gradient estimation technique with robust aggregation of worker updates and incorporates a fail-safe filter to limit bias from dynamic Byzantine strategies. Additionally, by leveraging an adaptive learning rate, our approach eliminates the need for knowing the percentage of Byzantine workers.