 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Development of Task-Oriented Communication in Vision-Language Models
Jan 28, 2026We investigate whether \emph{LLM-based agents} can develop task-oriented communication protocols that differ from standard natural language in collaborative reasoning tasks. Our focus is on two core properties such task-oriented protocols may exhibit: Efficiency -- conveying task-relevant information more concisely than natural language, and Covertness -- becoming difficult for external observers to interpret, raising concerns about transparency and control. To investigate these aspects, we use a referential-game framework in which vision-language model (VLM) agents communicate, providing a controlled, measurable setting for evaluating language variants. Experiments show that VLMs can develop effective, task-adapted communication patterns. At the same time, they can develop covert protocols that are difficult for humans and external agents to interpret. We also observe spontaneous coordination between similar models without explicitly shared protocols. These findings highlight both the potential and the risks of task-oriented communication, and position referential games as a valuable testbed for future work in this area.
Optimal L2 Regularization in High-dimensional Continual Linear Regression
Jan 20, 2026We study generalization in an overparameterized continual linear regression setting, where a model is trained with L2 (isotropic) regularization across a sequence of tasks. We derive a closed-form expression for the expected generalization loss in the high-dimensional regime that holds for arbitrary linear teachers. We demonstrate that isotropic regularization mitigates label noise under both single-teacher and multiple i.i.d. teacher settings, whereas prior work accommodating multiple teachers either did not employ regularization or used memory-demanding methods. Furthermore, we prove that the optimal fixed regularization strength scales nearly linearly with the number of tasks $T$, specifically as $T/\ln T$. To our knowledge, this is the first such result in theoretical continual learning. Finally, we validate our theoretical findings through experiments on linear regression and neural networks, illustrating how this scaling law affects generalization and offering a practical recipe for the design of continual learning systems.
CtD: Composition through Decomposition in Emergent Communication
Jan 15, 2026Compositionality is a cognitive mechanism that allows humans to systematically combine known concepts in novel ways. This study demonstrates how artificial neural agents acquire and utilize compositional generalization to describe previously unseen images. Our method, termed "Composition through Decomposition", involves two sequential training steps. In the 'Decompose' step, the agents learn to decompose an image into basic concepts using a codebook acquired during interaction in a multi-target coordination game. Subsequently, in the 'Compose' step, the agents employ this codebook to describe novel images by composing basic concepts into complex phrases. Remarkably, we observe cases where generalization in the `Compose' step is achieved zero-shot, without the need for additional training.
Unsupervised Feature Selection Through Group Discovery
Nov 12, 2025Unsupervised feature selection (FS) is essential for high-dimensional learning tasks where labels are not available. It helps reduce noise, improve generalization, and enhance interpretability. However, most existing unsupervised FS methods evaluate features in isolation, even though informative signals often emerge from groups of related features. For example, adjacent pixels, functionally connected brain regions, or correlated financial indicators tend to act together, making independent evaluation suboptimal. Although some methods attempt to capture group structure, they typically rely on predefined partitions or label supervision, limiting their applicability. We propose GroupFS, an end-to-end, fully differentiable framework that jointly discovers latent feature groups and selects the most informative groups among them, without relying on fixed a priori groups or label supervision. GroupFS enforces Laplacian smoothness on both feature and sample graphs and applies a group sparsity regularizer to learn a compact, structured representation. Across nine benchmarks spanning images, tabular data, and biological datasets, GroupFS consistently outperforms state-of-the-art unsupervised FS in clustering and selects groups of features that align with meaningful patterns.
Unsupervised Invariant Risk Minimization
May 18, 2025We propose a novel unsupervised framework for \emph{Invariant Risk Minimization} (IRM), extending the concept of invariance to settings where labels are unavailable. Traditional IRM methods rely on labeled data to learn representations that are robust to distributional shifts across environments. In contrast, our approach redefines invariance through feature distribution alignment, enabling robust representation learning from unlabeled data. We introduce two methods within this framework: Principal Invariant Component Analysis (PICA), a linear method that extracts invariant directions under Gaussian assumptions, and Variational Invariant Autoencoder (VIAE), a deep generative model that disentangles environment-invariant and environment-dependent latent factors. Our approach is based on a novel ``unsupervised'' structural causal model and supports environment-conditioned sample-generation and intervention. Empirical evaluations on synthetic dataset and modified versions of MNIST demonstrate the effectiveness of our methods in capturing invariant structure, preserving relevant information, and generalizing across environments without access to labels.
Unsupervised Translation of Emergent Communication
Feb 11, 2025Emergent Communication (EC) provides a unique window into the language systems that emerge autonomously when agents are trained to jointly achieve shared goals. However, it is difficult to interpret EC and evaluate its relationship with natural languages (NL). This study employs unsupervised neural machine translation (UNMT) techniques to decipher ECs formed during referential games with varying task complexities, influenced by the semantic diversity of the environment. Our findings demonstrate UNMT's potential to translate EC, illustrating that task complexity characterized by semantic diversity enhances EC translatability, while higher task complexity with constrained semantic variability exhibits pragmatic EC, which, although challenging to interpret, remains suitable for translation. This research marks the first attempt, to our knowledge, to translate EC without the aid of parallel data.
Data-dependent and Oracle Bounds on Forgetting in Continual Learning
Jun 13, 2024
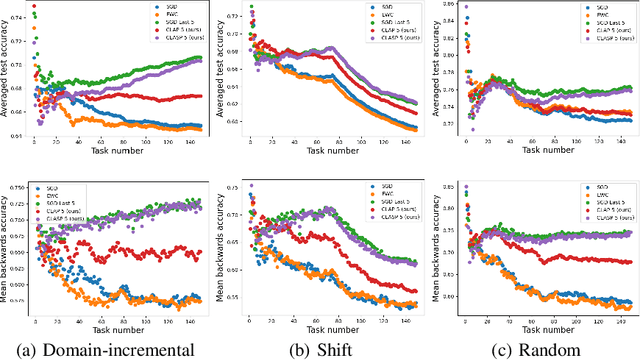
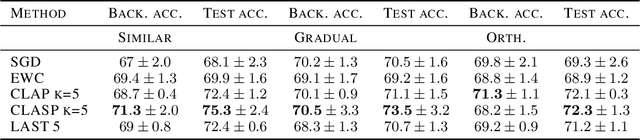
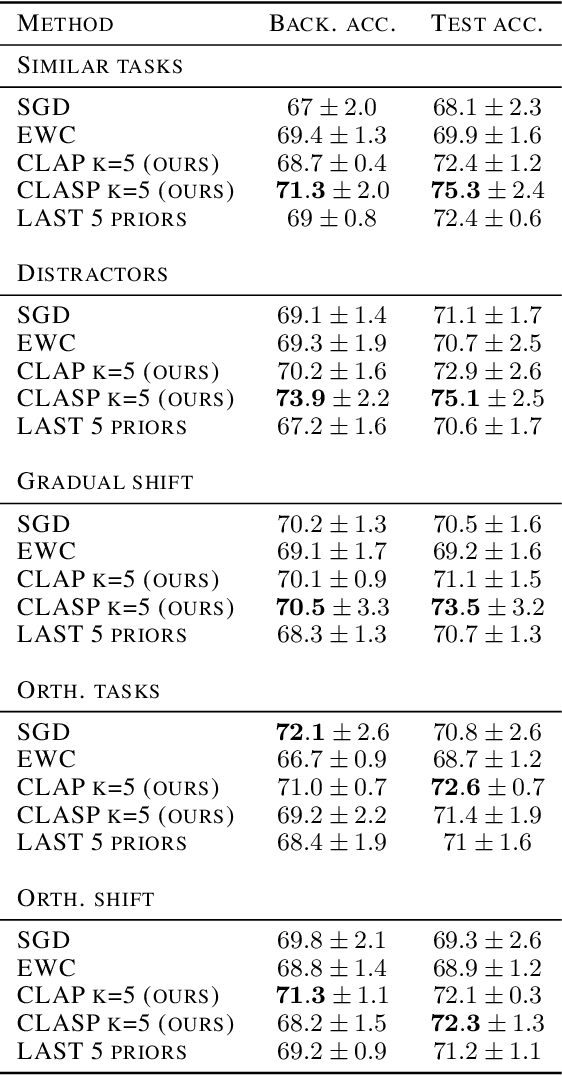
In continual learning, knowledge must be preserved and re-used between tasks, maintaining good transfer to future tasks and minimizing forgetting of previously learned ones. While several practical algorithms have been devised for this setting, there have been few theoretical works aiming to quantify and bound the degree of Forgetting in general settings. We provide both data-dependent and oracle upper bounds that apply regardless of model and algorithm choice, as well as bounds for Gibbs posteriors. We derive an algorithm inspired by our bounds and demonstrate empirically that our approach yields improved forward and backward transfer.
Analysis of the Identifying Regulation with Adversarial Surrogates Algorithm
May 05, 2024Given a time-series of noisy measured outputs of a dynamical system z[k], k=1...N, the Identifying Regulation with Adversarial Surrogates (IRAS) algorithm aims to find a non-trivial first integral of the system, namely, a scalar function g() such that g(z[i]) = g(z[j]), for all i,j. IRAS has been suggested recently and was used successfully in several learning tasks in models from biology and physics. Here, we give the first rigorous analysis of this algorithm in a specific setting. We assume that the observations admit a linear first integral and that they are contaminated by Gaussian noise. We show that in this case the IRAS iterations are closely related to the self-consistent-field (SCF) iterations for solving a generalized Rayleigh quotient minimization problem. Using this approach, we derive several sufficient conditions guaranteeing local convergence of IRAS to the correct first integral.
Concept-Best-Matching: Evaluating Compositionality in Emergent Communication
Mar 17, 2024Artificial agents that learn to communicate in order to accomplish a given task acquire communication protocols that are typically opaque to a human. A large body of work has attempted to evaluate the emergent communication via various evaluation measures, with \emph{compositionality} featuring as a prominent desired trait. However, current evaluation procedures do not directly expose the compositionality of the emergent communication. We propose a procedure to assess the compositionality of emergent communication by finding the best-match between emerged words and natural language concepts. The best-match algorithm provides both a global score and a translation-map from emergent words to natural language concepts. To the best of our knowledge, it is the first time that such direct and interpretable mapping between emergent words and human concepts is provided.
Statistical curriculum learning: An elimination algorithm achieving an oracle risk
Feb 20, 2024



We consider a statistical version of curriculum learning (CL) in a parametric prediction setting. The learner is required to estimate a target parameter vector, and can adaptively collect samples from either the target model, or other source models that are similar to the target model, but less noisy. We consider three types of learners, depending on the level of side-information they receive. The first two, referred to as strong/weak-oracle learners, receive high/low degrees of information about the models, and use these to learn. The third, a fully adaptive learner, estimates the target parameter vector without any prior information. In the single source case, we propose an elimination learning method, whose risk matches that of a strong-oracle learner. In the multiple source case, we advocate that the risk of the weak-oracle learner is a realistic benchmark for the risk of adaptive learners. We develop an adaptive multiple elimination-rounds CL algorithm, and characterize instance-dependent conditions for its risk to match that of the weak-oracle learner. We consider instance-dependent minimax lower bounds, and discuss the challenges associated with defining the class of instances for the bound. We derive two minimax lower bounds, and determine the conditions under which the performance weak-oracle learner is minimax optimal.